Lec1 概率论、线性代数
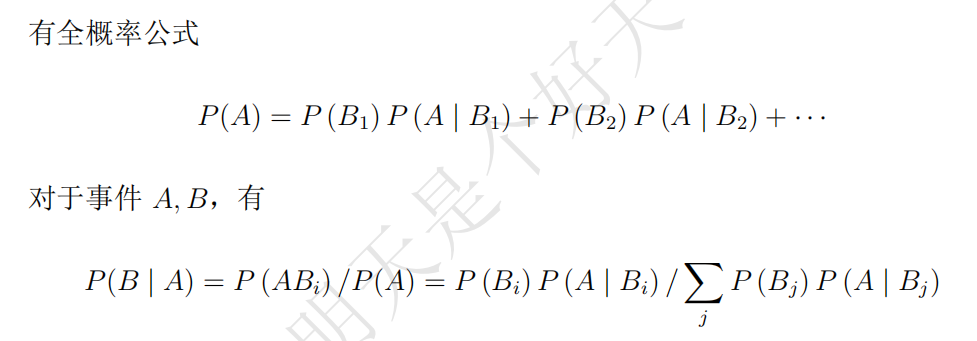
边缘概率分布:通过求和”联合概率分布来得到的,如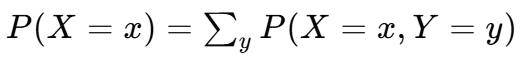
xy独立说明P(xy)=P(x)P(y)
注意随机变量大写,取值小写

全期望公式:
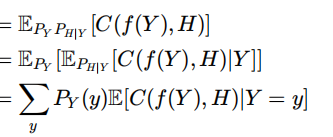
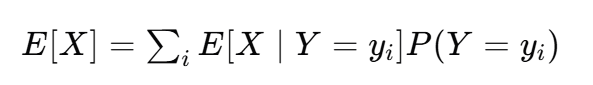
期望是[]内内容的平均
E[X^2]=Σx^2*P(x)
条件期望是Y已经已知了,所以遍历X即可
注意期望有分配律

概率密度函数:在某一点的值指的是概率在该点的变化率(或导数),不是概率值
均匀分布的定义是,随机变量在指定区间上取值的概率密度是均匀的,区间之外的概率密度为 0。
多元高斯分布

这里的可逆矩阵当然满足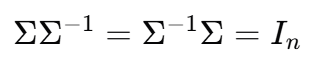
奇异值分解

Lec2 熵、互信息、K-L散度
我们介绍了信息论后续发展所需的大多数基本定义。信息的概念太宽泛了,不能用一个单一的定义来完全捕获。然而,对于任何概率分布,我们定义了一个称为熵的量,它有许多性质,与信息度量的直观概念相一致。这个概念被扩展到定义互信息,互信息是一个随机变量包含另一个变量的信息量的度量。熵就成为一个随机变量的自化。互信息是一个更一般的被称为相对熵的量的一种特殊情况,它是对两个概率分布之间的距离的一种度量。所有这些量都是密切相关的,并共享一些简单的性质。
香农熵
事件p的信息量f(p)=-logp
熵的单位是bit。熵中以2为底,所以log2=1
离散变量X:观察到的所有信息量。-logP是随机变量,Px是概率分布,用右下角的分布对里面的变量求加权平均
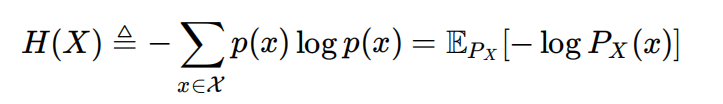
联合熵

条件熵
XY两个向量,先固定X,再固定Y,使一次只看一个变量。对x,y的两个求和可以合成一个对x,y的求和
表示有X信息后还可以获得的Y的信息
注意条件熵的初始表示就是遍历所有X的取值
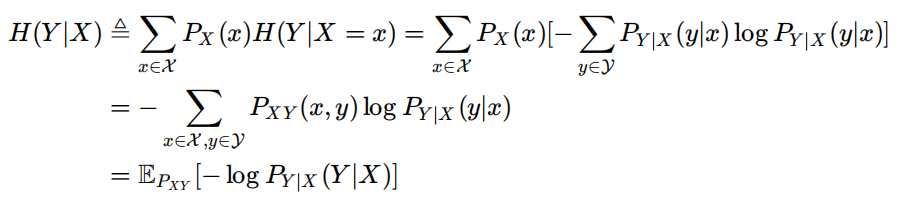
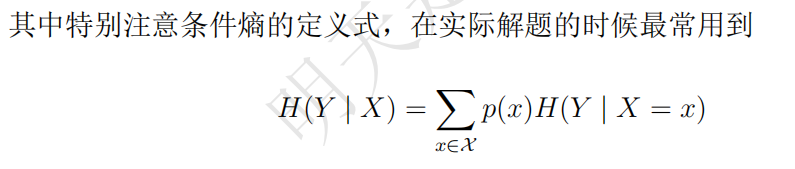
链式法则
注意多画图片,以及H(X)这里的表示,有y也不影响

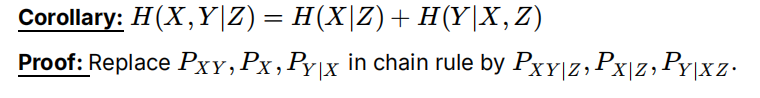
互信息
衡量观察X后可以获得的Y的信息。注意是分号

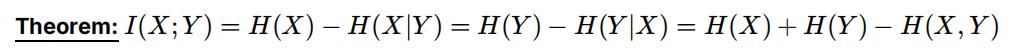
对于条件,可以用遍历加权来求
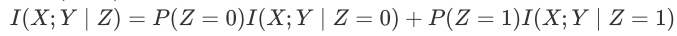
KL散度/相对熵
衡量X的两种概率分布Px/Qx的相似程度,分布的距离
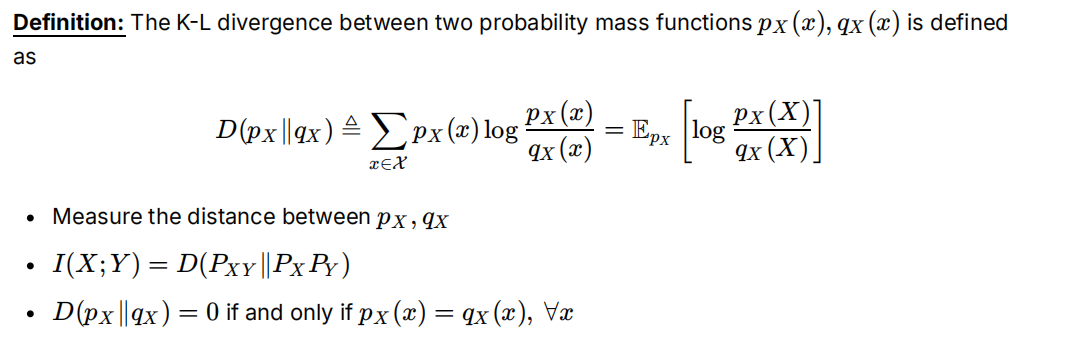

