课堂笔记
Models
串行过程中处理器上同一时间只有一个线程访问内存里的对象
并发有延迟,程序员不知道哪个在做哪个不在做。

Algorithms
1. print primes

这样会让每个核的工作量不平均,因为数字越大素数越少
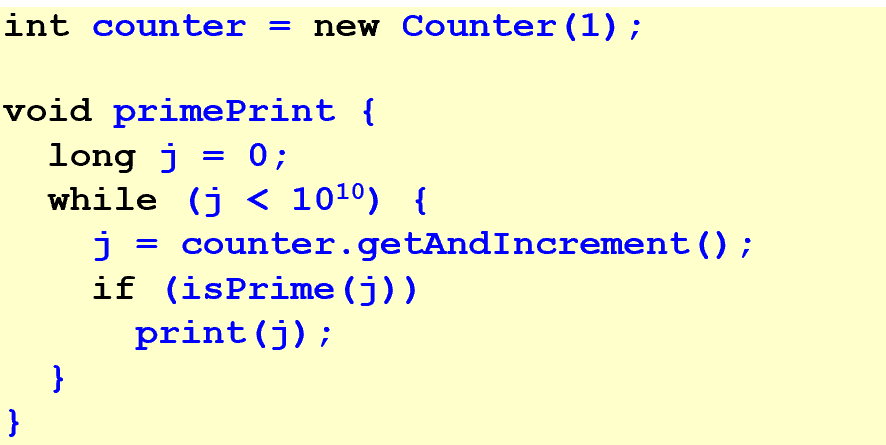
这样动态均衡就很好,counter是共享内存中的对象(应该写Counter counter而不是int counter)

在并发中,不能这样实现Counter,读和写可能会被分成两步导致出错
- 用ReadModifyWrite()
- Java中用synchronized block让这段代码在临界区,可以互斥执行
2. Alice&Bob

程序的两大类性质:
liveness:比如终止性,如果不成立,绝不可能在有限步内发现这个事情
safety:如果不成立,可以在有限步内发现的

互斥:可以在有限步内发现,因为不成立时两个都进去,可以发现
没有死锁:不知道宠物什么时候进湖,类比终止性
协议设计:
- Simple Protocol:不行,线程之间一定要有显性的交换方式
- Call Phone Protocol:信息传递不行,接收方可能不在。交流应该是永久性的、不是转瞬即逝的
- Can Protocol:发中断的方案,需要无穷多个中断位
- Flag Protocol:表达自己的意向并看对方的意向,后面的人可以看到前面的情况。可以用反证法证明满足Mutual Exclusion和No Deadlock。

这个算法不平等,容易饿死。然后需要等待(可能升旗后线程再也不执行了)
总结:可以用one-bit shared variables that can be read or written解决(在写之前读一下当前的占用状态)
3. Producer-Consumer
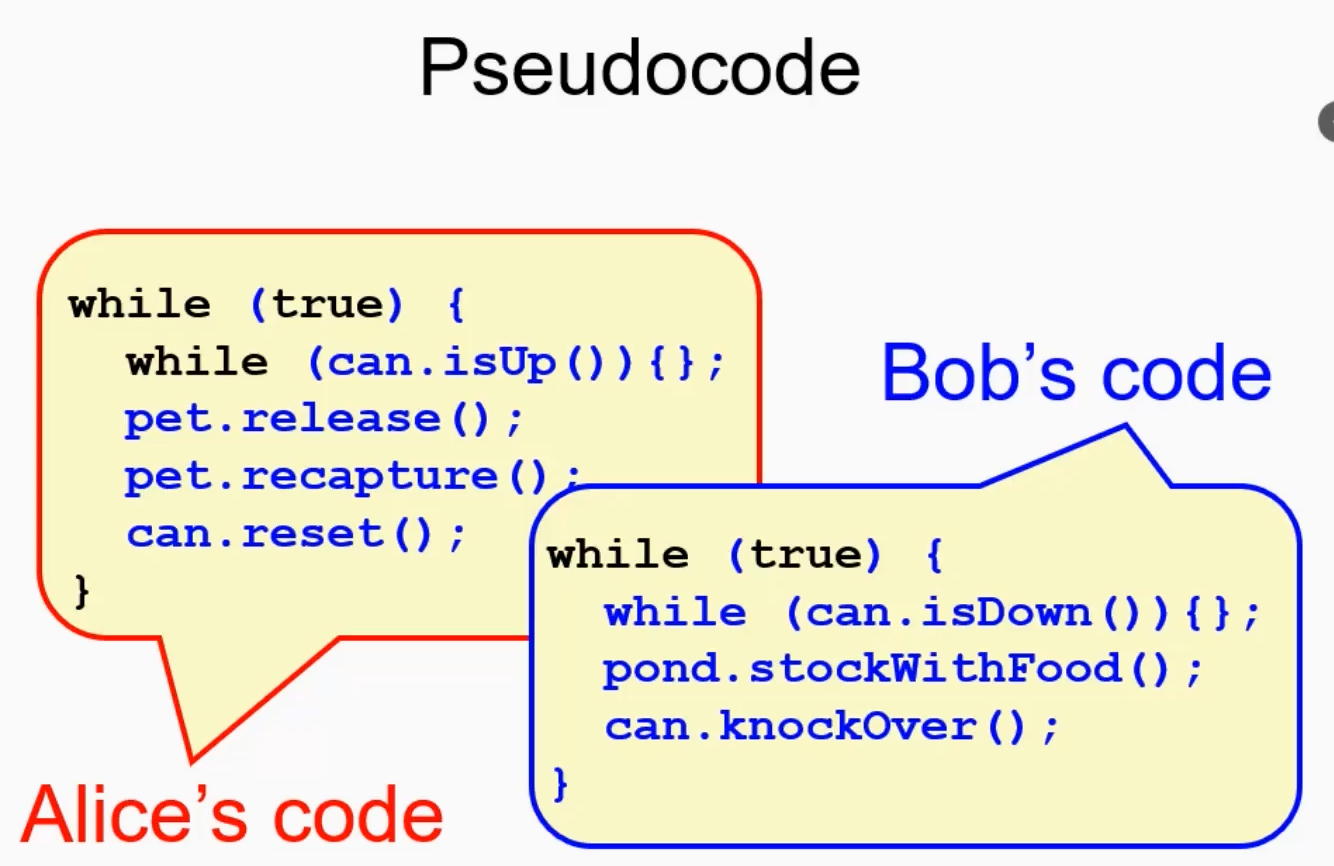
伪代码:通过可乐罐的倾倒与否放宠物/放食物(同时也能用旗子解决)
宠物不会饿死,相对公平

