踩坑参考:Langchain AI 练中学 踩坑记录(00-03) | 豆包MarsCode AI刷题在这几天的课程学习中,我在 - 掘金
1. 开篇词
LangChain:以大模型为引擎的全新应用开发框架
作为一种专为开发基于语言模型的应用而设计的框架,通过LangChain,我们不仅可以通过API调用如 ChatGPT、GPT-4、Llama 2 等大型语言模型,还可以实现更高级的功能。
具备以下两个特性:
- 数据感知: 能够将语言模型与其他数据源连接起来,从而实现对更丰富、更多样化数据的理解和利用。
- 具有代理性: 能够让语言模型与其环境进行交互,使得模型能够对其环境有更深入的理解,并能够进行有效的响应。
因此,LangChain框架的设计目标,是使这种AI类型的应用成为可能,并帮助我们最大限度地释放大语言模型的潜能。
LangChain是一个基于大语言模型(LLMs)用于构建端到端语言模型应用的框架,它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人等。LangChain提供了一系列工具、套件和接口,可以简化创建由LLMs和聊天模型提供支持的应用程序的过程。
应用 1:情人节玫瑰宣传语
第一步是安装三个包,通过 pip install langchain 来安装LangChain,通过 pip install openai 来安装OpenAI,还需要通过 pip install langchain-openai 以便在 LangChain 中使用 OpenAI 模型。
第二步,你还需要在OpenAI网站注册属于自己的OpenAI Key。(当然,LangChain也支持其他的开源大语言模型,但是推理效果没有GPT那么好,所以我们这个课程里面的大多数示例都是用OpenAI的GPT系列模型来完成。)
1 | import os |
应用2:海报文案生成器
已经制作好了一批鲜花的推广海报,想为每一个海报的内容,写一两句话,然后post到社交平台上,以期图文并茂。
gpt不能读图,所以用图像字幕生成
我们就用一段简单的代码实现上述功能。这段代码主要包含三个部分:
- 初始化图像字幕生成模型(HuggingFace中的image-caption模型)。
- 定义LangChain图像字幕生成工具。
- 初始化并运行LangChain Agent(代理),这个Agent是OpenAI的大语言模型,会自动进行分析,调用工具,完成任务。
不过,这段代码需要的包比较多。在运行这段代码之前,你需要先更新LangChain到最新版本,安装HuggingFace的Transformers库(开源大模型工具),并安装 Pillow(Python图像处理工具包)和 PyTorch(深度学习框架)。
1 | pip install --upgrade langchain |
1 | # ---- Part 0 导入所需要的类 |
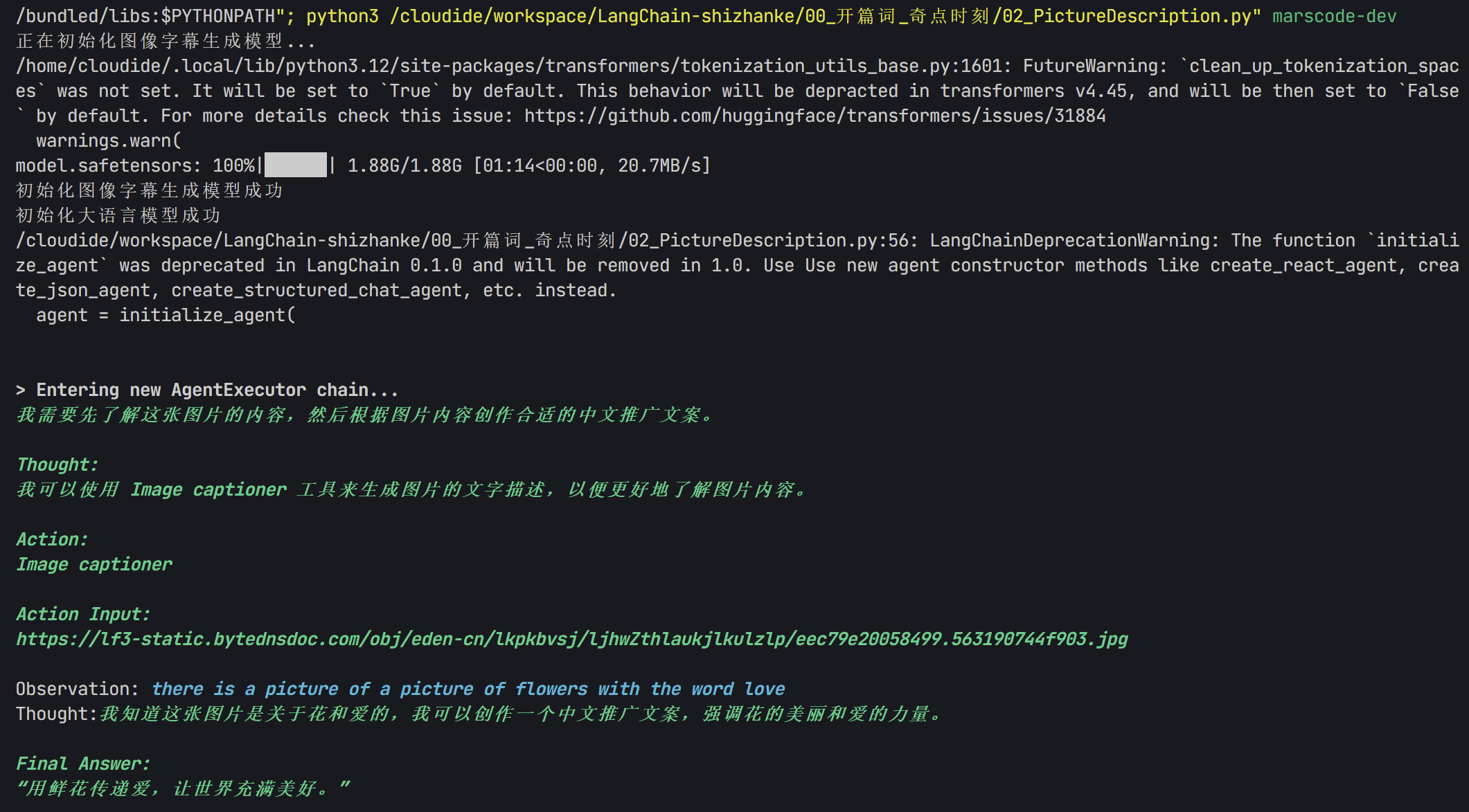
针对上面的鲜花图片,程序进入了AgentExecutor链,开始思考推理,并采取行动——调用Image Cationer工具,接收该工具给出的结果,并根据其返回的内容,再次进行思考推理,最后给出文案。
当然,这个过程中还有很多很多的细节,比如大模型是怎么思考的?LangChain调用大模型时传入的具体提示文本是什么?代理是什么?AgentExecutor Chain 是什么?它究竟是怎样调度工具的?你现在可能有很多的疑惑。
2. Langchain系统安装和快速入门
可以将大语言模型想象成一个巨大的预测机器,其训练过程主要基于“猜词”:给定一段文本的开头,它的任务就是预测下一个词是什么。模型会根据大量的训练数据(例如在互联网上爬取的文本),试图理解词语和词组在语言中的用法和含义,以及它们如何组合形成意义。它会通过不断地学习和调整参数,使得自己的预测越来越准确。
- 这种预测并不只基于词语的统计关系,还包括对上下文的理解,甚至有时能体现出对世界常识的认知
- 并不完全理解语言,它们没有人类的情感、意识或理解力。它们只是通过复杂的数学函数学习到的语言模式,一个概率模型来做预测,所以有时候它们会犯错误,或者生成不合理甚至偏离主题的内容
LangChain 是一个全方位的、基于大语言模型这种预测能力的应用开发工具。支持Python和JavaScript两个开发版本。
- 预构建链功能
- 模块化组件
- LangChain 要与各种模型、数据存储库集成,比如说最重要的OpenAI的API接口,比如说开源大模型库HuggingFace Hub,再比如说对各种向量数据库的支持
- https://github.com/langchain-ai/langchain
- LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些API,搭建起来的一些框架、模块和接口。
Chat模型和Text模型
OpenAI:先得到API Key。TPM和RPM分别代表tokens-per-minute、requests-per-minute。也就是说,对于GPT-4,你通过API最多每分钟调用200次、传输40000个字节。
Text Model,文本模型:OpenAI的Completions API已被废弃,被ChatCompletion接口替代,仅作示意(运行会报错,因为API废弃的原因)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import os
from openai import OpenAI
# os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'
# os.environ["OPENAI_BASE_URL"] = 'OpenAI 的 API URL'
client = OpenAI()