链式法则
熵
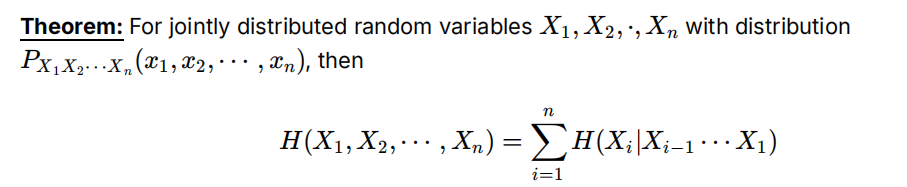
注意条件联合熵也有链式法则(加|Y成立),H(X1…Xn|Y)=\sum H(Xi|Xi-1…X1Y)
证明可以用H(X,Y)反复拆,也可以利用概率P的链式法则
互信息
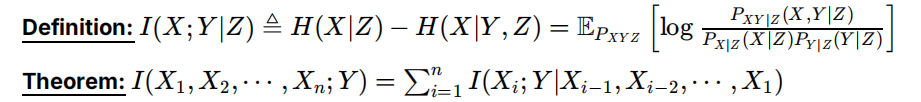
这里的链式法则也可以应用于后面加|Z的情况: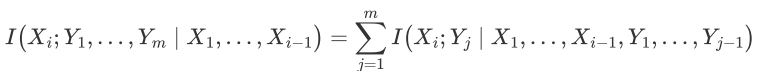

Lec3 不等式:Jensen不等式、熵的凹凸性、数据处理不等式
凸凹性
凸:convex
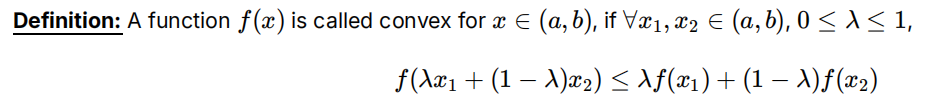

凹:concave
琴生不等式
对于凸函数符号如下,凹函数要反过来。

可证明KL散度>=0,在px=qx时取等
证明H(X)那里设置了q(x),很巧妙
条件均使熵减小,联合也比相加熵小,符合直觉,因为有一定信息了

熵的凹凸性
log sum不等式/KL散度是凸
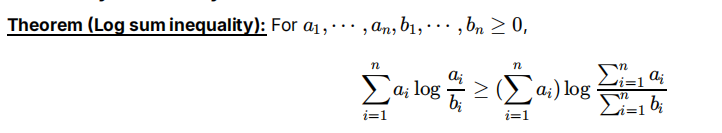
带入琴生的f(x)=xlogx可以证明(λ=1,xi=ai/bi)
KL散度是凸:用a1/a2/b1/b2代替即可证明

熵是凹
假设比较难想,Z以λ的概率在p1分布采样,以1-λ的概率在p2分布采样
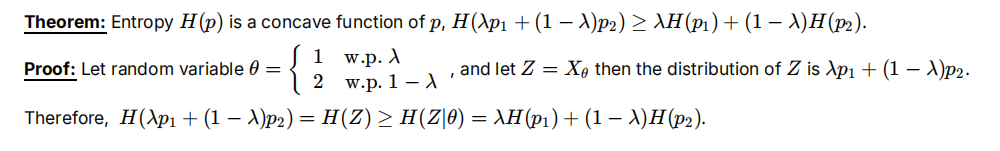
互信息有凸有凹

证明互信息的凹凸性:
- 当p(y|x)固定时,看作常数,第一项是关于p(x)的线性项(无关凹凸可忽略),第二项是关于p(x)的凹函数,因为是-p(x)logp(x),即-xlogx,是凹函数

- 另一种证法是证明H(Y)关于Px(x)是凹函数(式子还是不太懂)

当p(x)固定时,看p(y|x)的凹凸性,用p1/p2/DL的性质推得I(X;Y~)满足凸函数


数据处理不等式
马尔可夫链/互信息形式
X-Y-Z:指X,Z在给定Y的条件下是条件独立的。Y仅取决于X,Z仅取决于Y:“无记忆性”
- 当Z=f(Y)时,根据马尔科夫链的性质X-Y-Z,即X/Y/Z形成马尔科夫链。这是因为Z对X的依赖完全通过Y来传递,与直接从X获取信息无关。
- 例如,如果Y表示一个人的身高,f是一个将身高转换为适合的衣服尺码的函数,那么Z就表示这个人适合的衣服尺码。在这种情况下,衣服尺码Z完全由身高Y决定。
条件独立性:Y已知时,XZ独立,所以XZ|Y=X|Y*Z|Y
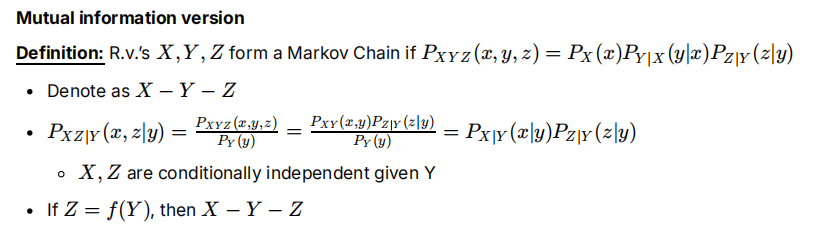
性质:关注I(X;Z|Y)=0
马尔科夫链满足时,条件使互信息减少


补充习题:因为有X-Y-f(Y),所以有Y-X-f(X)

KL散度形式
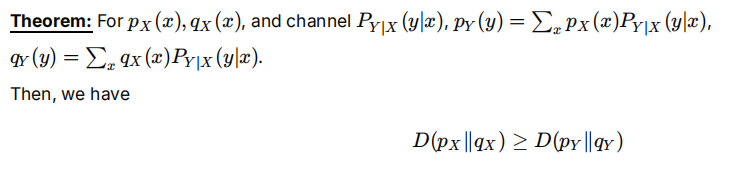
Py|x:信道,信息从发送端 到接收端,给定X输出Y
该定理保证输出分布差异不会大于输入分布,K-L不会增加。用来衡量信道传输过程的信息损失。
证明的关键是加上y,往信道转换,然后利用jensen。负号很巧妙。
注意有qxy=qx*P(y|x),所以满足边缘分布\sum_x(qxy)=qy
为什么把Py留到前面,当然是为了符合最终D(py||qy)的形式要求