同样需要等待,而等待可能造成问题。
Speedup

锁越细粒度,可并发代码越多,就更能提速。
Mutual Exclusion
Definitions
Time:用箭头描述时间,共享统一的时钟
Event:瞬时发生的,不会有两个同时发生,一定有顺序
Thread:多个events的顺序
Threads是状态机里的过程
State=Thread State+System State
Concurrency:Thread的时间轴有重叠,交替执行。线程之间不一定是独立的,因为代码可以访问共享内存
Interval:两个event之间的时间区间。区间之间有顺序
事件event有全序关系,区间interval有偏序关系。

用锁实现计数器中读写两操作的原子化。
如果try里有问题(临界区),finally一定会执行释放锁。
Mutual-exclusion的定义:两个线程的任意两个临界区一定有先后顺序(不可能2个进程同时进入CS)
Deadlock-Free的定义:如果线程调用了lock但不返回,其他线程一定能调用lock和unlock,整个系统还是在前进的(可能某些线程会饿死),有一些线程能拿到锁
Starvation-Free(最强):每个线程都能拿到锁,每个线程都能前进

性质:满足Mutual-exclusion但是不满足Deadlock-freedom

如果一个线程在临界区(拿到锁),victim一定为对方。
性质:满足Mutual-exclusion但是不满足Deadlock-freedom
Peterson’s Algorithom
2线程版本

性质:满足Mutual-exclusion也满足Deadlock-freedom也满足Starvation-free
n线程版本
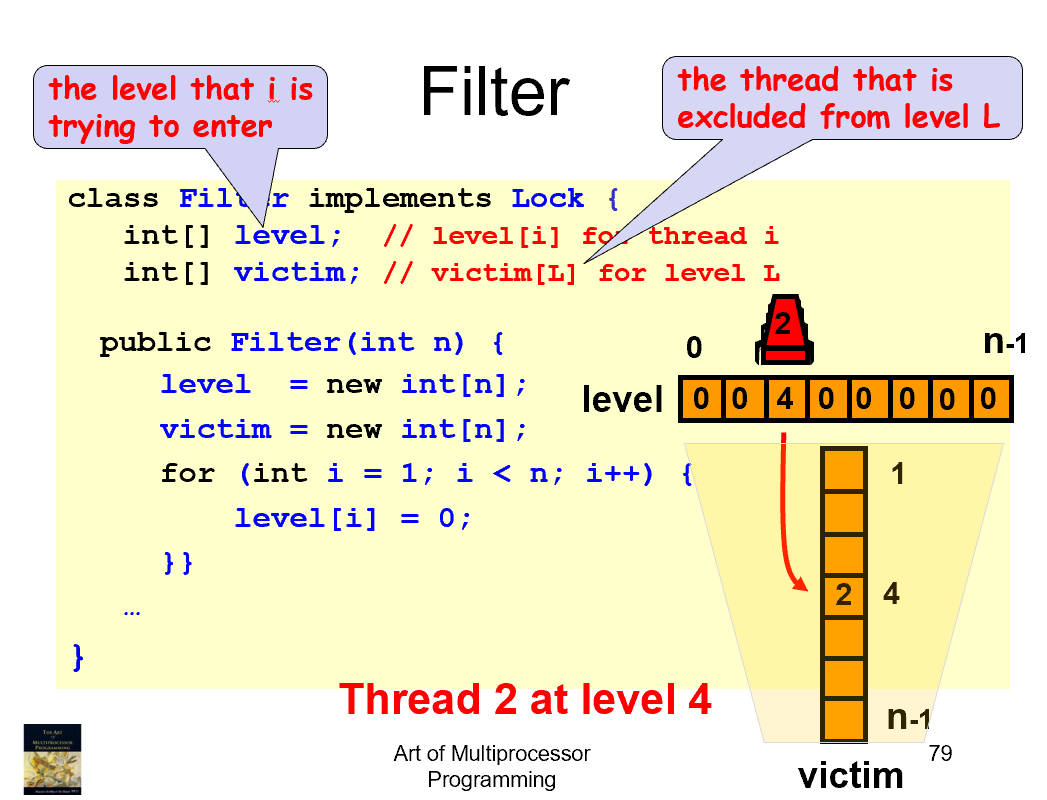
从第0层开始,n-1层才能进入临界区,其他都不行

性质:满足Mutual-exclusion也满足Deadlock-freedom也满足Starvation-free
Bounded Waiting:是否是先来先拿锁?即如果doorway A->B,是否有CS A->B?不满足!线程可以被overtaken任意多次

