1. RNN/GRU/LSTM
序列模型
1.1 RNN
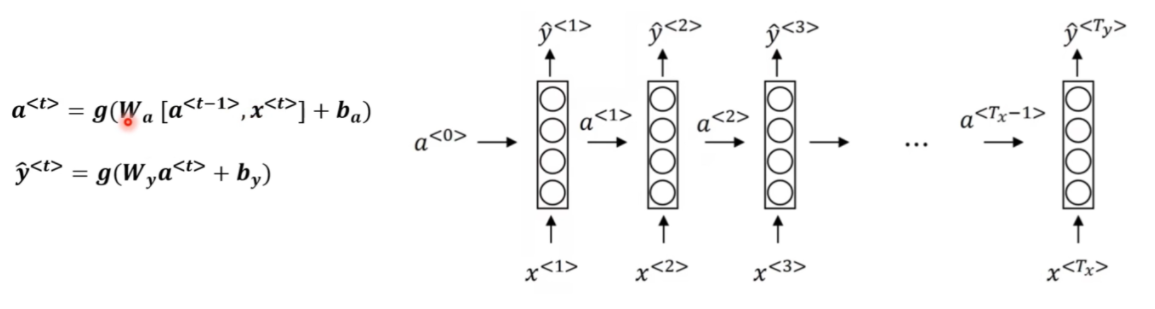
分阶段,串行输入每个x,再输出每个y
结合当前的输入x^t与前一时间段的状态值a^(t-1)
激活函数g,参数值都是反向传播学到的
把Waa和Wax拼接成Wa,a^(t-1)与x^t拼接成[a^(t-1),x^t]上下堆叠,可以把两次乘法变成一次乘法(计算并行程度更好,效率更高)
1.2 GRU
引入记忆单元c^t,c^t=a^t
更新门:Γu控制更新多少

重置门:Γr,使用多少前一状态信息
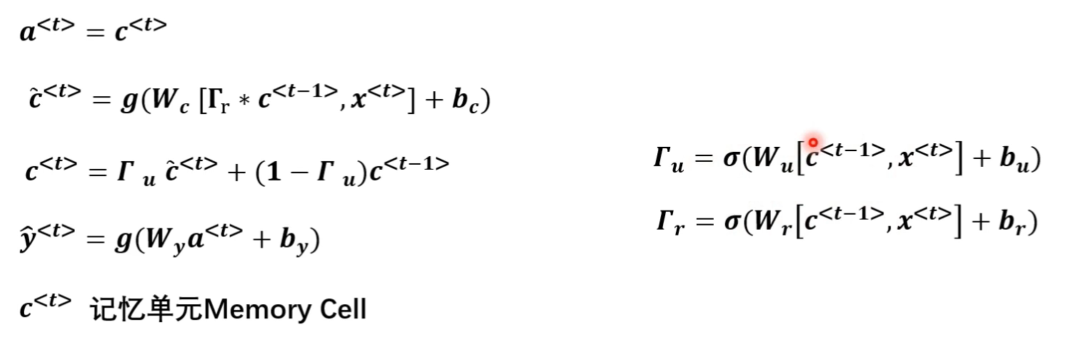
- 算Γu更新门、Γr重置门,sigmoid函数
- 算c~^t
- 算c^t(相当于算了a^t)
- 算y_hat^t
1.3 LSTM
a^t != c^t

2. Attention & Transformer
Attention
并行
向量:列向量,左右拼接,变成矩阵

X*Q:query向量
X*K:key向量
X*V:value向量
α就是注意力分数,是k和q的乘积之和,然后通过softmax进行归一化(所有α之和等于1)
A‘是值,V是向量,相当于对向量进行缩放,α相当于V的权重,即得到更多的attention
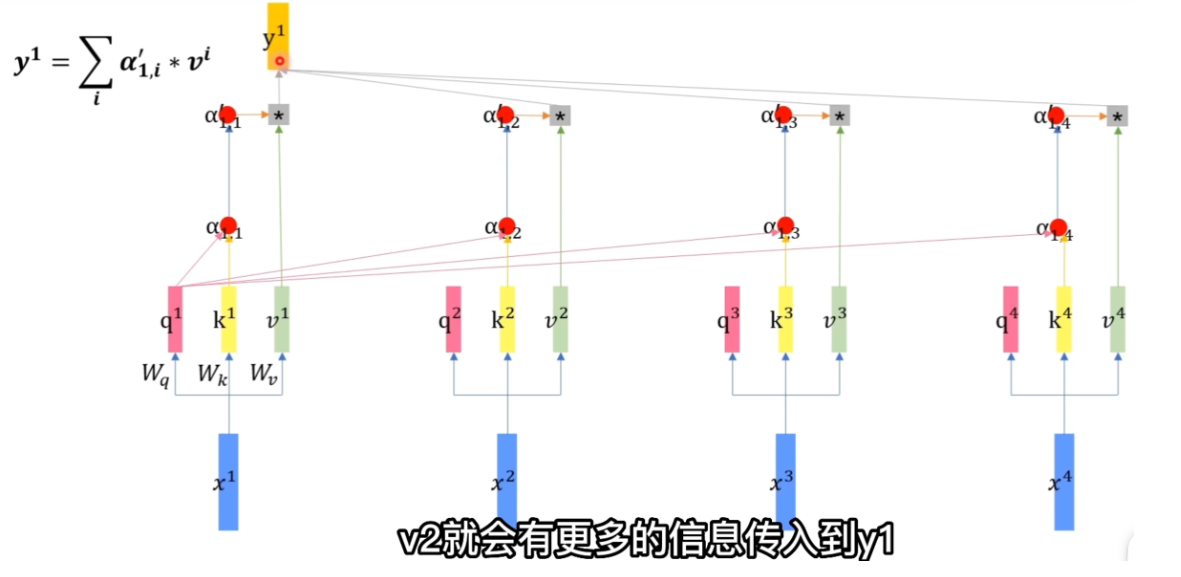
- 先获得qkv.W的维度根据Q/X决定
- 每个qk进行内积运算得到attention score
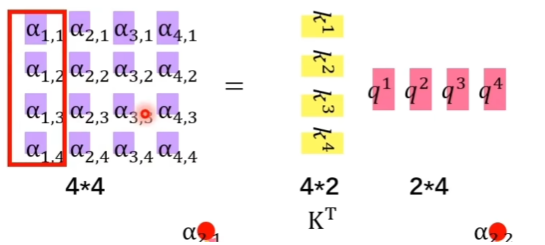
- 对每列α进行归一化

- 最后计算y

Attention模型忽视距离,无论两个向量相隔多远都会乘上
缺点:没有位置信息,可以用位置向量进行补充(比如transformer用sin/cos,这里门道也多)

transformer:用输入向量位置pos和维度d_model进行对应位置向量的计算。通过以上两个公式,可以获得一个维度为4的位置向量e2,奇数位置的数用下面的公式得到,偶数用上面。即e2的1234个位置应该是0,1,1,2
Transformer
在文本摘要任务中,输入可能是一篇文章,输出是该文章的摘要。 在对话生成任务中,输入可能是对话历史记录,输出是模型应该生成的下一句话。 在语音识别任务中,输入可能是音频信号,输出是对应的文本转录