Lec4 渐进均分性
在信息论中,大数定律的类比是渐近均分性质(AEP)。这是弱大数定律的直接结果。这使得我们能够将所有序列的集合分成两个集合,一个是典型集合,其中样本熵接近真实熵,另一个是非典型集合,其中包含其他序列。我们的大部分注意力都将集中在典型的序列上。任何为典型序列被证明的性质都将是高概率的,并将决定一个大样本的平均行为。
弱大数定律

随机变量Z[μ-ε,μ+ε]落在区间的概率为1
渐进均分性定理AEP
意思是采样Z1…Zn,再定义集合S,满足||>ε的概率很小

典型集
典型集A:含有多个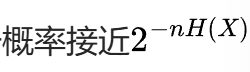 的序列x^n(高概率序列),每个序列x^n(x1…xn)满足下列不等式
的序列x^n(高概率序列),每个序列x^n(x1…xn)满足下列不等式
P(A_ε^n)=ΣP(x^n)=ΣP(x1…xn)
在n足够大(趋近于∞时),P(A_ε^n)=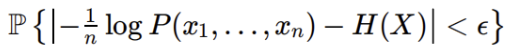
- 因为元素组成x^n是序列,满足式子的元素组成的集合就是P(A_ε^n)

性质2:当n足够大时,P(A_ε^n)无限接近于1
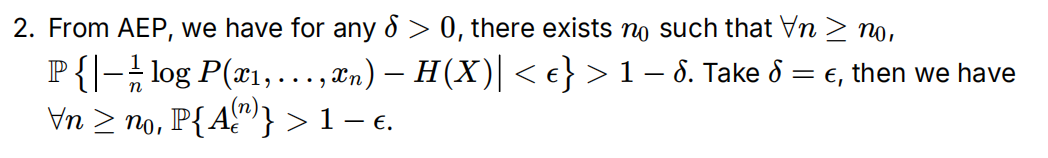
性质34:下界是1-ε,上界是1,进行缩放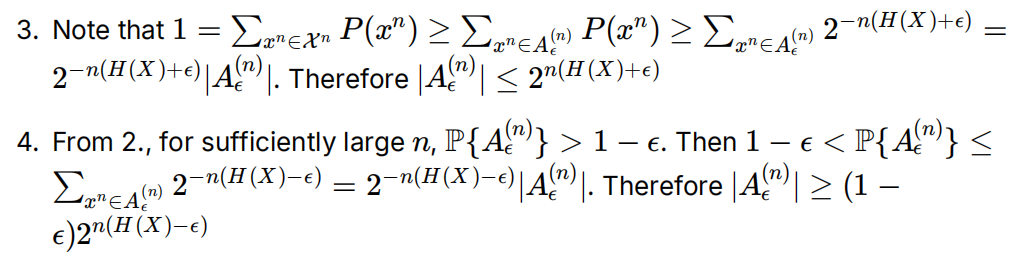
数据压缩
数据压缩可行性的理论基础
信道编码希望把独立同分布的x映射成比特数据,还可以解码。
x1….xn编码成b1…bm,最少需要m位编码,m是多少?
可能的序列数量是|X|^n,其中|X|是集合X中元素的数量。这是因为序列中的每个位置都可以由 X 中的任何元素填充,并且有n个位置。如果描述所有序列,需要: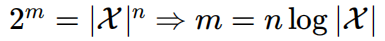
然而我们不需要描述所有序列,描述典型集即可(因为他们发生的概率高)在典型集里的序列seq.被称为典型序列
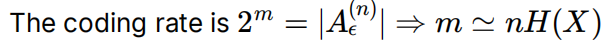
香农信源编码定理
当
证明不能用小于m的比特编码:
定义高概率集合
 ,不用典型集而用高概率集合的原因是更符合简化编码问题时的初衷,不过我感觉这个定义就是典型集
,不用典型集而用高概率集合的原因是更符合简化编码问题时的初衷,不过我感觉这个定义就是典型集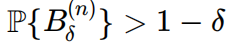
证明:通过展示在高概率集合或典型集中,序列的数量超过了 2^m的特例即可反驳
dot equal
看指数速率,而不是看多项式,后面假设检验会用

Lec5 微分熵
方便研究logf(x),所以针对S集合
f(x)就是概率密度函数,对应P(x)

感觉与离散相比,除了熵可能为负,其他形式和性质都是一样的
别忘了写dx/dy
微分熵
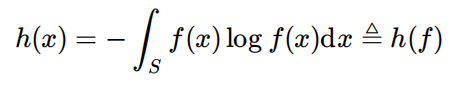
可能为负,不像香农熵一定非负。
注意可以写作h(f),代表PDF为f(x)
例题:计算高斯分布的h(f)。注意复杂的求积分直接用公式。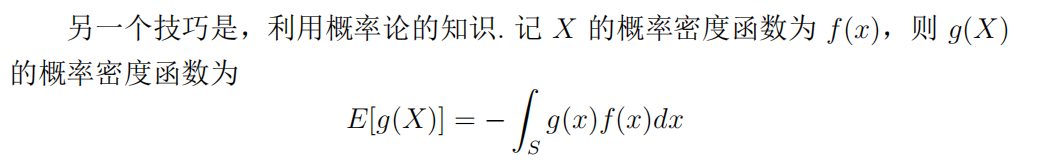

性质:两道题都是用Y=X+c,Y=aX替换,然后将fY和fX联系起来(推导f时对F(y)求导)


对于香农熵,性质2不成立:说明缩放不影响H,因为度量的是概率分布的均匀性或分散程度,而不是具体的数值大小

联合熵
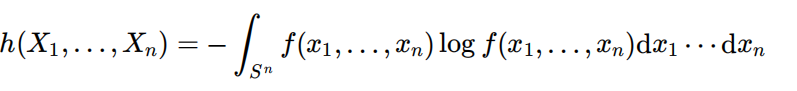
条件熵

很可能考试的题目:

AEP

典型集
似乎比离散那里<=多了个=

KL散度
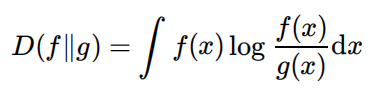
注意dx 是从第一个分布(N(m1,Σ1))取样的,因为 KL 散度定义中,积分是对p1(x)进行加权的。lage
互信息

jensen不等式对连续熵一样成立,所以一些性质基本是一样的

高斯最大熵
证明熵最大的时候是均匀分布。
证明非常巧妙地使用了高斯分布E与具体概率分布无关的性质,通过D构造不等式以及h(f)也十分巧妙。

Lec6 假设检验
在广泛的应用中,人们必须根据一组观察结果来做出决定。我们希望使用一个在适当意义上尽可能好的决策过程。解决这些问题是决策理论的目的,而建立这类问题的自然框架是基于假设检验。在这个框架中,每个可能的场景都对应于一个假设。今天的讲座的目的是介绍假设检验的概念。
过程
1. 假设
m种可能的取值(标签),离散
有先验分布,是没做观察之前的知识,属于原假设H0