Bakery Algorithm
可以 实现First-Come-First-Served

label小的线程先拿锁。如果label一样,比较唯一的线程id。
性质:无死锁。先来先服务。满足Mutual Exclusion。公平。
Y2K千年虫问题:label会overflow,用串行化的时间戳系统代替
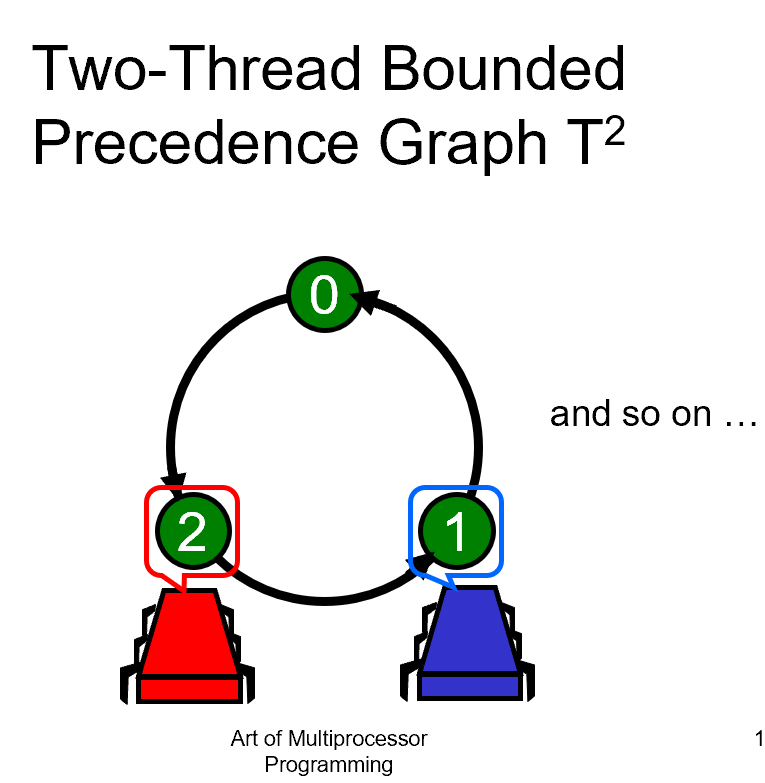
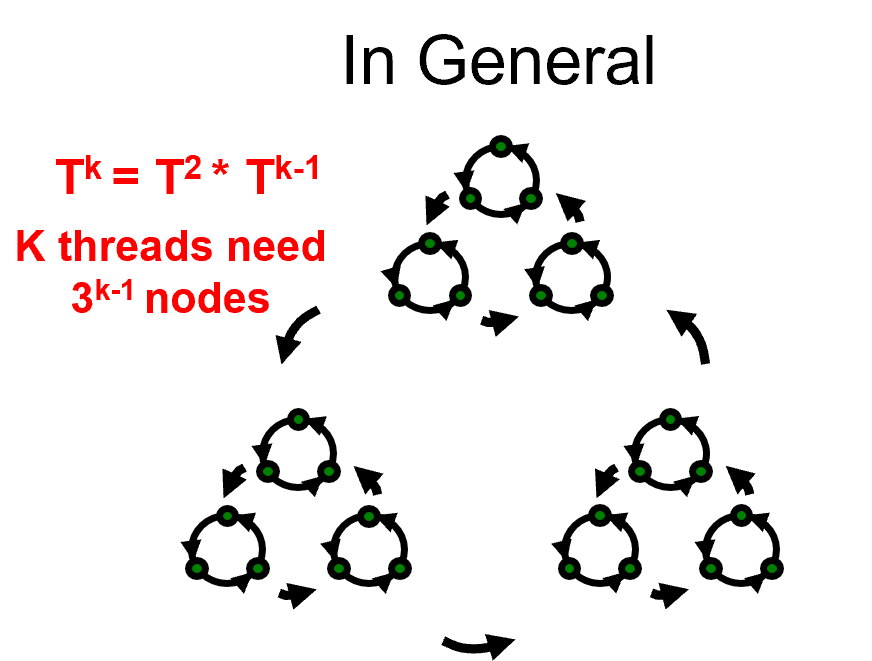
k个线程有3^k-1个结点,说明有上界,不会溢出(label的溢出可以解决)
最终Bakery算法因为空间开销大未投入使用。N个线程-2N个内存单元(flag+label)甚至用graph的话,需要<3N个内存单元
是否能用小于N种MRSW/MRMW实现deadlock-free mutual exclusion?
不能,否则有至少一个线程没有flag能写,就进入CS了。如果是MRMW也一定会覆盖至少一个进程的状态。
- 建立在有covering state的前提下(A马上写Ra,B马上写Rb)
结论:至少要N个MRMW/MRSW寄存器来解决deadlock-free mutual exclusion的问题。
Concurrent Objects
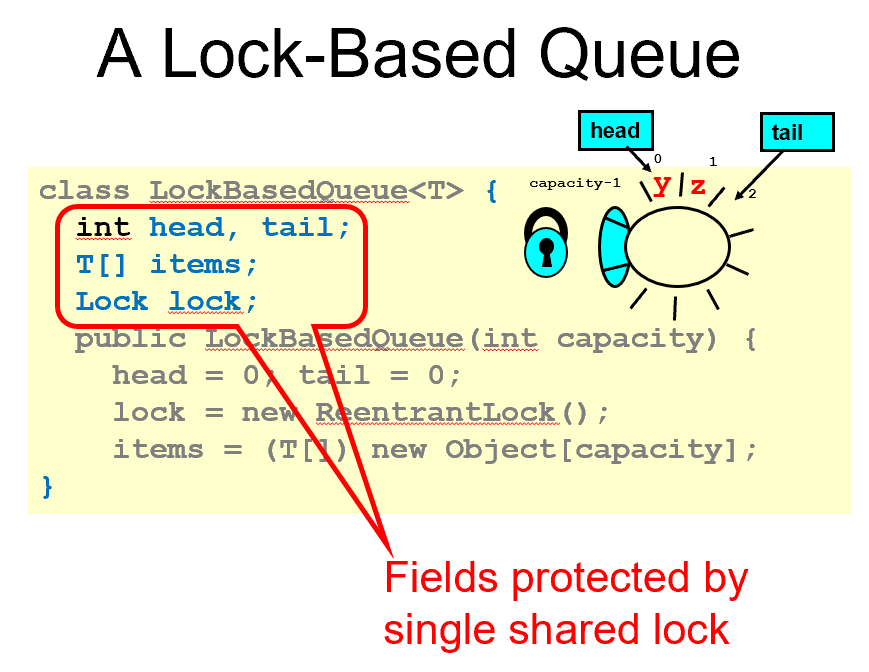
Lock-Based Queue