很适合序列任务
2个特征:1. 编码器-解码器架构;2. 自回归(前一时刻的输出会作为后一时刻的输入)
对于机器翻译任务,编码器的输入是源语言单词的独热编码(3个向量),输出是一系列经过全连接层和标准化处理的向量。在解码器层,输入包括编码器的输出、目标语言中的标记(如开始标记、结束标记)和之前已经生成的目标语言单词的向量表示。
关于为什么这里直接把BOS和“永不言弃”编码成词向量,输入解码器,“永不言弃”怎么来的,这里的输入直接就是最终的“标准答案”,这样在训练的过程中可以引导解码器训练更好的参数。当然在预测任务中不知道答案,这时的输入仅有编码器的输出
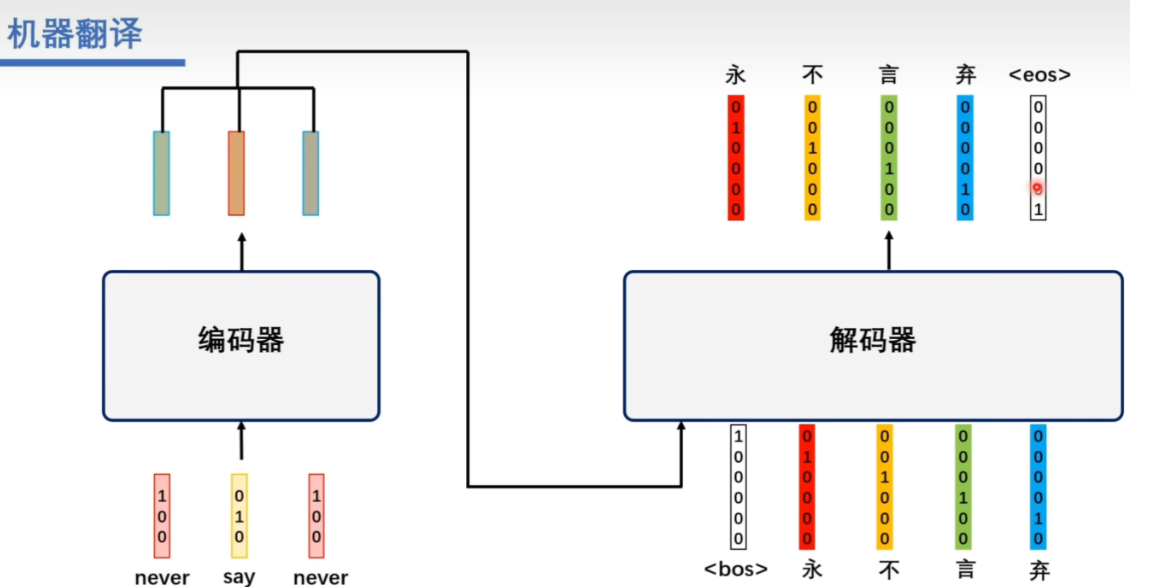
编码器
Encoder处理输入的信息,把输入向量补充位置信息,经过Self-Attention输出y。输出向量的个数和输入一样。
Add&Norm:
- Add: 把y与x相加,这里y和x维度要一样(一开始的input embedding和后面的linear会改变向量长度,当然x是input embedding的结果)
- Norm:层标准化,所有值减去均值然后除以标准差
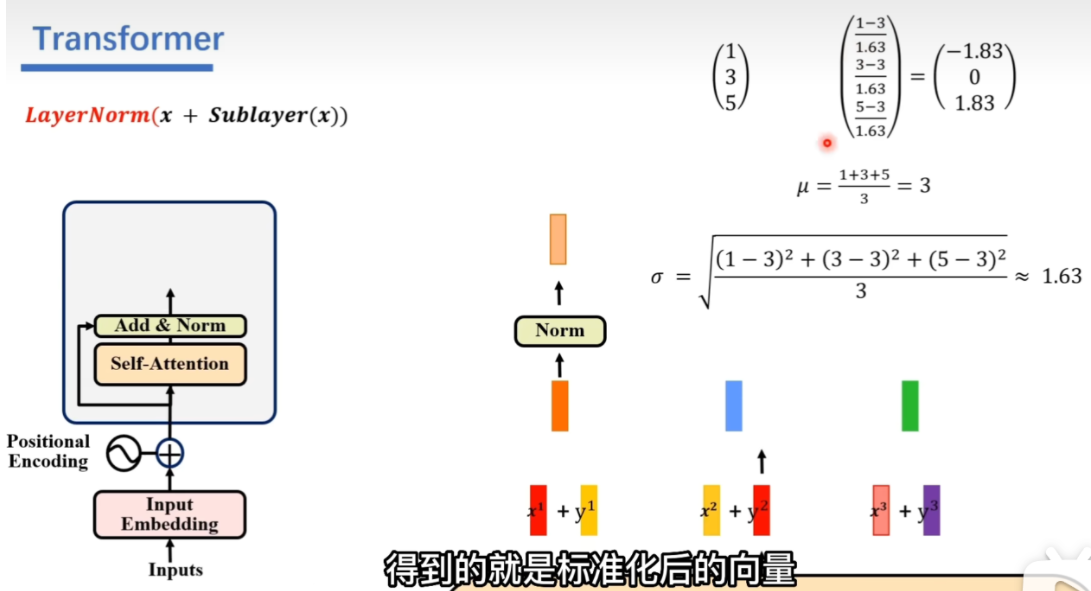
Feed Forward:全连接的神经网络进行非线性转化,后面还要通过一层Add&Norm

解码器
解码器的输入是前一时刻编码器的所有输出
然后进行Output Embedding操作,编码成词向量再加上位置向量,新向量输入到Masked Self-Attention(为了实现自回归)
真实操作顺序:
- 只有一个向量,经过Output Embedding+Positional Encoding,它隔壁的向量都乱七八糟。此时根据编码器的所有输出和进行输出“永”向量
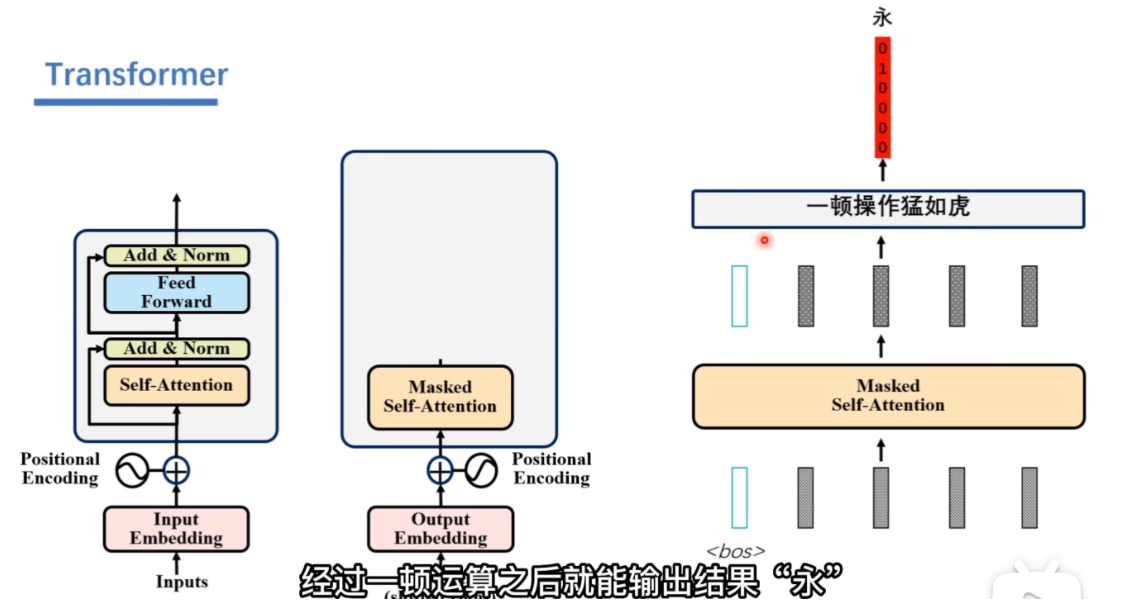
- 有永和两个向量,编码器根据这两个向量和编码器的所有输出,输出结果“不”
- 如此往复循环直到得到eos
所以Masked Self-Attention我们希望只关注具体有的向量
基于掩码的注意力机制后:不关注的向量填充为0向量,保证维度
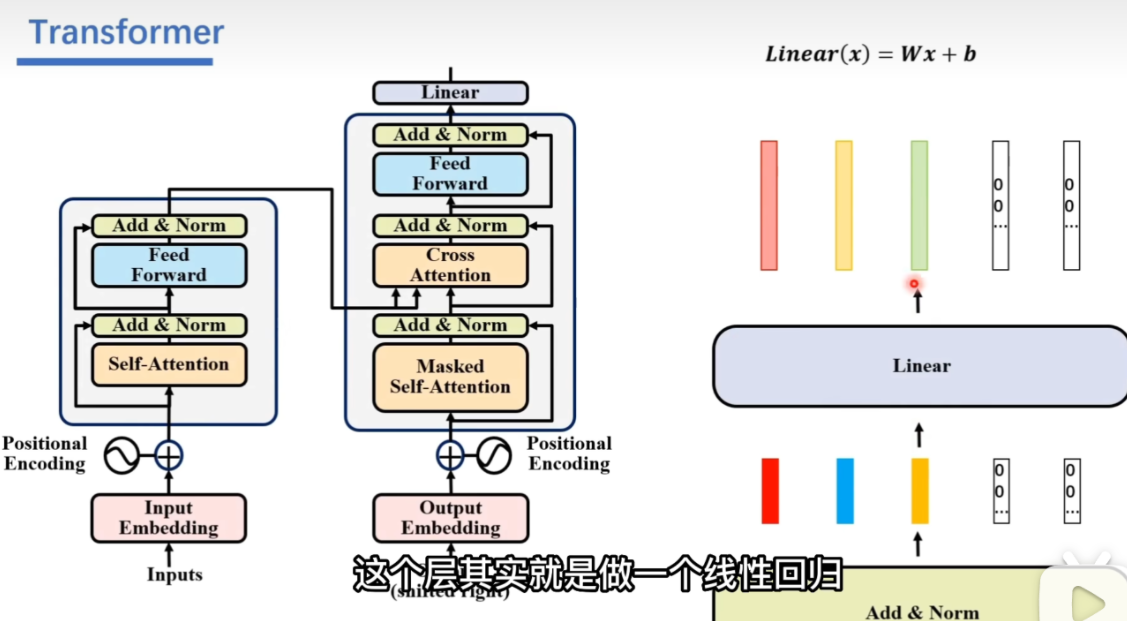
Linear:wx+b,转换向量的维度,与输出结果向量的维度是一致的