response = client.completions.create(
model=os.environ.get("LLM_MODELEND"),#如"gpt-3.5-turbo-instruct"
temperature=0.5,#影响输出的随机性
max_tokens=100,#限制输出的最大长度,一个token可以是一个字、一个词或一个字符,取决于模型
prompt="请给我的花店起个名",#提示,输入的问题,要做什么
)
print(response.choices[0].text.strip())#choices是所有输出,一般就一项,strip去掉前后空格Chat Model,聊天模型。有两个专属于Chat模型的概念,一个是消息,一个是角色
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import os
from openai import OpenAI
# os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'
# os.environ["OPENAI_BASE_URL"] = 'OpenAI 的 API URL'
client = OpenAI()
# text = client.invoke("请给我写一句情人节红玫瑰的中文宣传语")
response = client.chat.completions.create(
model=os.environ.get("LLM_MODELEND"),
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名"},
],
temperature=0.8,
max_tokens=600,
)
print(response.choices[0].message.content)消息就是传入模型的提示。此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
在OpenAI的Chat模型中,system、user和assistant都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
在使用Chat模型生成内容后,返回的响应,也就是response会包含一个或多个choices,每个choices都包含一个message。每个message也都包含一个role和content。role可以是system、user或assistant,表示该消息的发送者,content则包含了消息的实际内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}
Chat模型 vs Text模型
相较于Text模型,Chat模型的设计更适合处理对话或者多轮次交互的情况。这是因为它可以接受一个消息列表作为输入,而不仅仅是一个字符串。这个消息列表可以包含system、user和assistant的历史信息,从而在处理交互式对话时提供更多的上下文信息。
这种设计的主要优点包括:
- 对话历史的管理:通过使用Chat模型,你可以更方便地管理对话的历史,并在需要时向模型提供这些历史信息。例如,你可以将过去的用户输入和模型的回复都包含在消息列表中,这样模型在生成新的回复时就可以考虑到这些历史信息。
- 角色模拟:通过system角色,你可以设定对话的背景,给模型提供额外的指导信息,从而更好地控制输出的结果。当然在Text模型中,你在提示中也可以为AI设定角色,作为输入的一部分。
然而,对于简单的单轮文本生成任务,使用Text模型可能会更简单、更直接。例如,如果你只需要模型根据一个简单的提示生成一段文本,那么Text模型可能更适合。从上面的结果看,Chat模型给我们输出的文本更完善,是一句完整的话,而Text模型输出的是几个名字。这是因为ChatGPT经过了对齐(基于人类反馈的强化学习),输出的答案更像是真实聊天场景(Chat模型)。
对齐
在训练大语言模型时,模型可能会生成一些不符合人类期望的内容,例如:
- 输出内容不准确、不相关或不完整。
- 生成有害、偏见性或不当的回答。
- 回答缺乏上下文理解,显得机械化或不自然。
这些问题可能源于以下原因:
- 模型的目标函数(如最大化语言概率)并不完全等同于人类的实际需求。
- 训练数据中可能存在偏差或噪声。
- 模型缺乏对复杂社会规范和人类价值观的理解。
为了克服这些问题,研究者引入了“对齐”的概念,通过调整模型的行为,使其输出更加符合人类的期望。
对齐的一个关键实现方法是 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF) 。这种方法通过以下几个步骤来优化模型:
(1) 收集人类反馈
- 在模型生成回答后,人类评估者会对模型的输出进行评分或排序,指出哪些回答更好、更符合人类期望。
- 例如,对于一个提问,模型可能生成多个候选答案,人类评估者会选择最自然、最有用的答案。
(2) 构建奖励模型
- 根据人类反馈,构建一个“奖励模型”(Reward Model),用于量化模型输出的质量。
- 奖励模型会为每个生成的回答分配一个分数,分数越高表示回答越符合人类期望。
(3) 强化学习优化
- 使用强化学习算法(如 PPO,Proximal Policy Optimization),让模型根据奖励模型的反馈逐步调整其行为。
- 在这个过程中,模型会学习如何生成更高质量、更符合人类期望的回答。
通过 LangChain 调用 Text 和 Chat 模型
Text:
1 | import os |
Chat:
1 | import os |
无论是langchain.llms中的OpenAI(Text模型),还是langchain.chat_models中的ChatOpenAI中的ChatOpenAI(Chat模型),其返回的结果response变量的结构,都比直接调用OpenAI API来得简单一些。这是因为,LangChain已经对大语言模型的output进行了解析,只保留了响应中最重要的文字部分。