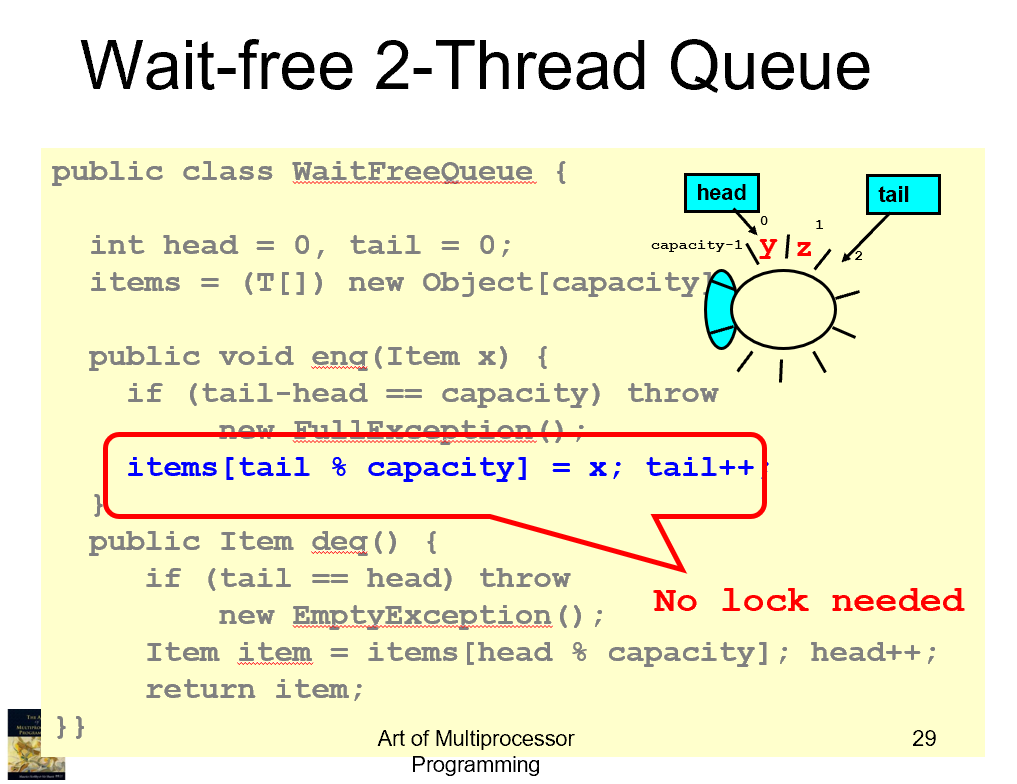
Wait-free 2-Thread Queue
这种实现方式没有锁了
如何证明算法的正确性?
Definitions
safety:有限步内可以检查
liveness:有限步内检查不出来
目前的correct只关心safety,不关心进展性
Sequential