2. 观察
利用反证法的思想,先假定第一步的假设是成立的。如果实际从样本中观察到的情况在这个假设下 是不合理的,就认为原来的假设是不正确的,拒绝原来的假设。 如果样本没有不合理现象,就不能拒绝原来的假设。
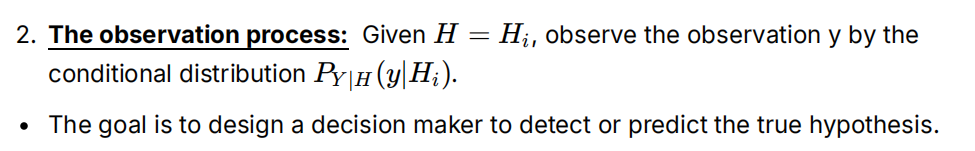 给定一个假设 H=Hi,观察到的数据 y 是通过条件分布P(Y∣H) 得到的。这意味着在每个假设下,观察到的数据 y 的概率分布是不同的
给定一个假设 H=Hi,观察到的数据 y 是通过条件分布P(Y∣H) 得到的。这意味着在每个假设下,观察到的数据 y 的概率分布是不同的
3. 决策制定
虽然第一步假设集也只是人为建模,不完全正确,但已经是对实际情况的最佳建模尝试,所以我们希望f(y)可以映射到H。
使用指示函数表示判对概率和判错概率

两个统计决策
最大后验MAP
目的:在给定观察数据 y 的情况下,选择后验概率最大的假设 Hi。监督式学习基于该原理。
- 没有观察数据 y 时:选择先验概率最大的假设,即选择 H 使得 P(H=Hi)最大。
- 观察到数据 Y=y 时:使用贝叶斯定理计算后验概率,并选择后验概率最大的假设。

风险最小化决策
目的:在给定观察数据 y 的情况下,选择使得期望成本最小的决策规则。
f(y)是预测值,H是真实值,最小化预测错的代价

二元假设检验/似然比检验/对数似然比检验
二元假设检验则是上述决策规则在特定情况下(即只有两个假设)的应用。使用先验+观测内容选择二分类预测的结果。最好的决策模型f(y)满足:
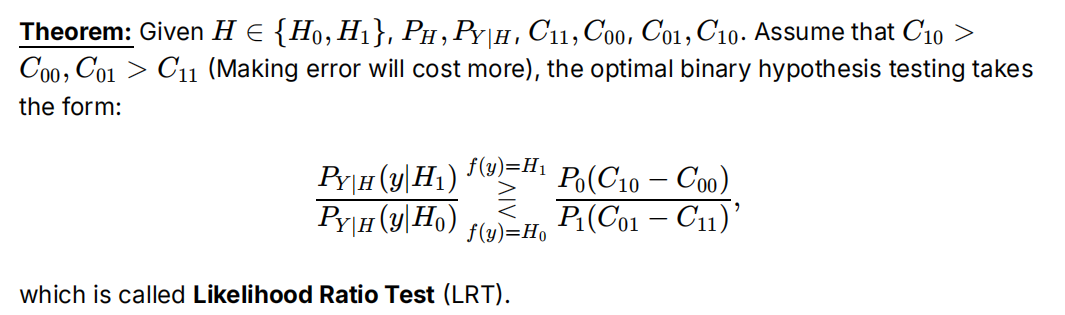
证明疑似使用全期望公式和指示函数,巧妙地可以比较两项选小的

使用到假设地:判错的代价>判对。除法效率低,可以取对数

左式: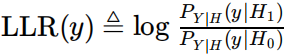
实际应用:信道传递时有噪声干扰w,s是原始信号,最终收到y后判断最初传的是s0还是s1。用公式计算LLR(y)即可

多维高斯分布时:

期中复盘
假设检验不太熟
作业3
多元高斯分布的性质:其中,用到了期望和迹可交换的性质。注意E[XX^T]和E[X^TX]不一样!
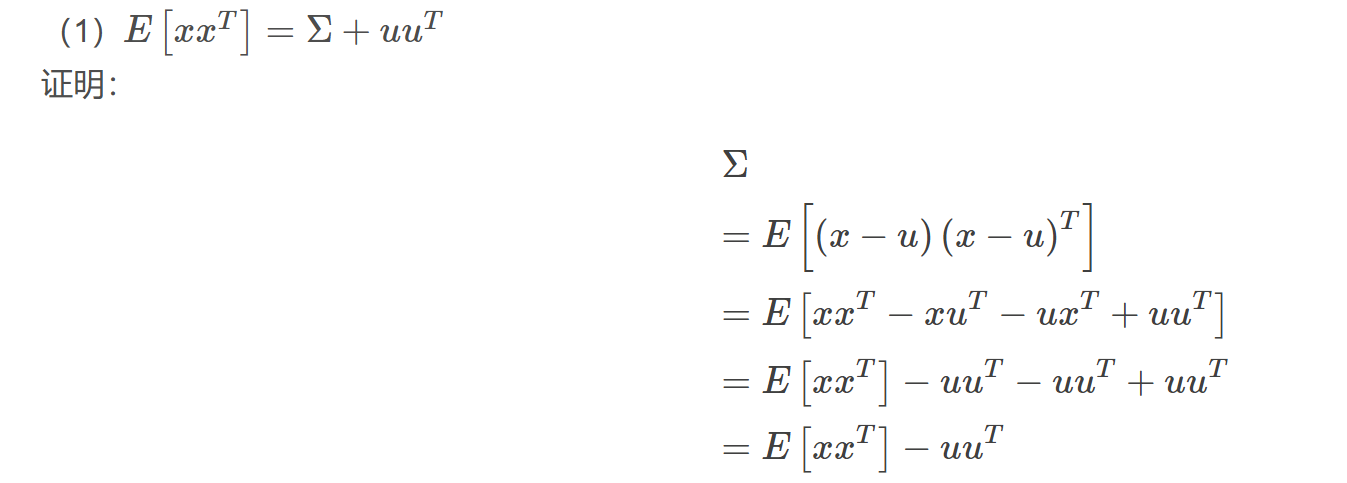