大语言模型可不是OpenAI一家独大,知名的大模型开源社群HugginFace网站上面提供了很多开源模型供你尝试使用。就在我写这节课的时候,Meta的Llama-2最受热捧,而且通义千问(Qwen)则刚刚开源。
两点提醒,一是这个领域进展太快,当你学这门课程的时候,流行的开源模型肯定变成别的了;二是这些新的开源模型,LangChain还不一定提供很好的接口,因此通过LangChain来使用最新的开源模型可能不容易。
不过LangChain作为最流行的LLM框架,新的开源模型被封装进来是迟早的事情。而且,LangChain的框架也已经定型,各个组件的设计都基本固定了。
思考题
- 从今天的两个例子看起来,使用LangChain并不比直接调用OpenAI API来得省事?而且也仍然需要OpenAI API才能调用GPT家族模型。那么LangChain的核心价值在哪里?至少从这两个示例中没看出来。针对这个问题,你仔细思考思考。
一、 抽象层的核心价值
组件解耦设计
- 当需要切换模型供应商时(如从GPT-3.5切换为Claude/本地部署模型),使用LangChain只需修改1行配置,而直接调用API需要重构所有接口调用代码
- 示例对比:
2
3
4
5
llm = ChatOpenAI() → llm = ChatAnthropic()
# 直接API调用
openai.ChatCompletion.create() → anthropic.Messages.create()标准化接口
- 统一了不同模型供应商的输入输出格式,这对需要同时使用多个LLM的混合系统尤为重要
- 提供统一的Prompt模板、记忆管理、输出解析等标准组件
二、 复杂场景优势
链式调用(Chains)
- 需要多步LLM交互时,LangChain提供预制工作流:
- 直接调用API时需要手动维护上下文、解析输出、错误处理
记忆管理(Memory)
- 实现多轮对话时自动维护历史记录:
2
memory.save_context({"input": "你好"}, {"output": "你好!"})- 直接API调用需自行设计历史记录存储和上下文窗口管理
工具集成(Tools)
- 快速构建具备外部能力的AI代理:
2
agent = initialize_agent(tools, llm, agent="chat-conversational-react-description")
三、 企业级开发考量
可观测性
- 内置LangSmith监控平台集成,提供完整的调用链路追踪:
文档处理
- 复杂文档的自动化处理流水线:
2
3
text_splitter = RecursiveCharacterTextSplitter()
vectorstore = FAISS.from_documents(pages, embeddings)生产部署
- 支持通过LangServe快速构建API服务:
四、 成本效益分析
维度 直接调用API LangChain 简单对话实现成本 低 ✅ 中 复杂系统开发成本 高(需自建轮子) 低 ✅ 多模型支持成本 高(每个模型不同接口) 低(统一接口)✅ 长期维护成本 高 低 ✅
五、 典型应用场景
企业知识库系统
- 需要整合:文档加载 → 文本分割 → 向量存储 → 检索增强生成(RAG)
- LangChain提供完整解决方案,直接API调用需自行实现全流程
AI Agent开发
- 需要动态组合:工具调用 → 记忆管理 → 决策判断
- 使用LangChain Agent框架可节省70%开发时间
混合模型系统
- 同时使用GPT-4(创意生成) + Claude(逻辑推理) + 本地模型(敏感数据处理)
- LangChain的标准化接口使多模型协同更易实现
六、 演进趋势
LLM OS理念
- LangChain正在演变为大模型操作系统,管理模型、工具、知识库等资源
可视化编排
- 最新版本支持通过LangGraph实现可视化工作流编排
企业级功能
- 即将推出的RBAC(基于角色的访问控制)、审计日志等企业特性
结论建议
- 简单场景:直接API更合适(快速原型验证、单次对话)
- 复杂系统:LangChain优势显著(需长期维护、多组件集成、企业级需求)
- 学习曲线:初期投入学习LangChain会在后续开发中获得指数级回报
建议在后续实践中尝试以下复杂场景,以更深入体会其价值:
2
3
4
5
6
7
8
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
return_intermediate_steps=True,
handle_parsing_errors=True
)
- LangChain支持的可绝不只有OpenAI模型,那么你能否试一试HuggingFace开源社区中的其它模型,看看能不能用。
提示:你要选择Text-Generation、Text-Text Generation和Question-Answer这一类的文本生成式模型。
1 | #调用API的方式 |
| 特性 | HuggingFaceHub API | 本地部署模型 |
|---|---|---|
| 硬件需求 | 无需本地GPU | 需要高性能GPU (>16GB显存) |
| 响应速度 | 依赖API延迟 (~1-5秒) | 本地计算延迟 (~0.1-3秒) |
| 可定制性 | 受限 | 完全控制模型参数 |
| 隐私性 | 数据需传输到第三方服务器 | 完全本地运行 |
| 典型应用场景 | 原型验证/小规模测试 | 生产环境/敏感数据处理 |
- 上面我提到了生成式模型,那么,大语言模型除了文本生成式模型,还有哪些类别的模型?比如说有名的Bert模型,是不是文本生成式的模型?