而并发后,关心时间的长度,有overlap所以对象不存在2个方法之间的状态,且方法之间会互相影响

可以将并行算法中临界区执行的时刻method call对应到串行上
Linearizability

Linearizable的思想:虽然并发时method call有overlap,但起作用的时刻是瞬时的。如果所有执行形成了串行序列,那就是object就是串行化的。
example是否有可能是linearizable?存在一种时刻使串行化就可以了
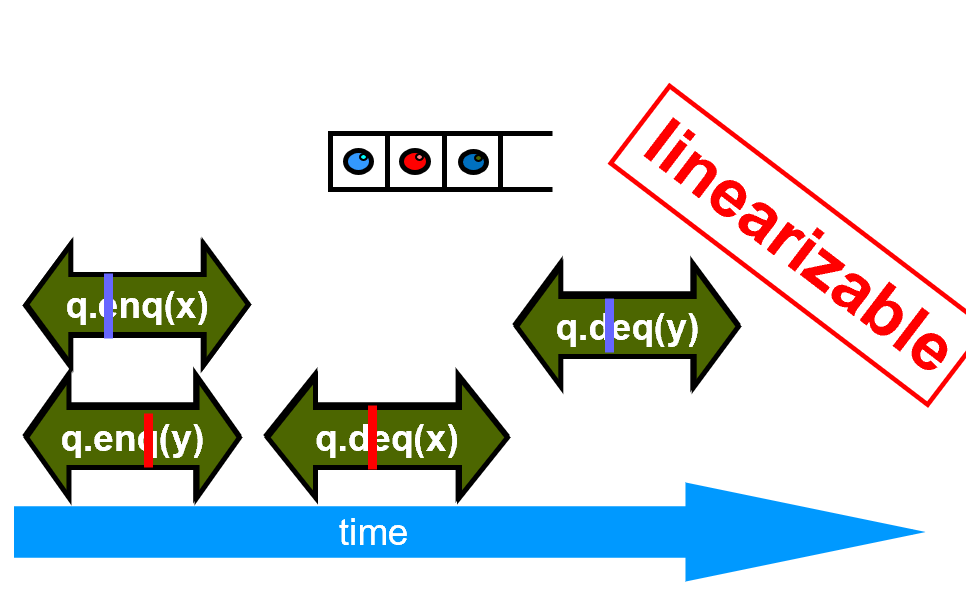
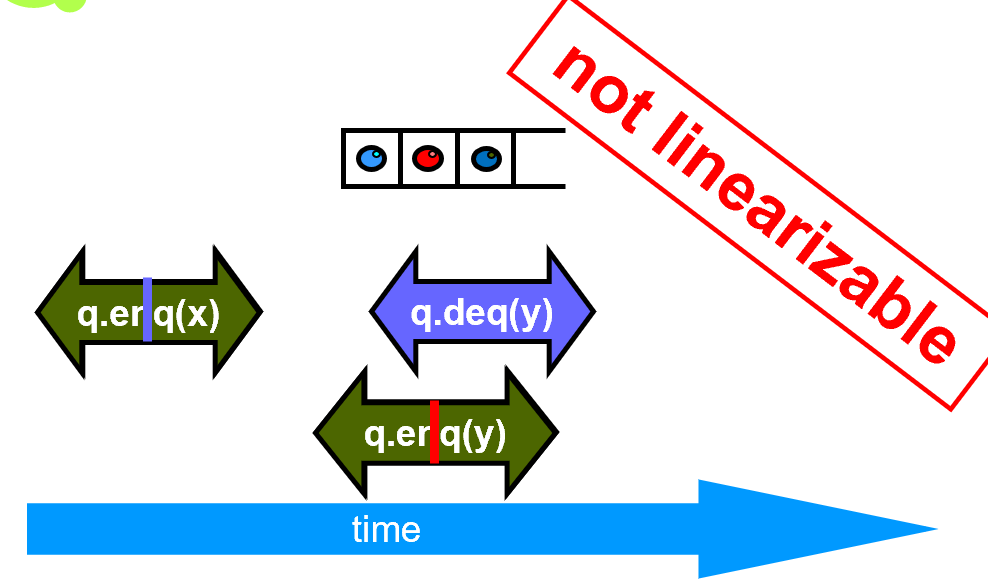
无论如何取时刻,都不能成立,说明不linearizable。如果能找出一种,就算linearizable。
取临界区里的任意一行代码,作为take effect的点,方便证明。
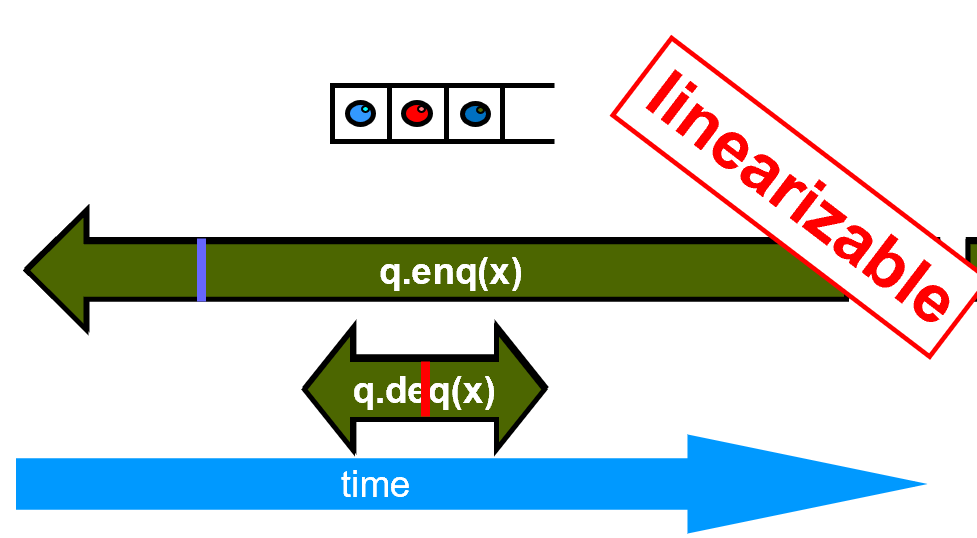
不关心方法调用是否能终止,只要在开始和结束中找到一个时刻,可以构造出来就行了
判断算法本身是不是linearizable:无法枚举所有的执行,能不能在方法内部找一条特殊指令,作为take effect的时刻?可以,但是有一些复杂的算法找不到这样的时刻,需要依赖执行
Executions
每个method call包含invocation和response
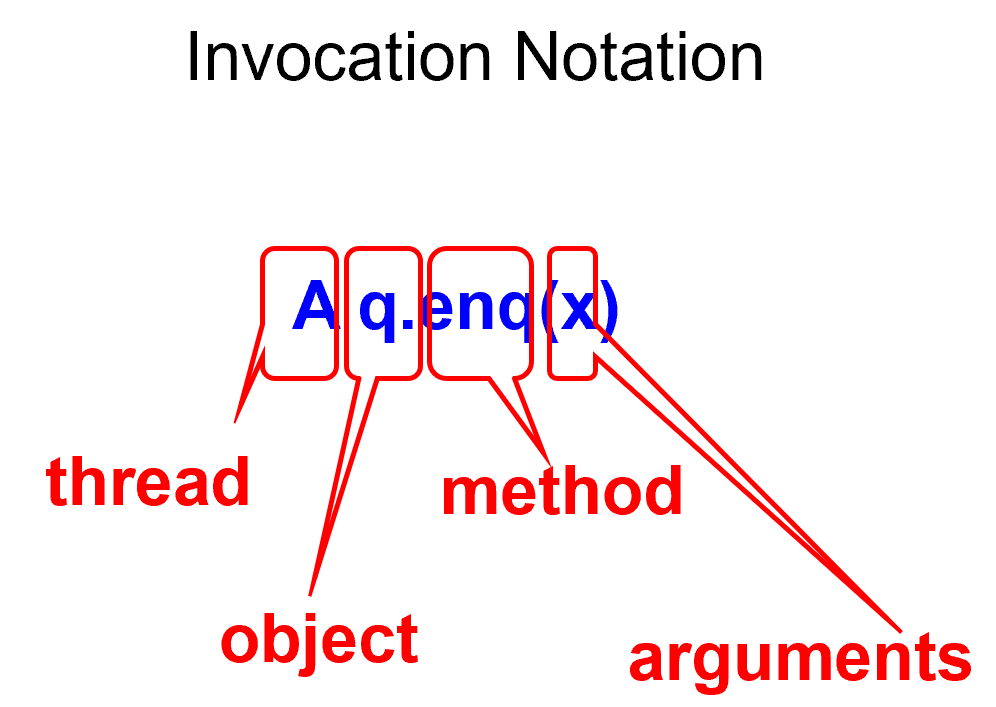
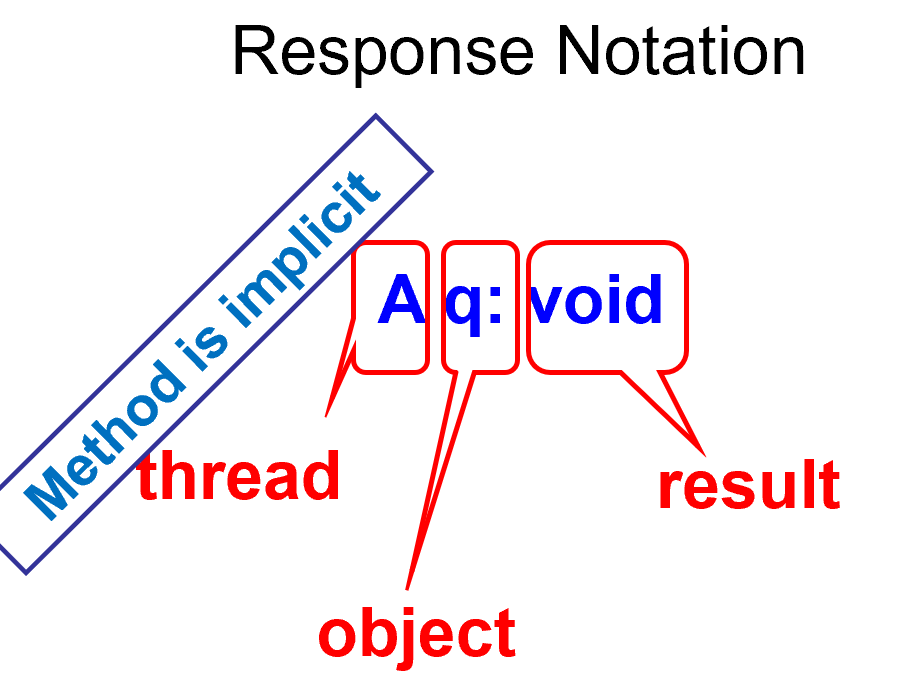