最后输出向量的向量,每一维代表当前这个字出现的概率。将最大的位置置为1。TODO:这里好像不是一起输出的,只有绿色那里有向量,且“言”的one-hot值最大,其他向量都是乱码
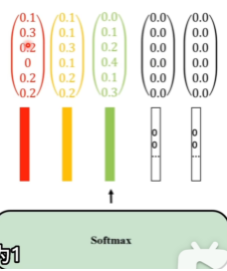
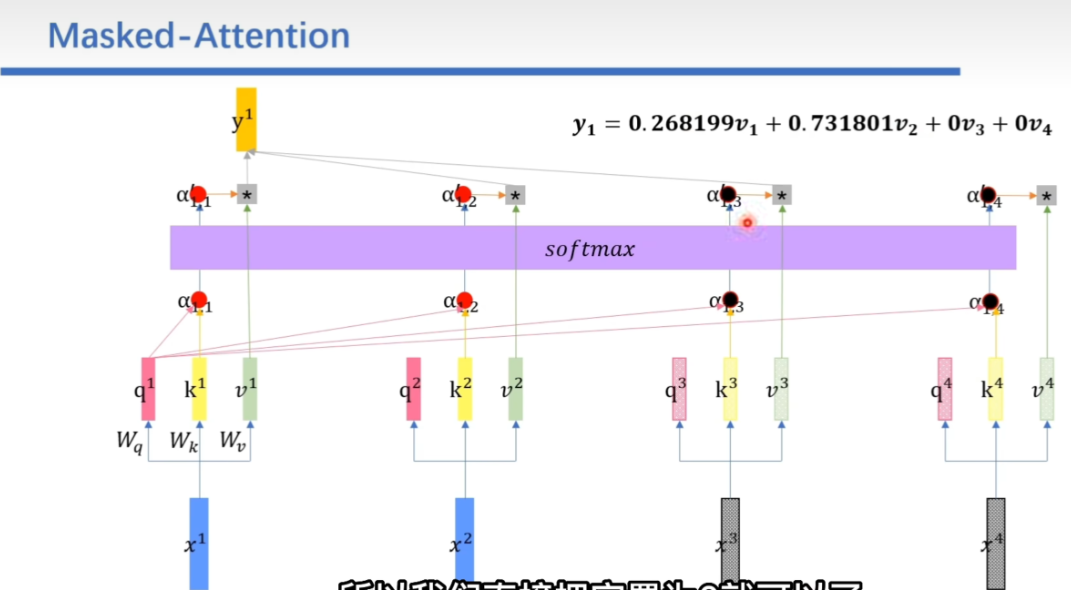
Masked-Attention
把不关注的向量的α值设置为-∞
然后在归一化时,不想关注的地方权重就是0
Cross-Attention
混合编码器和解码器的信息
比如编码器输出3个向量,生成k,v;解码器这边有5个向量,生成q
用解码器的q查询编码器的k,做内积运算,得到α,然后softmax,乘v,得到输出y
3. 对比学习综述
监督学习近些年获得了巨大的成功,但是有如下的缺点: 1.人工标签相对数据来说本身是稀疏的,蕴含的信息不如数据内容丰富; 2.监督学习只能学到特定任务的知识,不是通用知识,一般难以直接迁移到其他任务中。
自监督学习是无监督学习的一种方式,它的主要目的是在非人工标注的数据中通过自己监督自己来学习到有用的信息。可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。
对比学习有正负样本,但不属于有标注数据,因为可以实现自我标注而构建规则
第一阶段
InstDisc
个体判别任务:因为长的相似所以判别为同类。每个instance都是一个类别,把每个图片都分开。
把每个图片编码作为一个特征,让最后特征在特征空间里尽可能地分开
正样本:图片本身,可能经过数据增强
负样本:其他图片
memory bank:存放图片的特征,每个图片的特征大小是128维
输入为正样本(数量看batch_size),待进行个体判别,负样本在memory bank中随机取。学习后计算NCE loss,更新memory bank
InvaSpread
对比学习:同样的图片经过CNN后应该很类似,不同就不类似
正样本:经过数据增强的图片 1 负样本:剩余的原始和数据增强图片 (256-1)*2 在同一个mini-batch中选负样本,可以用一个编码器做端到端的训练
只用一个编码器,无需其他结构存储负样本
CPC
前两个是判别式(学习决策函数f(x)或条件概率分布P(y|x),不还原P(x,y),只学习差别然后分类等),这个是生成式(学习P(x,y),然后生成P(y|x)或决策函数Y=f(x))