提示:如果你没有太多NLP基础知识,建议你可以看一下我的专栏《零基础实战机器学习》和公开课《ChatGPT和预训练模型实战课》。
类别 代表模型 核心能力 典型应用场景 生成式模型 GPT-4、LLaMA 文本续写、自由创作 故事生成、代码编写 判别式模型 BERT、RoBERTa 文本理解、分类判断 情感分析、文本分类 编码器-解码器模型 T5、BART 文本转换 机器翻译、文本摘要 混合架构模型 PALM、GLM 多任务统一处理 通用AI助手 多模态模型 GPT-4V、Flamingo 跨模态理解生成 图文问答、视频描述生成 关键差异点:
- 注意力机制:
- BERT:双向注意力(能看到全文上下文)
- GPT:单向注意力(仅能看到左侧上下文)
- 训练目标:
- BERT:掩码语言建模(Masked Language Modeling)
- GPT:自回归语言建模(Autoregressive Modeling)
- 输出能力:
- BERT:输出文本的语义表示(适合做特征提取)
- GPT:直接生成连贯文本
优缺点分析
生成式模型
- 优势:
- 可生成新数据样本
- 能处理缺失数据(通过生成填补)
- 适合无监督/半监督学习
- 劣势:
- 训练复杂度高(需建模完整分布)
- 生成结果可能不精确(如GPT的”幻觉”问题)
- 计算资源消耗大(如训练175B参数的GPT-3)
判别式模型
- 优势:
- 训练效率高(直接优化目标函数)
- 分类准确率通常更高
- 推理速度快(如BERT的实时分类)
- 劣势:
- 无法生成新数据
- 对数据不平衡敏感
- 需要清晰的任务定义(如固定类别标签)
3. 用LangChain快速构建基于“易速鲜花”本地知识库的智能问答系统
开发框架:

- 数据源(Data Sources):数据可以有很多种,包括PDF在内的非结构化的数据(Unstructured Data)、SQL在内的结构化的数据(Structured Data),以及Python、Java之类的代码(Code)。在这个示例中,我们聚焦于对非结构化数据的处理。
- 大模型应用(Application,即LLM App):以大模型为逻辑引擎,生成我们所需要的回答。
- 用例(Use-Cases):大模型生成的回答可以构建出QA/聊天机器人等系统。
核心实现机制: 这个项目的核心实现机制是下图所示的数据处理管道(Pipeline)。

- Loading:文档加载器把Documents 加载为以LangChain能够读取的形式。
- Splitting:文本分割器把Documents 切分为指定大小的分割,我把它们称为“文档块”或者“文档片”。
- Storage:将上一步中分割好的“文档块”以“嵌入”(Embedding)的形式存储到向量数据库(Vector DB)中,形成一个个的“嵌入片”。
- Retrieval:应用程序从存储中检索分割后的文档(例如通过比较余弦相似度,找到与输入问题类似的嵌入片)。
- Output:把问题和相似的嵌入片传递给语言模型(LLM),使用包含问题和检索到的分割的提示生成答案。
数据的准备和载入
在这一步中,我们从 pdf、word 和 txt 文件中加载文本,然后将这些文本存储在一个列表中(documents = [])。(注意:可能需要安装PyPDF、Docx2txt等库)
1 | import os |
文本的分割
接下来需要将加载的文本分割成更小的块,以便进行嵌入和向量存储。这个步骤中,我们使用 LangChain中的RecursiveCharacterTextSplitter 来分割文本。
1 | # 2.Split 将Documents切分成块以便后续进行嵌入和向量存储 |
现在,我们的文档被切成了一个个200字符左右的文档块。这一步,是为把它们存储进下面的向量数据库做准备。
向量数据库存储
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到: “国王” -> [1.2, 0.5, 3.1, …] “皇帝” -> [1.3, 0.6, 2.9, …] “苹果” -> [0.9, -1.2, 0.3, …]
从这些向量中,我们可以看到“国王”和“皇帝”这两个词的向量在某种程度上是相似的,而与“苹果”这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。
词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等。
1 | class DoubaoEmbeddings(BaseModel, Embeddings): |
向量数据库,也称为矢量数据库或者向量搜索引擎,是一种专门用于存储和搜索向量形式的数据的数据库。在众多的机器学习和人工智能应用中,尤其是自然语言处理和图像识别这类涉及大量非结构化数据的领域,将数据转化为高维度的向量是常见的处理方式。这些向量可能拥有数百甚至数千个维度,是对复杂的非结构化数据如文本、图像的一种数学表述,从而使这些数据能被机器理解和处理。然而,传统的关系型数据库在存储和查询如此高维度和复杂性的向量数据时,往往面临着效率和性能的问题。因此,向量数据库被设计出来以解决这一问题,它具备高效存储和处理高维向量数据的能力,从而更好地支持涉及非结构化数据处理的人工智能应用。
我们将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。在这个例子中,我们使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入(这里需要pip install qdrant-client)。
1 | # 3.Store 将分割嵌入并存储在矢量数据库Qdrant中 |
目前,易速鲜花的所有内部文档,都以“文档块嵌入片”的格式被存储在向量数据库里面了。那么,我们只需要查询这个向量数据库,就可以找到大体上相关的信息了。
相关信息的获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息。
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
- 欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
- 余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在-1到1之间,值越接近1,表示两个向量的方向越相似。
简单来说,关心数量等大小差异时用欧氏距离,关心文本等语义差异时用余弦相似度。
具体来说,欧氏距离度量的是绝对距离,它能很好地反映出向量的绝对差异。当我们关心数据的绝对大小,例如在物品推荐系统中,用户的购买量可能反映他们的偏好强度,此时可以考虑使用欧氏距离。同样,在数据集中各个向量的大小相似,且数据分布大致均匀时,使用欧氏距离也比较适合。
余弦相似度度量的是方向的相似性,它更关心的是两个向量的角度差异,而不是它们的大小差异。在处理文本数据或者其他高维稀疏数据的时候,余弦相似度特别有用。比如在信息检索和文本分类等任务中,文本数据往往被表示为高维的词向量,词向量的方向更能反映其语义相似性,此时可以使用余弦相似度。
在这里,我们正在处理的是文本数据,目标是建立一个问答系统,需要从语义上理解和比较问题可能的答案。因此,我建议使用余弦相似度作为度量标准。通过比较问题和答案向量在语义空间中的方向,可以找到与提出的问题最匹配的答案。
在这一步的代码部分,我们会创建一个聊天模型。然后需要创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在RetrievalQA 链中有下面两大重要组成部分。
- LLM是大模型,负责回答问题。
- retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的“嵌入片”。这些“嵌入片”对应的“文档块”就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为从互联网信息中训练而来的大模型不可能拥有“易速鲜花”作为一个私营企业的内部知识。
1 | # 4. Retrieval 准备模型和Retrieval链 |
生成回答并展示
这一步是问答系统应用的主要UI交互部分,这里会创建一个 Flask 应用(需要安装Flask包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
1 | # 5. Output 问答系统的UI实现 |
总结:我们先把本地知识切片后做Embedding,存储到向量数据库中,然后把用户的输入和从向量数据库中检索到的本地知识传递给大模型,最终生成所想要的回答。


思考题
请你用自己的话简述一下这个基于文档的QA(问答)系统的实现流程?