Object Projection只看对象,Thread Projection只看线程
对于pending,可以视作effect,补上response;可以视作没有effect,直接删除。
如果所有Invocation都有response,认为是complete subhistory
Sequential Histories

方法调用之间没有交错,最后可以有一个pending invocation
串行执行时,所有method call的区间是一个total order,必然有先后顺序
Linearizability
一句话总结:能不能将并发序列转换为a legal sequential history

- 预处理:对于pending语句,在H结尾加response或者删除,得到G
- equivalent:G和S在每个线程上的投影完全一样
- G和S的顺序被保持
composability:可组合性。每个object都是串行化,最后也是串行化的。

在lock后任选一条语句都可以认为是linearization,比如临界区或者unlock语句
大多数时候选择linearizable point,找不到的时候就枚举执行
判断不linearizable:找一个特殊执行就行
Linearizability:不关心算法是否终止
Linearizable point
将所有并发历史重新排序为顺序历史以判断程序是否可线性化的方法仅在理论上可行。在实践中,我们面临着由几十个线程对同一个方法的大量调用。我们不能对它们的所有历史进行重新排序,我们甚至无法列出一个复杂程序的所有并发历史。
side effect:如果函数或表达式除了返回值之外,还修改某些状态或与调用函数或外部世界具有可观察的交互,则称为具有副作用。
线性化点执行完成后,前面内存写入的效果需要立刻对其他CPU可见。即操作后可以立即观察到效果。比如enqueue中的tail->t1=node;可以马上观察到链表的增加。
总之linearizable point要能够代替整个方法的执行,效果也应该按照point的执行顺序来。
Sequential Consistency
同样描述并发对象的性质
相比串行化:可以在不同线程上re-order non-overlapping operations,但不能在同一线程上re-order

不是一个可组合的性质:p/q队列单独看可串行,一起看不行
大部分硬件架构不支持sequential consistency,因为写内存耗时,一般用cache
- 但这违背了先写自己的flag,后读别人的并发思想(锁的常见实现,如x86),怎么办?
- explicit synchronization: 内存屏障、编译器(Java volatile)
以linearizability关心程序是否正确

前两个使用锁,后两个不使用锁。而且第二个都大于第一个。
wait:每个线程,每个method call都能终止。lock-free:有一个线程返回就可以了,minimal
Synchronization Operations
希望能有wait-free的同步
Consensus的定义:所有线程可以输出一个同样的值(是某个线程输入的值)

只用锁(读-写寄存器)的话无法实现n个线程的wait-free,连consensus都做不到
如果想实现multiple dequeuers,怎么实现这样的FIFO queue(也可推广到其他对象上)

有queue->consensus,没有r&w->consensus,所以没有r&w->queue
Consensus Numbers
一个对象能解决n个线程的consensus,number为n:可以用来判断互相地实现
示例:能否实现multiple assignment?
因为有2/3 assignment->consensus,没有r&w->consensus,所以没有r&w->2/3 assignment
也侧面说明了每一个consensus number,都对应一个object,如queue,assignment
Read-Modify-Write Objects
Atomic Registers:支持原子读写整数值,但不一定支持复杂的,如比较交换(compare-and-swap)或其他 read-modify-write 操作
RMW Registers:支持在读取变量的同时对其进行修改,然后再写回新值。这些操作是原子的,以确保在多线程环境中不会发生冲突。

支持这种指令,就叫Read-Modify-Write,大多数并发指令都是RMW,少数不是的也可以转换
RMW能实现多少种线程?non-trival(不是y=x)的对象至少是2
compareAndSet可以实现任意多个线程并发-Consensus Number为正无穷

Lock-Freedom:相比wait-free要求更低,所有wait-free都是lock-free:有一个method call可以终止即可
Consensus本身是很强的,无论什么计算任务,都可以用Consensus表达