对实数加trace不改变值本身,如X^TAX就是一个实数(标量)
我们知道研究信息几何有两个强烈的动机。首先是:一对统计模型,即概率分布的线性族和指数族,在信息几何中发挥着重要作用。它们是双重平坦的,因为前者相对于 m 连接是平坦的,后者相对于 e 连接是平坦的,并且这两个连接相对于 Fisher 度量是彼此对偶的(参见Amari 和 Nagaoka) ,2000 年,第 2.3 节和第 3 章)。我们建议读者参考Kurose (1994)和Matsuzoe (1998) ,以进一步了解黎曼几何中二元结构的重要性。即使没有黎曼几何,线性族和指数族之间的密切关系也是已知的。这两个族被证明是彼此“正交”的,因为指数族与相关线性族在一个点以直角相交,即关于KL 散度的毕达哥拉斯定理在该点成立交叉口。
Lec7 type
在信息论中,我们特别关注假设检验的渐近性质。为了评估这一点,我们需要类型的方法,这是在大偏差理论中的一个强大的技术。我们使用类型的方法来计算罕见事件的概率,并推导出此类问题的最佳可能的误差指数
用重复观察进行的二元假设检验
似然比:在假设H0/H1时观测到样本的联合概率。由于样本是独立同分布的,可以将联合概率表示为单点概率的乘积

评估假设检验的性能指标:1假阳性,2漏检。2更严重

Pe是假设检验系统总共的错误概率:为了刻画Pe,关注n很大时,方便描述收敛速率刻画错误指数->为了计算提出Sanov’s定理


Method of types经验分布Q
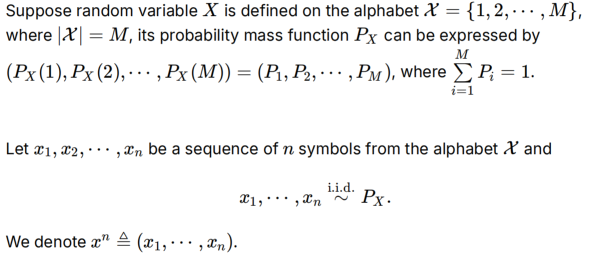
序列的type(Px):看每种x^n取值出现几次,是序列的经验分布。每个元素必然是出现次数/序列长度

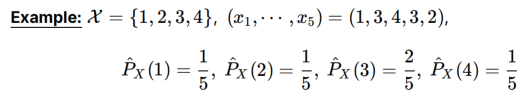
Pn:经验分布Q的集合,包含多个Q,比如上面的例子是一个Q。Q的序列长度为n,|X|=M是取值的个数

Tq:经验分布为Q的序列x^n的集合,称之为分布Q的type class

dot equal,典型集的大小和概率
指数级的相等:因为后面典型集的大小、概率,Sanov定理都用指数级相等
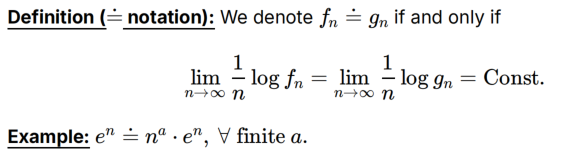
type class的大小:

证明:已知固定的经验分布,和斯大林不等式,以及dot equal多项式不影响,与指数无关(技巧是把n^a形式写成e指数形式)
type class的概率:已知经验分布为Q,生成分布为P,x^n从P取样,分布为Q(PQ应该很相似)
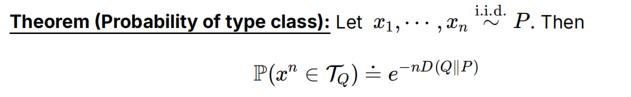
证明:找出所有分布为Q的x^n序列,概率是每位的p相乘,每个取值出现次数又可以根据nQi得到,|X|是取值的个数
- 巧妙地将x^n的概率P(x_i)化为取值范围的概率P(i)
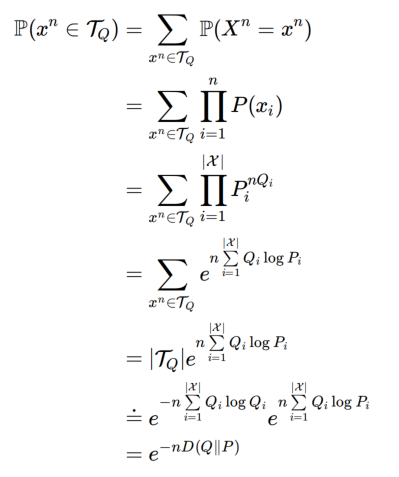
Sanov’s Theorem
已知序列x从生成分布P中取样,实际分布为P_hat(经验分布)。Q用来近似P_hat的分布,Sanov’s Theorem 会从集合S中找到一个Q^*,使得它在 K-L 散度意义上最接近 P

证明:当n足够大时,允许省略Pn,认为Pn是全集

课后理解:
根据cover’s book:用拉格朗日乘子法求得最优的Q

参考:https://web.stanford.edu/class/ee376a/files/2017-18/lecture_14.pdf
https://www.cnblogs.com/zxyfrank/p/16414518.html#sanov%E5%AE%9A%E7%90%86
Lec9 Chernoff-Stein Theorem
Sanov’s Theorem

线性族:把Q看成变量,f(x)看成系数
指数族是通过P0(x)和P1(x)两个基准分布构造的分布族

通过拉格朗日乘子法,如果在概率分布Q满足约束 EQ[f(X)]=γ(即f(X)的期望值等于 γ)的条件下最小化Q和P0之间的KL散度,那么Q是服从指数族的,即是交点
- f(x)由P1,P0决定,s由γ决定,γ根据垂直时求得
- αn的证明在后面
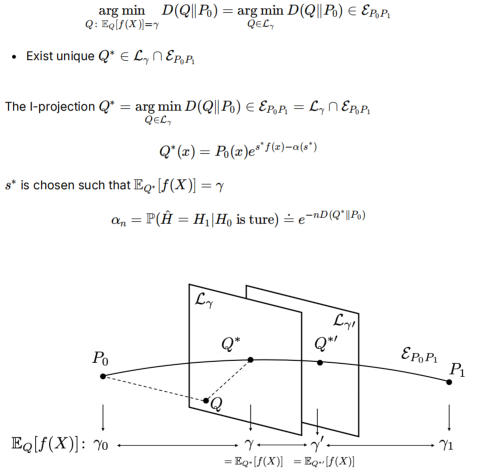
证明Q*的Pythagoras Identity,类似勾股定理:利用Q*是指数族的性质
- Q*的求和是1,因为是概率分布

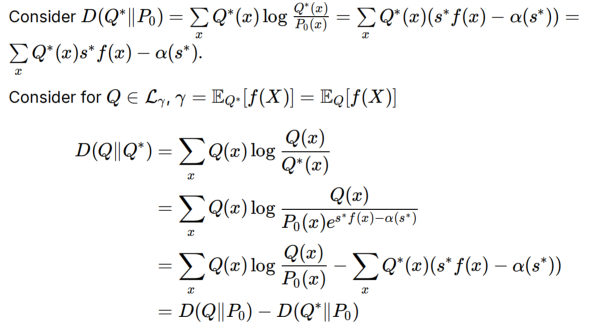
求解type i/ii
证明Type I error αn:在证明时经常将n变成|X|,这样与Q(x)产生联系
- 通过拉格朗日乘子法,证明最小时的解是指数族