- 加载PDF、Word、TXT文档,将长文本进行递归分割成文档块,存储到向量数据库作为本地知识库
- RAG:检索+生成,GPT结合检索结果生成答案
- 交互界面:Flask框架
LangChain支持很多种向量数据库,你能否用另一种常用的向量数据库Chroma来实现这个任务?
# 3.Store 将分割嵌入并存储在矢量数据库Chroma中 from langchain_chroma import Chroma # 替换Qdrant为Chroma # 删除原Qdrant相关代码,替换为以下Chroma初始化逻辑 vectorstore = Chroma.from_documents( documents=chunked_documents, # 已分块的文档 embedding=DoubaoEmbeddings( # 使用相同的自定义Embeddings model=os.environ["EMBEDDING_MODELEND"], ), collection_name="my_documents", # 集合名称(类似Qdrant) # persist_directory="./chroma_db" # 可选:持久化到磁盘(默认内存) )--- ### **配套操作步骤** 1. **安装依赖** 先卸载OpenAI依赖,安装HuggingFace相关包:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| 原代码(Qdrant) | 新代码(Chroma) | 说明 |
| :----------------------------- | :--------------- | :------------------------- |
| 依赖 `qdrant-client` | 依赖 `chromadb` | Chroma更轻量,适合本地开发 |
| 内存存储 `location=":memory:"` | 默认内存存储 | Chroma无需显式配置内存模式 |
| 需单独启动Qdrant服务 | 无需额外服务 | Chroma直接嵌入Python环境 |
3. LangChain支持很多种大语言模型,你能否用HuggingFace网站提供的开源模型 [google/flan-t5-x1](https://link.juejin.cn/?target=https%3A%2F%2Fhuggingface.co%2Fgoogle%2Fflan-t5-xl) 代替GPT-3.5完成这个任务?
1. ### **改动点说明**
| 原代码(OpenAI) | 新代码(HuggingFace) | 说明 |
| ----------------------- | --------------------- | ----------------------------- |
| 依赖 `langchain-openai` | 依赖 `transformers` | 需安装PyTorch/HuggingFace库 |
| 调用API | 本地加载模型 | 需GPU资源(建议至少16GB显存) |
| `ChatOpenAI` | `HuggingFacePipeline` | 使用pipeline包装模型 |
---
### **完整修改后的代码(仅展示改动部分)**
```python
# 4. Retrieval 准备模型和Retrieval链(替换为HuggingFace模型)
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, pipeline
from langchain.llms import HuggingFacePipeline # 替换ChatOpenAI
# 实例化HuggingFace模型 - flan-t5-xl
model_name = "google/flan-t5-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, device_map="auto") # 自动分配GPU/CPU
# 创建文本生成pipeline
flan_t5_pipeline = pipeline(
task="text2text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=200, # 控制生成长度
temperature=0.1 # 降低随机性
)
# 将pipeline封装为LangChain的LLM对象
llm = HuggingFacePipeline(pipeline=flan_t5_pipeline)
# 后续MultiQueryRetriever和RetrievalQA链代码无需修改!2. **运行验证** 由于flan-t5-xl模型较大(约11GB),首次运行会自动下载:1
2pip uninstall langchain-openai
pip install transformers torch accelerate--- ### **关键差异对比** | **特性** | **flan-t5-xl** | **GPT-3.5** | | ---------------- | -------------------------- | ---------------- | | **模型类型** | 开源文本生成模型 | 闭源Chat优化模型 | | **部署方式** | 本地加载(需GPU) | API调用 | | **上下文窗口** | 512 tokens | 16k tokens | | **私有数据安全** | 完全本地化,无数据外传风险 | 依赖OpenAI服务器 | | **推理速度** | 较慢(依赖硬件性能) | 快(云端优化) | --- ### **需要关注的适配问题** 1. **提示词格式调整** flan-t5-xl 是**纯文本生成模型**(非Chat模型),需调整问答模板:1
python app.py
2. **性能优化建议**1
2
3# 原始问题:"易速鲜花的退货政策是什么?"
# 输入模板应改为:
"请根据以下上下文回答问题:\n上下文:{context}\n问题:{question}"3. **量化加载(节省显存)**1
2
3
4
5# 调整分块策略(flan-t5-xl适合短上下文)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150, # 减少分块长度
chunk_overlap=20
)--- ### **效果验证** 访问 `http://localhost:5000` 提问测试:1
2
3
4
5model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
device_map="auto",
load_in_8bit=True # 8位量化加载
)--- ### **适用场景建议** - ✅ 适合对数据隐私要求高、需要完全本地化的场景 - ✅ 适合研究/实验性质项目 - ❌ 不适合需要长上下文理解的任务(如整文档摘要) - ❌ 不适合实时性要求高的生产环境 通过这种替换,系统从依赖云端API转变为完全本地化运行,虽然牺牲了部分性能,但获得了更高的数据可控性。1
2
3
4
5用户问题:易速鲜花支持哪些支付方式?
flan-t5-xl生成过程:
1. 检索到《支付流程文档》中的"支持支付宝、微信、银联"
2. 拼接提示词:"请回答:易速鲜花支持哪些支付方式?上下文:...支持支付宝、微信、银联..."
3. 输出:"根据文档,支持支付宝、微信和银联支付"
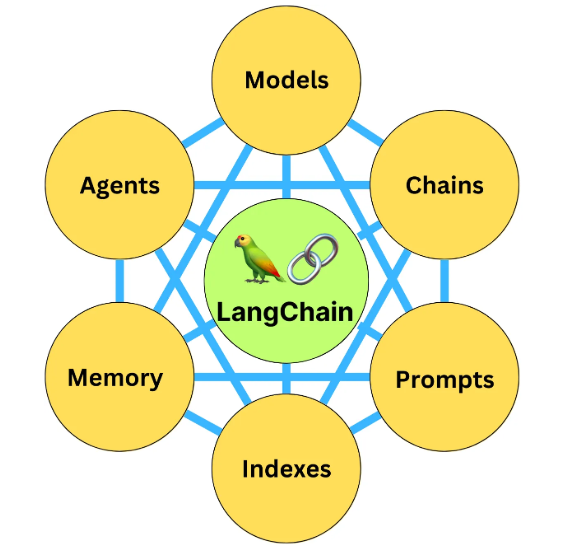
基础篇:深入6大组件
LangChain中的具体组件包括:
- 模型(Models),包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。
- 提示模板(Prompts),使提示工程流线化,进一步激发大语言模型的潜力。
- 数据检索(Indexes),构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
- 记忆(Memory),通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你是谁。
- 链(Chains),是LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成常见用例。
- 代理(Agents),是另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使强大的“智能化”自主Agent成为可能!你的 App 将产生自驱力!