预测的代理任务
音频序号作为序列,特征给自回归模型gar(如RNN/LSTM),每一步输出红色的Ct,代表上下文的特征表示。根据前者的特征得到后者更好的特征。
自回归模型(Autoregressive Model)是用自身做回归变量的过程,即利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型,它是时间序列中的一种常 见形式。
正样本:Xt+1…Xt+4 未来的输入
负样本:其他的输入,得到的输出预测应该是不相似的
CMC
正样本:一个物体有多种视角,最重要的特征在不同传感器(视觉/听觉)共享。希望学到强大的特征,强大的互信息,让不同传感器都能分类。
4个view:原始、分割图像、距离图像等。这些互为正样本。负样本就是不配对的视角。
clip:有多模态思想,如把图片和文本当正样本对。文本端:bert;图像端:vit
局限性:使用几个view/模态,就要使用多个编码器。计算代价高。但是现在一个transformer处理两个模态效果反而更好(可以处理多类型数据,无需针对数据做改进)
第二阶段
Moco
对比学习:将样本通过模型映射到特征空间,在特征空间中拉近同类的样本,并使得不同类的点排斥开。
NLP任务中的原始信号空间与CV领域不同,NLP领域原始信号为离散的信号,对应词典,无监督学习可以基于此很好的学习。而计算机视觉领域,图片是连续的高维的信号,不适合构建字典。当前在无监督视觉表征学习的研究都是关于对比损失contrastive loss,都可看做构建动态字典dynamic dictionary。
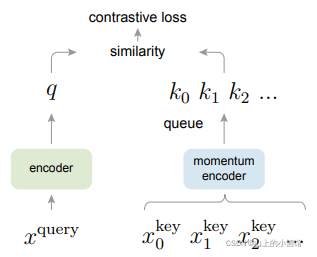
queue:解决大字典的问题。使得当前mini-batch的数据进入序列,并把最老的mini-batch挤出序列。
动量编码器:解决字典特征不一致的问题。不是更新特征,而是更新编码器。Ekt = mEkt-1+(1-m)Eq。当m比较大时,Ekt 与Ekt-1取得相似的结构,使得所有key的编码器都有相似的结构。
编码器是一个体征提取器。可以使用卷积网络。论文中使用的ResNet50。
改进InstDisc
SimCLR
对图片进行两种数据增强,得到的2个图片xi/xj是正样本,剩余的2n-2是负样本
2个f:共享权重,相当于一个编码器
g:projector降维 全连接+relu激活 mlp层(多层感知机) 训练才用,下游任务不用