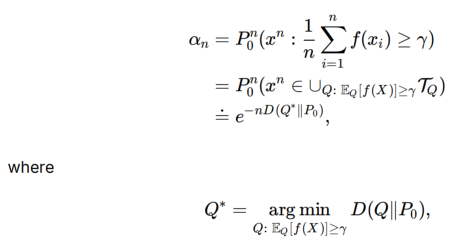
- 这一步从x^n∈Tq到e就像sanov证明一样,取了最大值
接下俩利用拉格朗日求解线性族和指数族交点Q*需要满足的形式: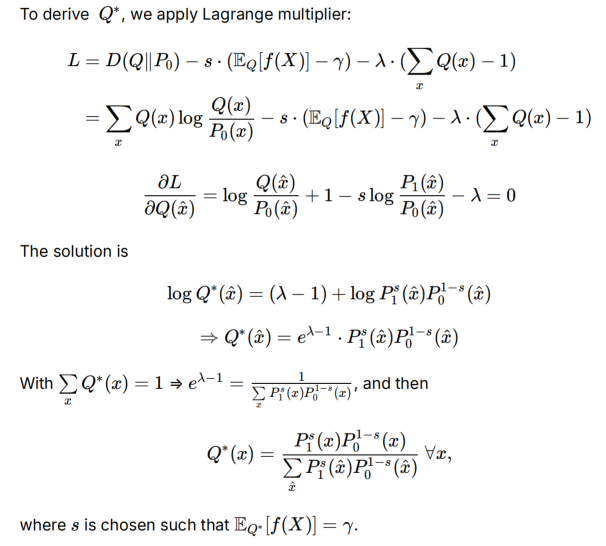
同理可以求得type ii error:

注意上述内容均基于最开始Q满足线性族(因为LLRT的形式变形得到的就是线性族)
Error probability使Pe最小
贝叶斯/chernoff-stein定理

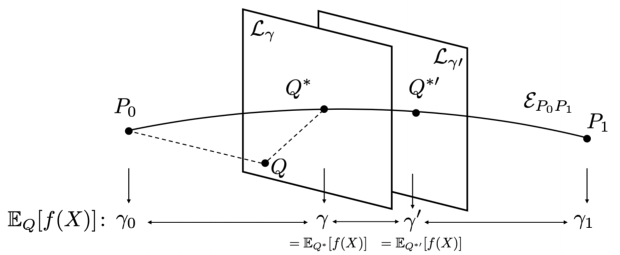
Q*到P0是Type I Error,到P1是Type II error,要使Pe最小,即让平面落在中间,使I和II相等

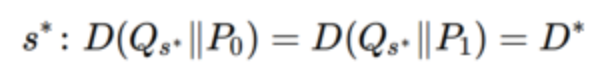
Neyman-Person方法
研究在第一类错误αn小于某一阈值η(η不依赖于样本数n)的条件下,第二类错误 βn 的最优衰减速率。
- 最优衰减速率指的是随着样本数量增加,错误概率的衰减速度(希望最快)

Lec11 Non-Bayesian Parameter Estimation
注:在许多估计问题中,将感兴趣的潜在变量分配一个先验分布可能是不自然的,因此不能使用贝叶斯框架。在这种情况下,另一种方法是将变量视为确定性的,但是未知的。在这种情况下,观察模型不是以潜在变量为条件的分布,而是由该变量参数化的分布。

传统的贝叶斯模型中,观察模型通常是条件概率分布,表示在给定潜在变量的情况下,观察到数据的概率。而在这种“确定性但未知”的设置下,观察模型则被参数化为潜在变量的函数。这意味着,我们在处理数据时,不再将潜在变量视为随机变量,而是将其作为模型中的一个未知参数进行估计。
估计值、偏差、协方差
用观察到的y估计x:

定义偏差和误差协方差矩阵:
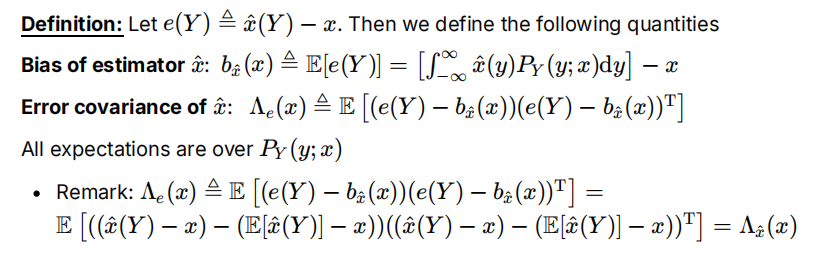
证明:均方误差=随机误差 (协方差)+系统性误差 (偏差平方)
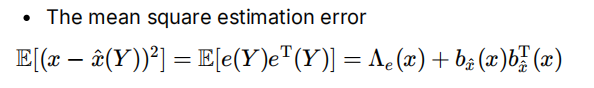

无偏估计
如果偏差为零,意味着估计量的期望值等于真实值 x

E[e(Y)]=0
单个观测值的无偏估计:
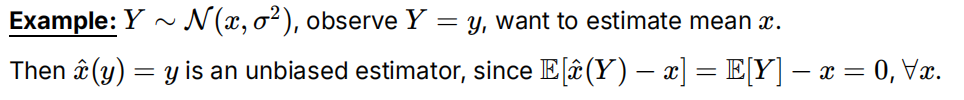
多个独立同分布观测值的无偏估计:
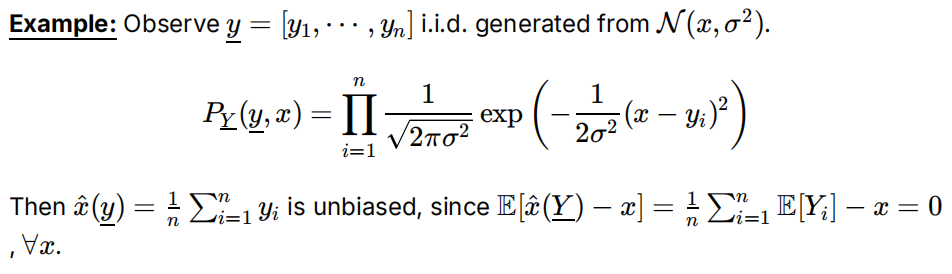
注意这里正着推导说明x(y)是其中一个估计量,但估计量是存在多个的,期望相同,方差不同,取到最小方差的才叫做MVU

最小方差无偏估计量MVU
正则化定义: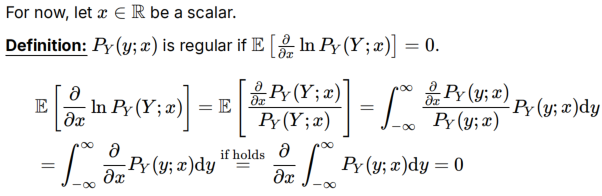

积分和导数可交换顺序的条件:P大于0且在x上连续可微(可微和可导等价)