这些组件是LangChain的基石,是赋予其智慧和灵魂的核心要素,它们相互协作,形成一个强大而灵活的系统。在基础篇中,我们将深入探索这些组件的工作原理和使用方法,并给出大量用例,夯实你对这些组件的理解和应用能力。
4. 模型I/O:输入提示、调用模型、解析输出
可以把对模型的使用过程拆解成三块,分别是输入提示(对应图中的Format)、调用模型(对应图中的Predict)和输出解析(对应图中的Parse)。这三块形成了一个整体,因此在LangChain中这个过程被统称为 Model I/O(Input/Output)。

在模型 I/O的每个环节,LangChain都为咱们提供了模板和工具,快捷地形成调用各种语言模型的接口。
- 提示模板:使用模型的第一个环节是把提示信息输入到模型中,你可以创建LangChain模板,根据实际需求动态选择不同的输入,针对特定的任务和应用调整输入。
- 语言模型:LangChain允许你通过通用接口来调用语言模型。这意味着无论你要使用的是哪种语言模型,都可以通过同一种方式进行调用,这样就提高了灵活性和便利性。
- 输出解析:LangChain还提供了从模型输出中提取信息的功能。通过输出解析器,你可以精确地从模型的输出中获取需要的信息,而不需要处理冗余或不相关的数据,更重要的是还可以把大模型给回的非结构化文本,转换成程序可以处理的结构化数据。
提示模板
1 | from langchain.prompts import PromptTemplate |
PromptTemplate对象的内容如下:
1 | input_variables=['flower_name', 'price'] #输入的变量 |
语言模型
LangChain中支持的模型有三大类。
- 大语言模型(LLM) ,也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。Open AI的text-davinci-003、Facebook的LLaMA、ANTHROPIC的Claude,都是典型的LLM。
- 聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
- 文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是Embedding。而文本嵌入模型如OpenAI的text-embedding-ada-002,我们之前已经见过了。文本嵌入模型负责把文档存入向量数据库,和我们这里探讨的提示工程关系不大。
1 | # 设置OpenAI API Key |
LangChain相比直接使用Open AI API的优势:在提示模板中,只需定义一次模板,还整合了output_parser、template_format 以及是否需要validate_template等功能。还可以很方便地把程序切换到不同的模型,而不需要修改任何提示相关的代码。
因此,使用LangChain和提示模板的好处是:
- 代码的可读性:使用模板的话,提示文本更易于阅读和理解,特别是对于复杂的提示或多变量的情况。
- 可复用性:模板可以在多个地方被复用,让你的代码更简洁,不需要在每个需要生成提示的地方重新构造提示字符串。
- 维护:如果你在后续需要修改提示,使用模板的话,只需要修改模板就可以了,而不需要在代码中查找所有使用到该提示的地方进行修改。
- 变量处理:如果你的提示中涉及到多个变量,模板可以自动处理变量的插入,不需要手动拼接字符串。
- 参数化:模板可以根据不同的参数生成不同的提示,这对于个性化生成文本非常有用。
输出解析
通过LangChain的输出解析器来重构程序,让模型有能力生成结构化的回应,同时对其进行解析,直接将解析好的数据存入CSV文档。
1 | """ |
思考题
请你用自己的理解,简述LangChain调用大语言模型来做应用开发的优势。
- 抽象层封装:LangChain封装了不同模型提供商的API差异,开发者无需关注底层API调用细节,只需统一接口调用(如
model.invoke()) - 输入输出标准化:提供Prompt模板机制统一管理提示词,通过输出解析器(OutputParser)自动结构化模型输出,避免手工处理非结构化文本
- 开发效率提升:内置的模板、解析器等组件大幅减少重复代码,例如示例中仅用
output_parser.parse()即可将文本输出转为结构化字典 - 模块化设计:各组件(模板、模型、解析器)可独立替换,如切换GPT-3到Claude只需修改模型初始化代码,业务逻辑无需改动
- 抽象层封装:LangChain封装了不同模型提供商的API差异,开发者无需关注底层API调用细节,只需统一接口调用(如
在上面的示例中,format_instructions,也就是输出格式是怎样用output_parser构建出来的,又是怎样传递到提示模板中的?
format_instructions值为1
2
3
4
5
6
7
8The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"description": string // 鲜花的描述文案
"reason": string // 问什么要这样写这个文案
}
```通过partial_variables将格式说明注入模板
加入了partial_variables,也就是输出解析器指定的format_instructions之后的提示,为什么能够让模型生成结构化的输出?你可以打印出这个提示,一探究竟。
您是一位专业的鲜花店文案撰写员。 对于售价为 50 元的 玫瑰 ,您能提供一个吸引人的简短描述吗? The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":1
2
3
4{
"description": string // 鲜花的描述文案
"reason": string // 问什么要这样写这个文案
}partial_variables在prompt后面加了一段话,这样的提示让模型清晰地知道需要以特定的 JSON 格式输出,并且明确了每个字段的含义和要求,从而生成结构化的输出。提示指出,模型需要根据一个schema来格式化输出文本,这个 schema 从 ```json 开始,到 ``` 结束。
使用输出解析器后,调用模型时有没有可能仍然得不到所希望的输出?也就是说,模型有没有可能仍然返回格式不够完美的输出?