- relu将线性变成非线性?不是很懂
- 不加relu的全连接层是linear的
对比学习很需要数据增强技术,最有效是crop/color

更大的batch_size:TPU
128就够了
Moco v2
数据增强+MLP+cos+训练更多的epoch
- epoch:一次前向+一次反向。一个Epoch就是将所有训练样本训练一次的过程。
- batch:一次epoch的样本太大时,分为多个batch。batch_size是每批样本的大小。
- iteration:训练一个batch就是一次iteration,一个迭代就是梯度下降的过程,会优化参数
- GD:没有分批次,整个数据集训练,计算开销大full batch
- SGD:batch_size=1,每次计算一个样本进行梯度下降
- mini-batch: 就是选合适数量的子集。有时候会走弯路但整体是朝最优解迭代的。

Moco的优越性相比SimCLR在于硬件,需要的GPU和训练时间少。端到端对硬件要求很高
SimCLR v2
适合半监督学习(少量有标签的数据和大量无标签的数据)
先用大量未标注数据,用SimCLR自监督获得预训练模型
再用少量的有标签数据,进行有标签的微调,获得teacher模型
用teacher给无标注数据生成伪标签,继续进行自学习
v1->v2:1. 把模型变得更大;2. 试着把MLP变多到两层;3. 使用动量编码器(但提升不多)
SwAV
对比学习+聚类+multi-crop
没有用负样本,用的是聚类中心,但也是明确对比的东西
两个crop:指数据增强后的两个图片
multi-crop:增加正样本,增加view,然后取图片的维度减小,使计算代价尽量不变(关注全局+局部)
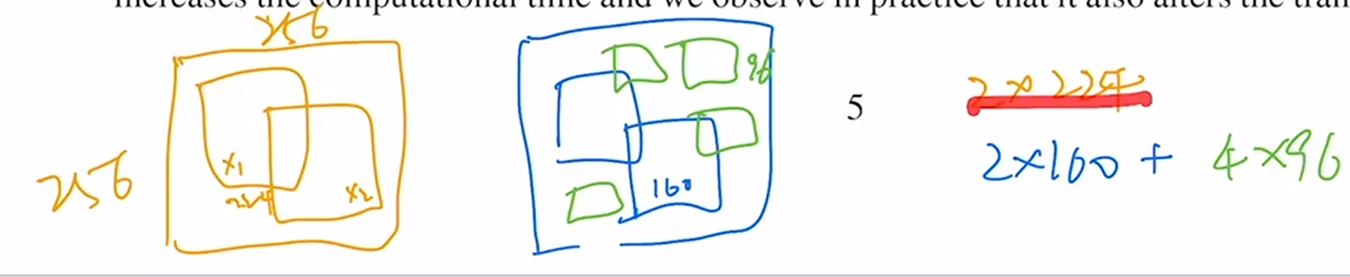
聚类:按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。不关心类是什么,只需要把相似的聚在一起(计算相似度即可),所以是无监督的学习
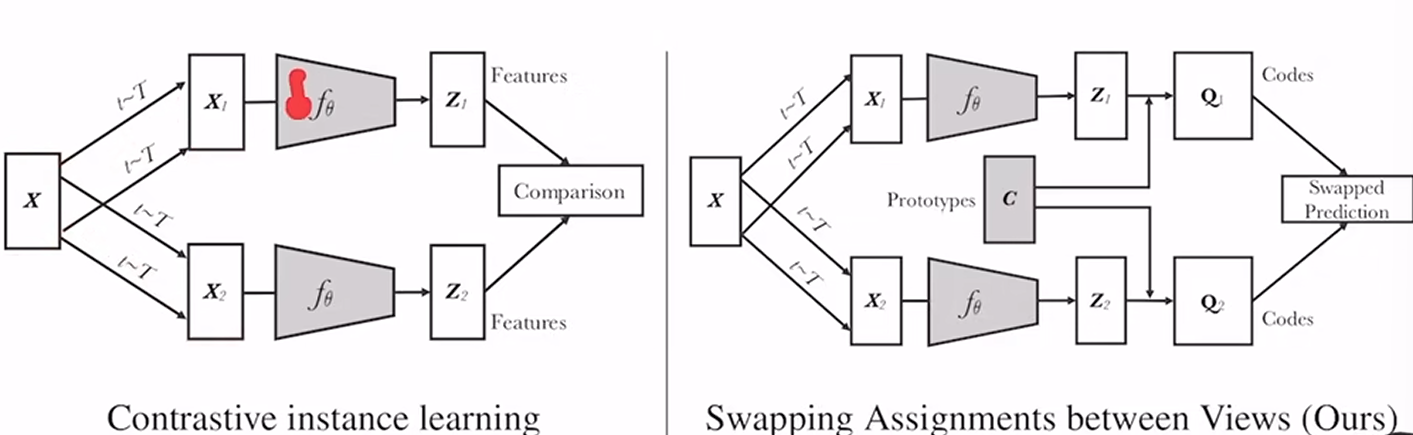
获得zi/zj特征后计算loss