所以正则化条件和E[]=0是充要关系
如果Py为正则,x(Y)又为无偏估计量,可以得到方差的下界
Cramer-Rao bound
提出方差拥有下界:

证明不断使用无偏和正则的前置条件,利用相关系数的取值范围是因为cov=1已求,var方差因为E[X]=0可以转为E[X^2]的形式,与定义的λ和Fisher信息量J_Y(x)产生关联
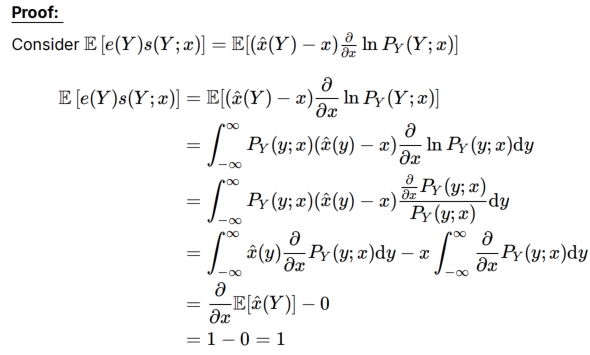
证明过程:无偏和正则都是充要条件(相关系数衡量两个随机变量之间的线性相关程度,范围在[−1,1])
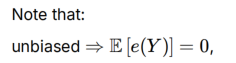
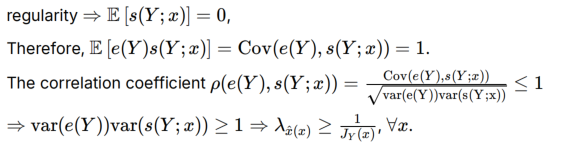
取得最小方差时,相关系数ρ=1,e和s正相关,k(x)其实大于0,λ最小,对应得到此时的无偏估计值x
例题:求解最小方差无偏估计量,利用了下面的平方展开公式
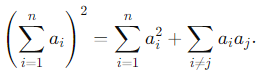
首先获得方差的范围,然后这里求解了一个无偏估计量,代入正好是最小方差,说明找到了MVU,同时可以解k(x)
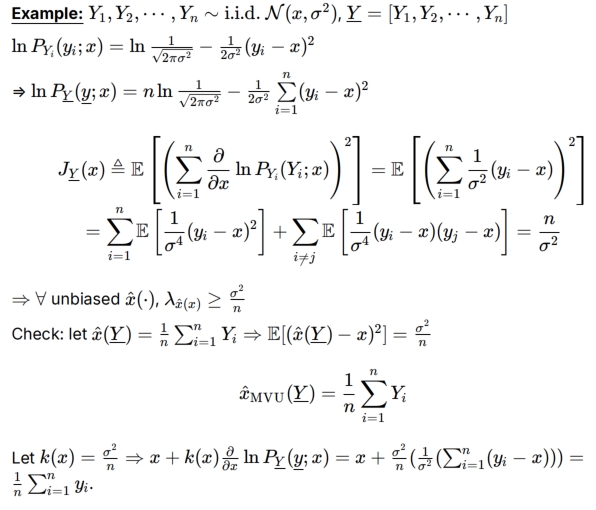
Efficiency高效估计量
一个无偏估计是高效的当且仅当它取到了最小方差,并且k(x)=1/J=Var(x(Y))就是方差本身
eff与MVU的对比
- eff强调了不能依赖x,mvu没提,只是满足方差最小,感觉可以分段
- eff必须达到bound,可以为多个;MVU不一定达到bound,在全范围最小即可,但只有一个
证明使用了前文的E[e(Y)s(Y;x)]=1

这里的假设并不是真实的x就等于极大似然的估计xML,而是想要与x无关,xML仅根据Y估计,并可以利用导数为0的性质,所以假设成x
极大似然估计量(使观测值Y出现概率最大,导数为0)
- 既然上面的corollary中x是未知的真实值,这里可以替换成xML仍然成立看起来很奇怪。
- 可能因为假设了eff存在,总能表达成这种形式,其中右式替换成一个x的估计值后不依赖x即可,比如x选argminPy也算不依赖,式子可以成立?(不是很懂能推广到多少估计值,但这么想的话这个证明就没那么奇怪了,不要纠结在这里了)


Lec12 充分统计量
在许多情况下,观察到的数据可以有一个非常大的维度。因此,直接基于此类数据执行推理可能相当麻烦。因此,一个有吸引力的推理架构包括首先对数据进行预处理,以获得更紧凑的数据集,我们从中进行推断,而不是直接从数据本身进行推断。

Y是高维的,我们希望从Y中学习低维的f(Y)作为更紧凑的数据集,来预测X
f(Y)是充分统计量,希望丢失冗余的信息,把精华特征X提取出来,保留f(Y)即可
非贝叶斯case
t(Y):从数据Y中得到的统计量,是Y的函数,可能是“多对一”的函数映射。

t(Y)如果是s.s,则y与x的关系可用t(y)代替,则PY|T与x无关,通过i推导可以算PY|PT
- 在概率论和统计学中,边缘分布是指对于多个随机变量的联合分布,只考虑其中一个或几个随机变量的分布情况。联合=条件*边缘,边缘=联合+对另一个变量求积分
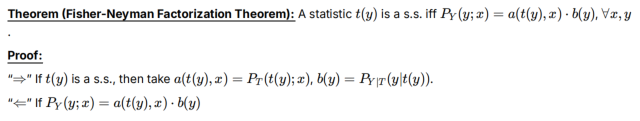
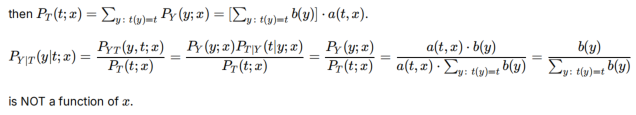
Fisher定理:注意用t(y)=t来求解PT
高斯问题:用线性特征一般有用,这里t从二维降维到了一维

直接令等于y本身当然也是s.s,但是没有任何预处理,没啥用处
下面是写成a*b的形式,证明t是s.s

作业的一个结论:
贝叶斯case
注意灵活地增加和删除T和Y,在多处使用
以及条件概率公式PXY=PX*PY|X多given一个Z也可以,也多次使用在证明中
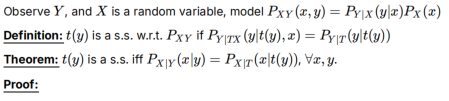
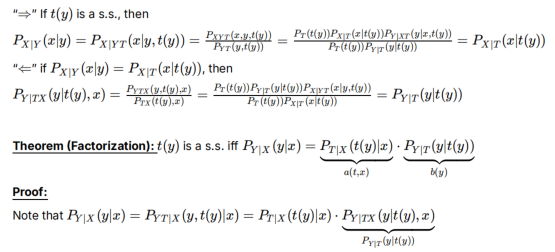
第一个是定义,后面是根据定义得到的定理
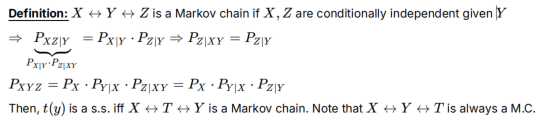
如果X-T-Y组成马尔科夫链,则t(y)=T是s.s
因为X-Y-T永远成立,利用Lec6证明过的s.s性质:

Lec14 HGR Maximal Correlation
HGR相关性是统计学中的相关度量。与常用的相关性相比,它具有处理非线性统计依赖性的优势。HGR的最大相关性可以通过ACE(替代条件期望)算法来计算。
给定2个离散的随机变量X,Y,想要测量X和Y之间的相关性,我们能怎么做?
Pearson相关系数
问题是=0时不一定独立,只能说明不相关。但独立时一定等于0
取值范围为[-1,1],+-1时XY线性相关

Renyi认为的好的度量:可交换、归一化、XY独立是ρ=0的充要条件、对于任意函数关系(比如η)都满足完全相关的关系、XY和函数一对一映射后,只是变量名字变了,概率分布不变
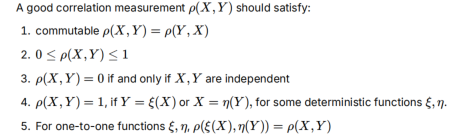
对于pearson的绝对值:12满足,3不满足(0不一定独立)、4不满足(只是满足线性关系,不是任意函数关系)、5不满足(对X或Y进行非线性单射变换(如平方),Pearson 系数可能会发生变化)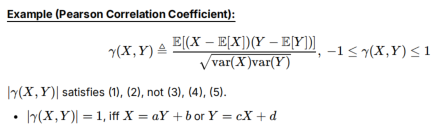
对于互信息:1满足,2不满足(互信息I>=0,可以很大),3满足(I=0->XY独立),4不满足(1在互信息中没啥特别的)、5满足(对于单射函数变换互信息值不会改变)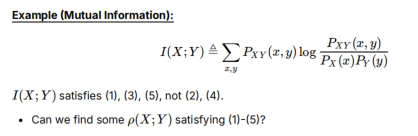
HGR 最大相关性
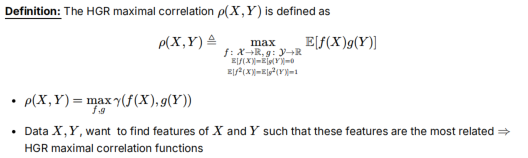
希望找到X和Y之间最相关的特征
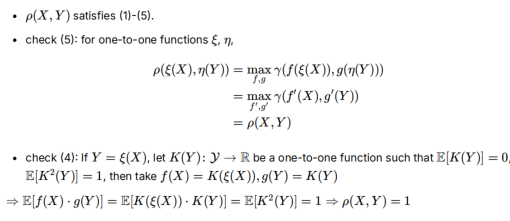
1-5均满足:1对称,2范围在[0,1],3=0时f(X)和g(Y)间的任何统计相关性都会为0(最复杂,用依赖矩阵B来证),XY独立,5变成f’/g’,4对于任意的函数关系,可以找到特殊的f与g使得ρ=1(利用了单射变换K的概率分布不会变的性质)
- 注意单射变换的概率分布不会改变,所以f’,g’仍然有均值为0,方差为1的性质,满足HGR的前提条件
HGR=典型依赖矩阵B的最大奇异值

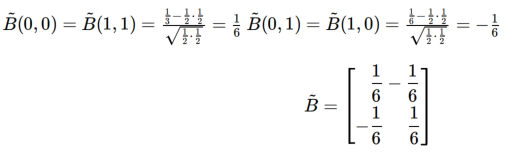
典型依赖矩阵B的定义:PXY为联合分布,PX/PY为边缘分布
定义两个与f(x)和g(y)相关的信息向量:ϕ,ψ,为后面的证明做准备
性质:l2-norm-square=1,inner product=0


特征值有些矩阵没有(只有方阵有det(A−λI)=0),奇异值所有矩阵都有A=UΣVT,其中奇异值σi是Σ中的对角线元素,满足:σi=\sqrt{λi}
- 这里λi是矩阵ATA的非负特征值
HGR可以用ϕ,ψ,B一起表示,ρ=max…
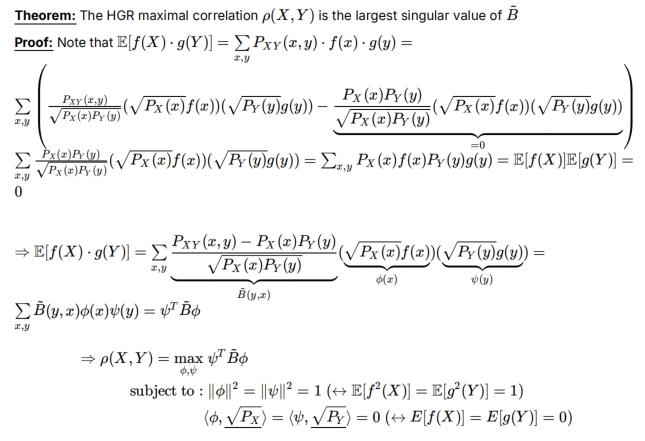
证明fact1:
- 先证B的左奇异向量和右奇异向量是Px和Py(其实我不懂这一步到ρ=σ的逻辑)
- 再根据奇异值分解的性质,构造专门的f*/g*让ϕ,ψ作为最大奇异向量,因为与Px/Py正交所以是可行的
- 可以用=B的最大奇异值来证HGR满足ρ=0->XY独立
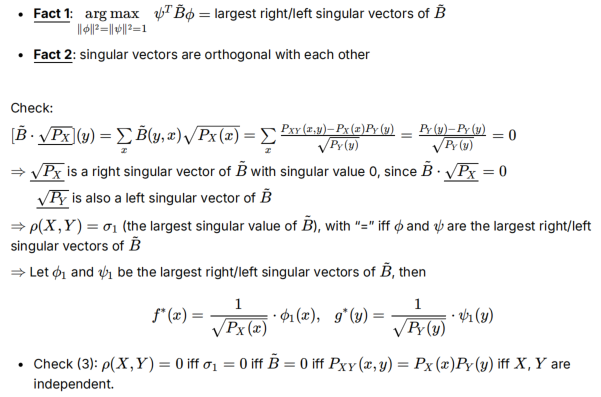
- 注意这里证明时用了[](y),这样只用取某一项标量,比较方便运算,把y当作已知量
奇异值分解的性质:奇异值非负