Spin Locks and Contention
lock分为两类:
- spin:拿不到锁会一直尝试
- give up:拿不到锁就会释放
TAS/TTAS
只使用一个bit的空间:因为只用一个boolean

TTAS简单优化,多了一个读,如果空闲的话再设置。
优化的原因:在自己的处理器上读,没有走总线,而TAS执行GetAndSet必然走总线
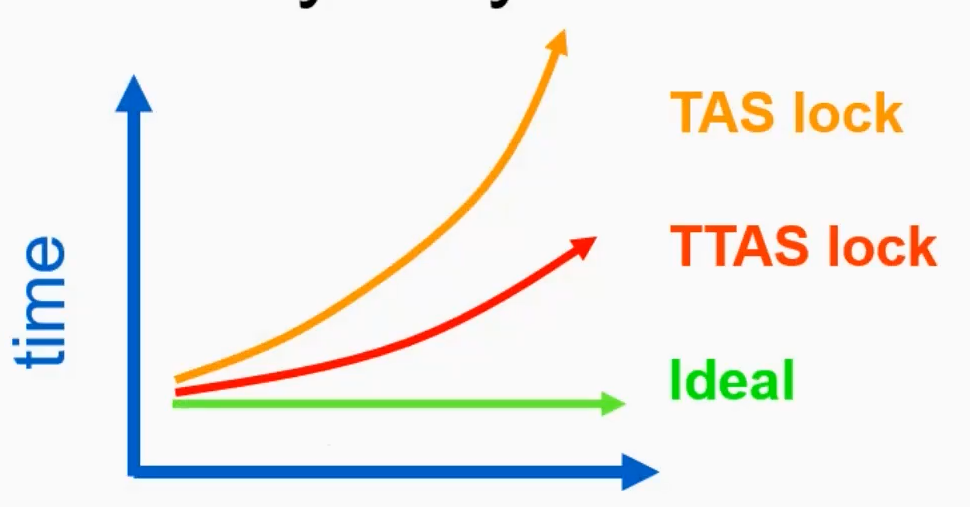
两个都不理想,model与现实世界不够相近,所以用Bus-Based Architectures(也只是简化)
Cache一致性:数据有很多副本 Write Back协议
TAS lock实现的Spin Lock的问题:拿到锁或者释放锁都会发invalid消息,同时修改memory里存储的state(表示锁是否空闲)争夺锁的时候因为TAS走总线,也会发invalid
Exponential Backoff Lock
改进:Exponential Backoff Lock,即如果获得锁失败,在再次尝试之前等待一段时间,等待时间以指数级别增长
- 缺点是延迟时间的初始参数需要预设,不同机器的参数不同,可移植性不够好
想法:让线程排好队去拿锁,按顺序通知,无需每次都竞争
Anderson Queue Lock

线程数多时比TTAS线程要好很多
缺点:需要的空间与线程数量相同,需要提前知道
CLH Lock
改进:用链表而不是数组存放每个线程的state
每个线程会分配自己的结点,然后对tail结点做getAndSet。每个线程可以访问两个结点。永远拿到前面的线程分配的结点,都是true。当释放时,将自己分配的结点变成false,排在后面的结点即可发现。
空间改进:释放过锁后之前的空间没用,可以在后面分配空间时重新使用

NUMA表现不佳:memory可能距离遥远,增加了时间
MCS Lock
改进:只在local memory上等待,如果自己的结点从false->true就说明可以获得锁


Abortable Locks
改进:支持中间等待的lock
Back-off Lock:不等就在lock()中直接返回
Queue Lock:因为在排队,不能直接结束(后面的会饿死)自己的结点应该在链上被删除
- 由当前不等的线程做的话,比较困难(因为要跟下面的线程交流)自己只是标记,让后面的线程来处理
Ticket Lock:也让线程排出队列,如果排在前面的线程增加了owner,后面才能拿到锁。
- 只用了owner和next,在操作系统中常见。
Linked Lists
锁/并发对象追求的目标:增加线程,耗时并不会最多(如何处理竞争资源)
- 细粒度同步:将对象变成很多块数据结构,分别加锁
- 乐观同步:先不加锁,后面有需要再加锁,检查是否需要加锁(不需要就释放)
- 懒同步:推迟remove?
- 不使用锁,使用compareAndSet():很强大,consensus number无穷大
用Set实现Linked List:无序、不重复、add/remove/contains。The List-Based Set从小到大排列,方便插入
Course Grained Locking
粗粒度,所有人竞争同一个锁
Fine-grained Locking
每个部分有自己的锁,在不相交部分工作的方法无需相互排斥
Hand-over-Hand locking:不断沿着list拿2个锁,直到找到对应位置。为什么一定要拿2把锁?并发时会出错,如同时remove(b)和remove(c)。
同时可以证明remove()是串行化的,linearization point是pred.next=curr.next,而这个操作被锁了