我们可以把对比学习看成是一个字典查询的任务,即训练一个编码器从而去做字典查询的任务。假设已经有一个编码好的query q(一个特征),以及一系列编码好的样本k0,k1,k2,…,那么k0,k1,k2,…可以看作是字典里的key。假设字典里只有一个key即k+(称为k positive)是跟q是匹配的,那么q和k+就互为正样本对,其余的key为q的负样本。一旦定义好了正负样本对,就需要一个对比学习的损失函数来指导模型来进行学习。这个损失函数需要满足这些要求,即当query q和唯一的正样本k+相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。反之,如果q和k+不相似,或者q和其他负样本的key相似了,那么loss就应该大,从而惩罚模型,促使模型进行参数更新。
拿特征和特征对比费资源,能不能不和负样本作近似,而是利用先验信息和聚类中心比较。
z和c生成目标q,作为ground truth,q1和q2可以互相预测
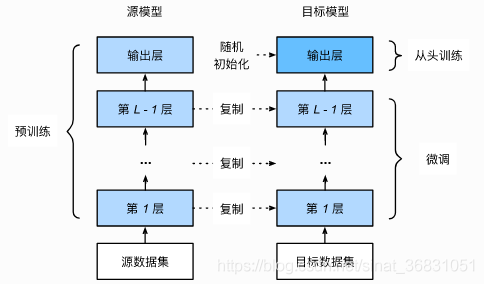
预训练 就是指预先训练的一个模型或者指预先训练模型的过程,一般是他人的常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数
微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(例如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
CPC v2
更大的模型+更大图像块+方向上的预测任务+batch norm换成layer norm+更多的数据增强
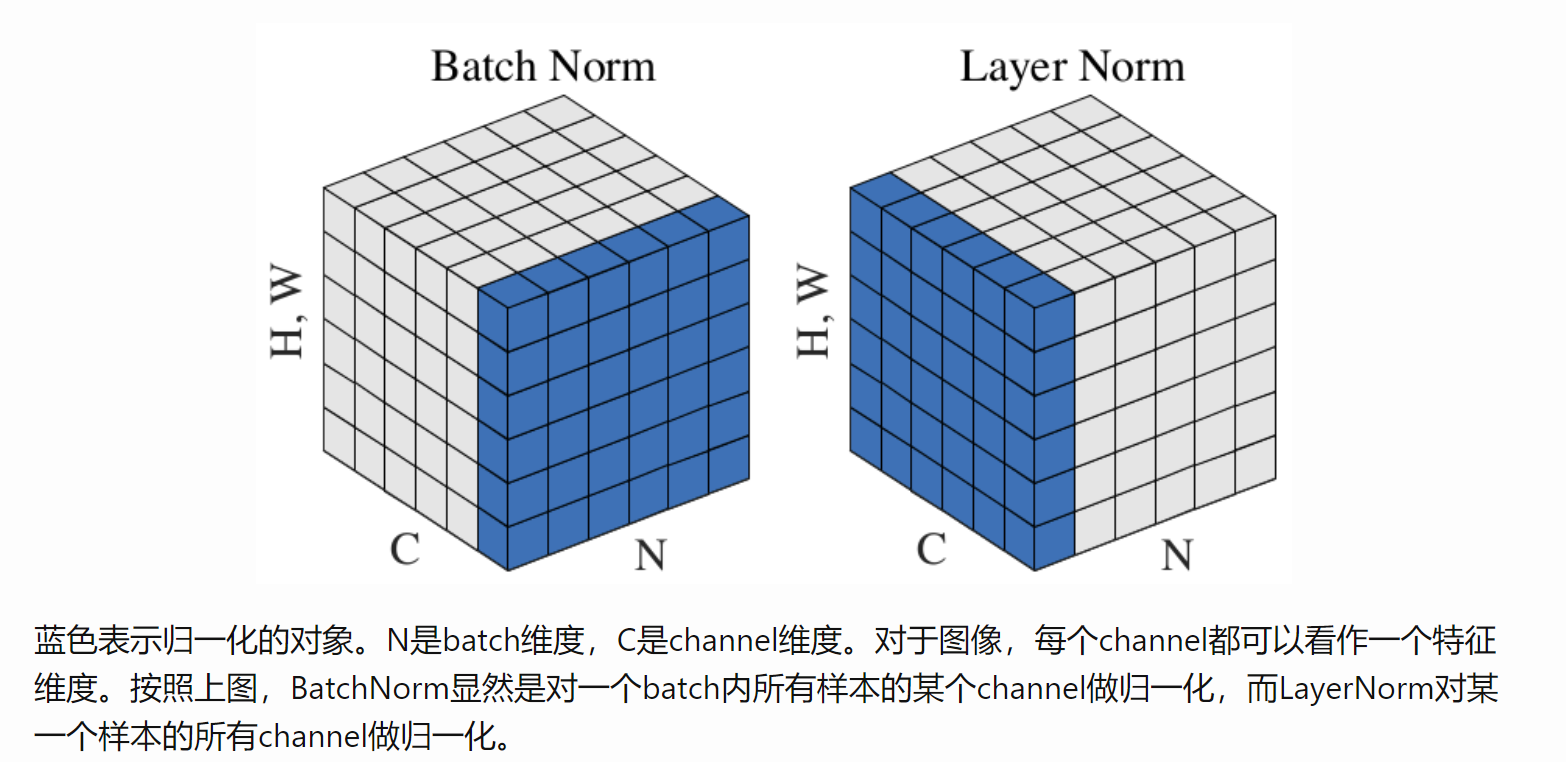
处理图像的角度:蓝色表示归一化的对象。N是batch维度,C是channel维度。对于图像,每个channel都可以看作一个特征维度。按照上图,BatchNorm显然是对一个batch内所有样本的某个channel做归一化,而LayerNorm对某一个样本的所有channel做归一化。
BatchNorm/Layer norm的作用
1.加快收敛速度,有效避免梯度消失。 2.提升模型泛化能力,BN的缩放因子可以有效的识别对网络贡献不大的神经元,经过激活函数后可以自动削弱或消除一些神经元。另外,由于归一化,很少发生数据分布不同导致的参数变动过大问题。