- 有可能,跟模型特性、提示设计、语言生成任务复杂均有关
5. 提示工程(上):用少样本FewShotTemplate和ExampleSelector创建应景文案
这个提示框架中:
- 指令(Instuction)告诉模型这个任务大概要做什么、怎么做,比如如何使用提供的外部信息、如何处理查询以及如何构造输出。这通常是一个提示模板中比较固定的部分。一个常见用例是告诉模型“你是一个有用的XX助手”,这会让他更认真地对待自己的角色。
- 上下文(Context)则充当模型的额外知识来源。这些信息可以手动插入到提示中,通过矢量数据库检索得来,或通过其他方式(如调用API、计算器等工具)拉入。一个常见的用例时是把从向量数据库查询到的知识作为上下文传递给模型。
- 提示输入(Prompt Input)通常就是具体的问题或者需要大模型做的具体事情,这个部分和“指令”部分其实也可以合二为一。但是拆分出来成为一个独立的组件,就更加结构化,便于复用模板。这通常是作为变量,在调用模型之前传递给提示模板,以形成具体的提示。
- 输出指示器(Output Indicator)标记要生成的文本的开始。这就像我们小时候的数学考卷,先写一个“解”,就代表你要开始答题了。如果生成 Python 代码,可以使用 “import” 向模型表明它必须开始编写 Python 代码(因为大多数 Python 脚本以import开头)。这部分在我们和ChatGPT对话时往往是可有可无的,当然LangChain中的代理在构建提示模板时,经常性的会用一个“Thought:”(思考)作为引导词,指示模型开始输出自己的推理(Reasoning)。
LangChain中提供String(StringPromptTemplate)和Chat(BaseChatPromptTemplate)两种基本类型的模板,并基于它们构建了不同类型的提示模板:

使用 PromptTemplate
1 | from langchain import PromptTemplate |
使用 ChatPromptTemplate
OpenAI的Chat Model中的各种消息角色:
1 | import openai |
消息必须是消息对象的数组,其中每个对象都有一个角色(系统、用户或助理)和内容。对话可以短至一条消息,也可以来回多次。
通常,对话首先由系统消息格式化,然后是交替的用户消息和助理消息。
系统消息有助于设置助手的行为。例如,你可以修改助手的个性或提供有关其在整个对话过程中应如何表现的具体说明。但请注意,系统消息是可选的,并且没有系统消息的模型的行为可能类似于使用通用消息,例如“你是一个有用的助手”。
用户消息提供助理响应的请求或评论。
助理消息存储以前的助理响应,但也可以由你编写以给出所需行为的示例。
1 | # 导入聊天消息类模板 |
使用 FewShotPromptTemplate
Zero-Shot:第一次听说就知道什么是毅力,“顿悟”,从知识积累和当前语境中就能够推知新词的涵义。聪明的大模型,某些情况下也是能够做到的。
Few-Shot(少样本)、One-Shot(单样本)和与之对应的 Zero-Shot(零样本)的概念都起源于机器学习。如何让机器学习模型在极少量甚至没有示例的情况下学习到新的概念或类别,对于许多现实世界的问题是非常有价值的,因为我们往往无法获取到大量的标签化数据。
提示工程(Prompt Engineering)中,Few-Shot 和 Zero-Shot 学习的概念也被广泛应用。
- 在Few-Shot学习设置中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应。
- 在Zero-Shot学习设置中,模型只根据任务的描述生成响应,不需要任何示例。
GPT-3模型,作为一个大型的自我监督学习模型,通过提升模型规模,实现了出色的Few-Shot学习性能。
1 | # 1. 创建一些示例 |
如果我们的示例很多,那么一次性把所有示例发送给模型是不现实而且低效的。另外,每次都包含太多的Token也会浪费流量(OpenAI是按照Token数来收取费用)。
LangChain给我们提供了示例选择器,来选择最合适的样本。(注意,因为示例选择器使用向量相似度比较的功能,此处需要安装向量数据库,这里我使用的是开源的Chroma,你也可以选择之前用过的Qdrant。)
1 | # 初始化示例选择器 |
在这个步骤中,它首先创建了一个SemanticSimilarityExampleSelector对象,这个对象可以根据语义相似性选择最相关的示例。然后,它创建了一个新的FewShotPromptTemplate对象,这个对象使用了上一步创建的选择器来选择最相关的示例生成提示。
然后,我们又用这个模板生成了一个新的提示,因为我们的提示中需要创建的是红玫瑰的文案,所以,示例选择器example_selector会根据语义的相似度(余弦相似度)找到最相似的示例,也就是“玫瑰”,并用这个示例构建了FewShot模板。
这样,我们就避免了把过多的无关模板传递给大模型,以节省Token的用量。
总的来说,提供示例对于解决某些任务至关重要,通常情况下,FewShot的方式能够显著提高模型回答的质量。不过,当少样本提示的效果不佳时,这可能表示模型在任务上的学习不足。在这种情况下,我们建议对模型进行微调或尝试更高级的提示技术。
思考题
- 如果你观察LangChain中的prompt.py中的PromptTemplate的实现代码,你会发现除了我们使用过的input_variables、template等初始化参数之外,还有template_format、validate_template等参数。举例来说,template_format可以指定除了f-string之外,其它格式的模板,比如jinja2。请你查看LangChain文档,并尝试使用这些参数。
1 | template_format: str = "f-string" |
- 请你尝试使用PipelinePromptTemplate和自定义Template。
- 请你构想一个关于鲜花店运营场景中客户服务对话的少样本学习任务。在这个任务中,模型需要根据提供的示例,学习如何解答客户的各种问题,包括询问花的价格、推荐鲜花、了解鲜花的保养方法等。最好是用ChatModel完成这个任务。
1 | from langchain.chat_models import ChatOpenAI |
6. 提示工程(下):用思维链和思维树提升模型思考质量
CoT
Few-Shot CoT 简单的在提示中提供了一些链式思考示例(Chain-of-Thought Prompting),足够大的语言模型的推理能力就能够被增强。简单说,就是给出一两个示例,然后在示例中写清楚推导的过程。

整体指导:你需要跟着下面的步骤一步步的推理。
- 问题理解:首先,AI需要理解用户的需求。例如,用户可能会说:“今天要参加朋友的生日Party,想送束花祝福她。”我们可以给AI一个提示模板,里面包含示例:“遇到XX问题,我先看自己有没有相关知识,有的话,就提供答案;没有,就调用工具搜索,有了知识后再试图解决。”—— 这就是给了AI一个思维链的示例。
- 信息搜索:接下来,AI需要搜索相关信息。例如,它可能需要查找哪些花最适合生日派对。
- 决策制定:基于收集到的信息,AI需要制定一个决策。我们可以通过思维链让他详细思考决策的流程,先做什么后做什么。例如,我们可以给它一个示例:“遇到生日派对送花的情况,我先考虑用户的需求,然后查看鲜花的库存,最后决定推荐一些玫瑰和百合,因为这些花通常适合生日派对。”—— 那么有了生日派对这个场景做示例,大模型就能把类似的思维流程运用到其它场景。
- 生成销售列表:最后,AI使用OutputParser生成一个销售列表,包括推荐的花和价格。
图中的(d)示例非常非常有意思,在Zero-Shot CoT中,你只要简单地告诉模型“让我们一步步的思考(Let’s think step by step)”,模型就能够给出更好的答案!