add():要锁e和前继
这种锁的优点:线程可以线性排列;缺点:找到要操作的部分链条很长,也会阻塞其他进程
Optimistic
先不加锁,找到位置,加锁,然后检查(看链表是否被其他线程影响)
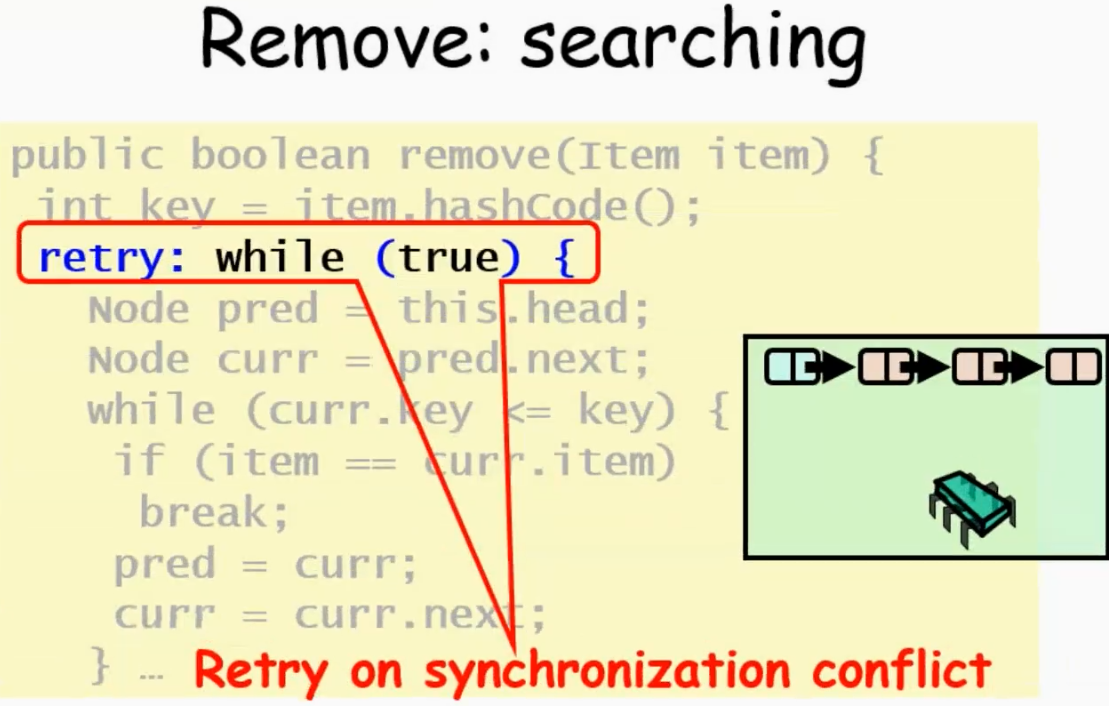
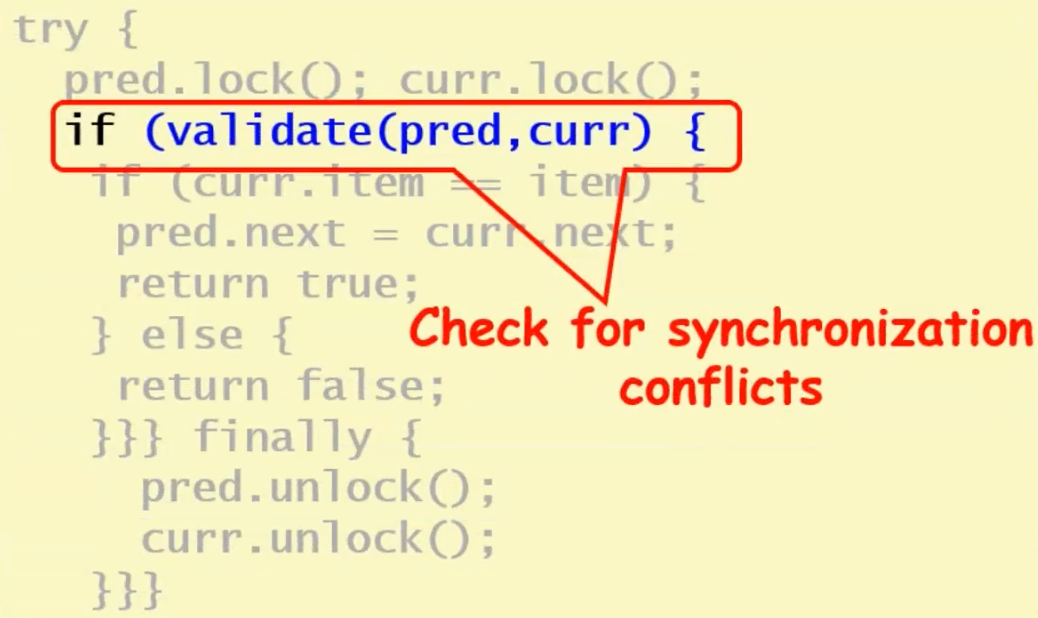
如果失败(curr找错了),会回到retry重新从head开始找
优点:更少的锁获取/释放;缺点:如果失败,需要重新遍历;contains需要加锁。deadlock-free(总是有某个线程能完成)但可能有线程不成功:别人一直在add/remove
Lazy List
区别是只会测试一遍,contains不会加锁
把remove分为2个阶段:修改结点bit本身(标记为已移除)-修改前继的next
先找位置-然后加锁(pre&curr)-logical delete-physical delete
- validation无需重新扫描数组,只需看pred未被标记/curr未被标记/pred指向curr
- 因为没有mark,就肯定从head可达
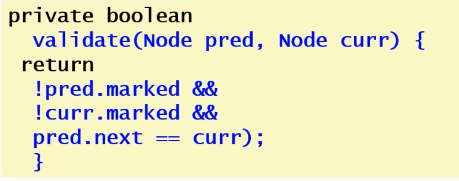


本身没加锁,但是不好找linearization point
- 如果返回false,当成发生的时刻,在curr.marked判断为true的时刻有可能另一个线程将curr add在list上,所以返回false的时刻并不是curr结点不在list上的时刻
- 即使如此,若能发现curr被mark,一定有一个并发线程在remove curr在contains之前完成,那么存在一个时刻,curr的结点被认为remove掉,那么返回false没问题,因为存在一个时刻curr不在list中(但这个point不明显,并不一定是检查到curr被mark的时刻)
- 只能保证deadlock-free,不保证starvation-free
优点:contains不加锁,是wait-free,因为contains比add/remove调用多,效率提高
缺点:add和remove失败后还是会重新traverse
想法:整个算法能不能不加锁去做?因为有锁就有竞争和等待,所以提出Lock-Free
Lock-free Lists
对Mark-Bit和Pointer一起做CAS,Java提供了AtomicMarkableReference

如果pred.next返回false也没事,因为Lock-free find在traverse时如果遇见mark为true,会进行remove


和Lazy实现一样,返回false不代表那一刻。执行中有一刻存在,所以是linearizable的