处理文本的角度:蓝色表示归一化的对象。BatchNorm与上一幅图基本一致,对一个batch内所有样本的某一个特征维度做归一化。但是,LayerNorm与上一幅图有所不同,这里是对某一个样本的某一个token的所有特征维度(即该token的embedding)做归一化。在Transformer结构中,每个token都是单独的语义单元。LayerNorm的作用是让每层语义单元的输出分布保持稳定。
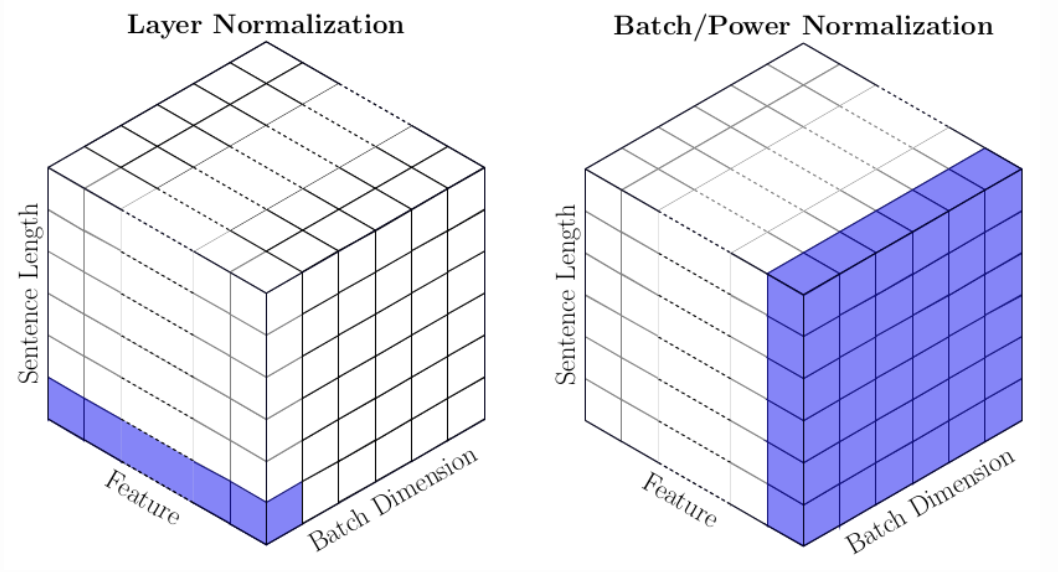
文本句子的特征是编码后的原始数据,即多个token。
token:模型输入基本单元。比如中文BERT中,token可以是一个单词、一个词组、一个标点符号、一个字符等,取决于文本处理的需求和方法。
embedding:一个用来表示token的稠密的向量。token本身不可计算,需要将其映射到一个连续向量空间,才可以进行后续运算,这个映射的结果就是该token对应的embedding。
encoding:表示编码的过程。将一个句子,浓缩成为一个稠密向量,也称为表征,(representation),这个向量可以用于后续计算,用来表示该句子在连续向量空间中的一个点。理想的encoding能使语义相似的句子被映射到相近的空间。
informing
infomin:不需要太多的互信息,获得需要的互信息就行,多了可能影响泛化
中庸思想
第三阶段
BYOL
特征的不同用词:latent hidden feature embedding
没有用负样本。负样本是对比学习的约束,不然相似的物体有相似的特征,模型输出一致(捷径解,模型坍塌),使loss=0即可。
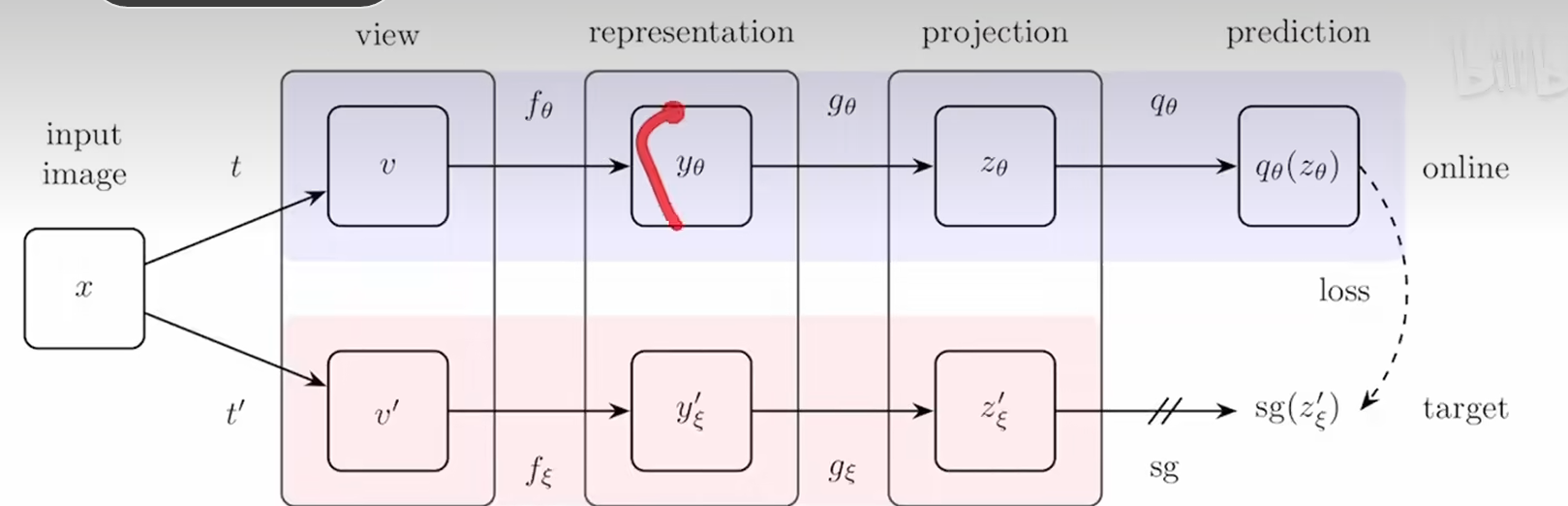
fθ随梯度更新而更新;下面的f是moving average(动量编码器)得到特征z后,simclr会进行尽可能地接近(maximum agreement)
这里又加了新的一层predictor,q也是mlp,得到qθ(zθ),把匹配问题变成了预测问题(用一个视角的特征预测另一个视角的特征)用MSE_LOSS做最后的损失函数
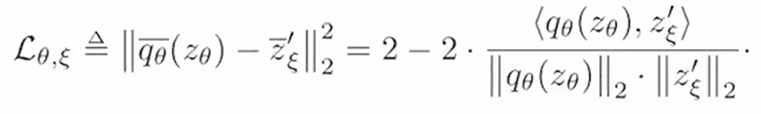

MLP层有两个BN层

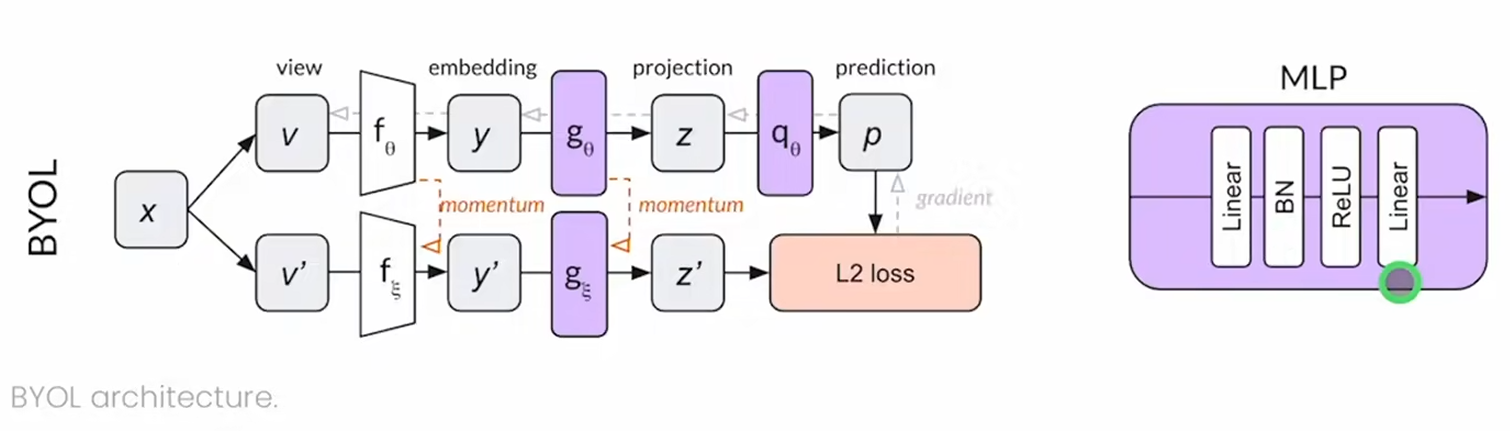
有了BN其实也在做对比,比较正样本图片和平均图片(类比聚类中心)有什么区别,属于隐式的对比学习
simsiam
stop gradient使模型不坍塌,可以理解为EM算法
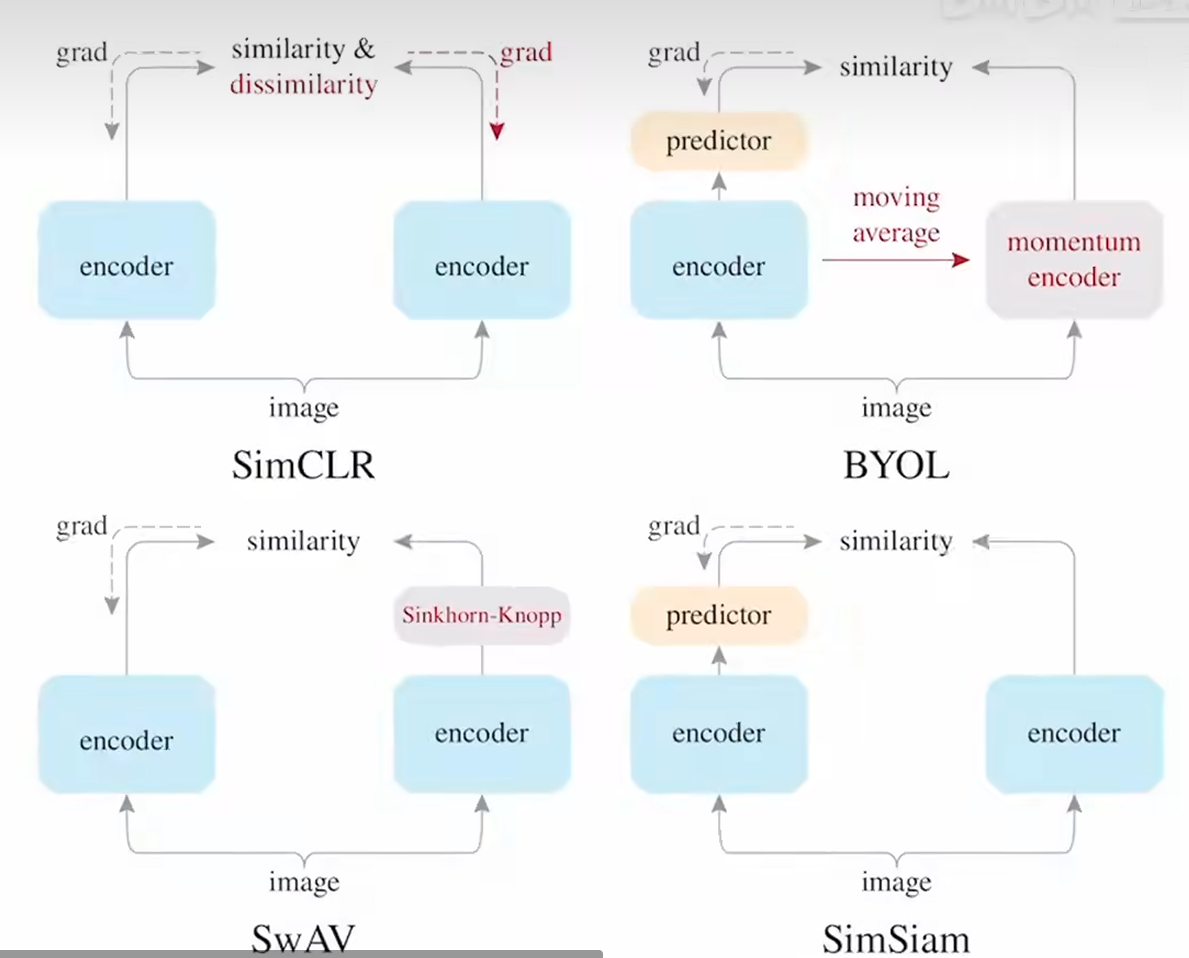
simclr:对比任务,有端到端的对比回传
swav:对比任务,和聚类中心比较(聚类中心通过SK算法得到)
byol:预测任务,左边预测右边,动量编码器
simsiam:预测任务,共享参数来更新(而不是用梯度回传或动量编码更新)
还是用moco v2作为基线任务好
第四阶段
vision transformer
把骨干网络从ResNet换成Vit
loss大幅震度正确性有下降时,看梯度也有震荡,发现问题是在图片->patch的过程中(tokenization),把random patch projection冻住就好了
如果不动transformer,就只能在开头tokenization和结尾改目标函数
DINO
自蒸馏框架
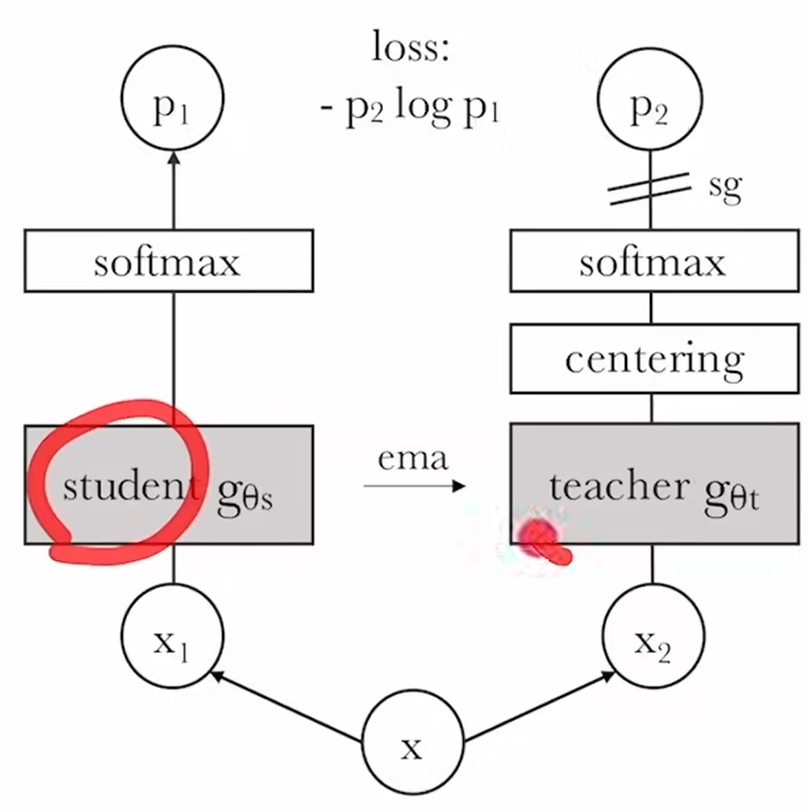
centering:防止模型坍塌,给所有样本做均值,类比BN
总结
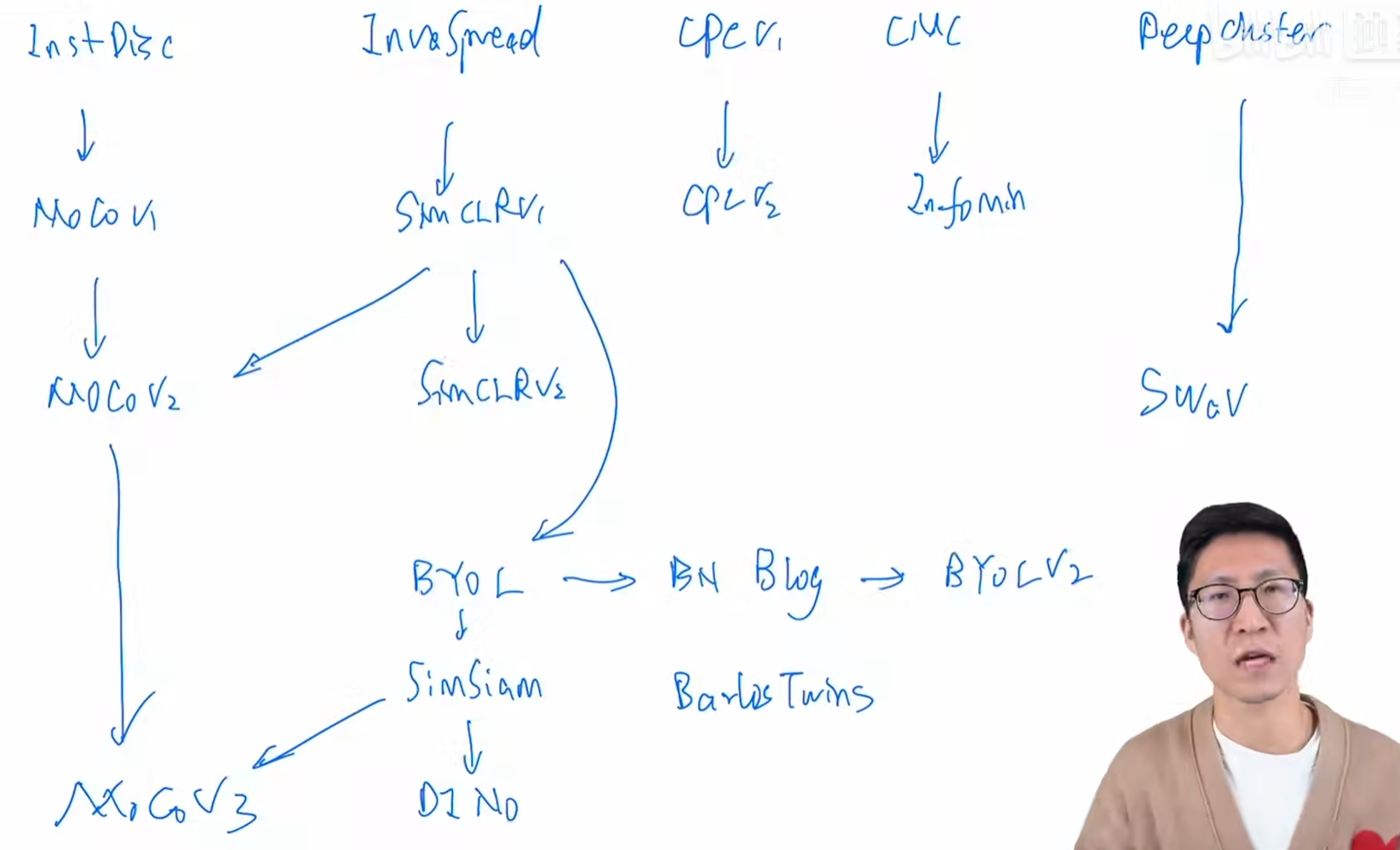
- 第一阶段
- instDisc: 个体判别,memory bank外部结构
- invoSpread: 端到端,一个编码器,batch_size小
- cpcv1:预测性代理任务,图像、音频、视频
- CMC:2视角变为多视角
- deepchester:聚类学习
- 第二阶段
- moco v1:memory bank变成队列,动量更新特征变成动量编码器
- simclr v1:加大batch_size+projection head+训练时长长
- cpc v2
- infomin:互信息刚刚好就行,不过量
- moco v2
- simclr v2:主要针对半监督
- swav:对比+聚类(multi-crop重要)
- 第三阶段
- BYOL:对比->预测,mse loss,自己和自己学
- BYOL v2
- simsiam:孪生网络的学习方法。假设stop gradient很重要,EM,逐步更新避免模型坍塌
- 第四阶段
- vision transformer:骨干网络从Resnet换成vit,有不稳定的现象
- moco v3:提出把projection head冻住改善不稳定
- DINO:把teacher的输出作centering
MAE:掩码学习
CLIP 多模态的对比学习仍然是主流 图像和文本一起