简单总结一下:Few-Shot CoT,指的就是在带有示例的提示过程中,加入思考的步骤,从而引导模型给出更好的结果。而Zero-Shot CoT,就是直接告诉模型要一步一步地思考,慢慢地推理。
实战
1 | # 设置环境变量和API密钥 |
Tree of Thought(ToT)
ToT是一种解决复杂问题的框架,它在需要多步骤推理的任务中,引导语言模型搜索一棵由连贯的语言序列(解决问题的中间步骤)组成的思维树,而不是简单地生成一个答案。ToT框架的核心思想是:让模型生成和评估其思维的能力,并将其与搜索算法(如广度优先搜索和深度优先搜索)结合起来,进行系统性地探索和验证。
和CoT相比就是有更具体的思维步骤(像深度思考)
ToT 框架为每个任务定义具体的思维步骤和每个步骤的候选项数量。例如,要解决一个数学推理任务,先把它分解为3个思维步骤,并为每个步骤提出多个方案,并保留最优的5个候选方案。然后在多条思维路径中搜寻最优的解决方案。
下面我们应用ToT的思想,给出一个鲜花运营方面的示例。
假设一个顾客在鲜花网站上询问:“我想为我的妻子购买一束鲜花,但我不确定应该选择哪种鲜花。她喜欢淡雅的颜色和花香。”
AI(使用ToT框架):
思维步骤1:理解顾客的需求。
顾客想为妻子购买鲜花。
顾客的妻子喜欢淡雅的颜色和花香。
思维步骤2:考虑可能的鲜花选择。
候选1:百合,因为它有淡雅的颜色和花香。
候选2:玫瑰,选择淡粉色或白色,它们通常有花香。
候选3:紫罗兰,它有淡雅的颜色和花香。
候选4:桔梗,它的颜色淡雅但不一定有花香。
候选5:康乃馨,选择淡色系列,它们有淡雅的花香。
思维步骤3:根据顾客的需求筛选最佳选择。
百合和紫罗兰都符合顾客的需求,因为它们都有淡雅的颜色和花香。
淡粉色或白色的玫瑰也是一个不错的选择。
桔梗可能不是最佳选择,因为它可能没有花香。
康乃馨是一个可考虑的选择。
思维步骤4:给出建议。
“考虑到您妻子喜欢淡雅的颜色和花香,我建议您可以选择百合或紫罗兰。淡粉色或白色的玫瑰也是一个很好的选择。希望这些建议能帮助您做出决策!”
思考题
- 我们的CoT实战示例中使用的是Few-Shot CoT提示,请你把它换为Zero-Shot CoT,跑一下程序,看看结果。
- 请你设计一个你工作场景中的任务需求,然后用ToT让大语言模型帮你解决问题。
7. 调用模型:使用OpenAI API还是微调开源Llama2/ChatGLM?
大语言模型发展史
Transformer是几乎所有预训练模型的核心底层架构。基于Transformer预训练所得的大规模语言模型也被叫做“基础模型”(Foundation Model 或Base Model)。
在这个过程中,模型学习了词汇、语法、句子结构以及上下文信息等丰富的语言知识。这种在大量数据上学到的知识,为后续的下游任务(如情感分析、文本分类、命名实体识别、问答系统等)提供了一个通用的、丰富的语言表示基础,为解决许多复杂的NLP问题提供了可能。
在预训练模型出现的早期,BERT毫无疑问是最具代表性的,也是影响力最大的模型。BERT通过同时学习文本的前向和后向上下文信息,实现对句子结构的深入理解。BERT之后,各种大型预训练模型如雨后春笋般地涌现,自然语言处理(NLP)领域进入了一个新时代。这些模型推动了NLP技术的快速发展,解决了许多以前难以应对的问题,比如翻译、文本总结、聊天对话等等,提供了强大的工具。
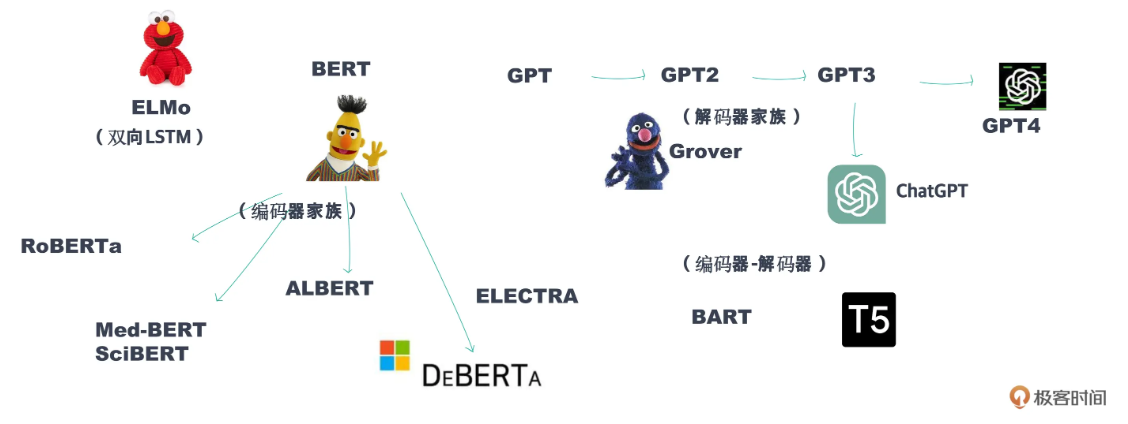
预训练模型本身肯定只有企业能负担得起。
预训练+微调的模式
经过预训练的大模型中所习得的语义信息和所蕴含的语言知识,能够非常容易地向下游任务迁移。NLP应用人员可以对模型的头部或者部分参数根据自己的需要进行适应性的调整,这通常涉及在相对较小的有标注数据集上进行有监督学习,让模型适应特定任务的需求。
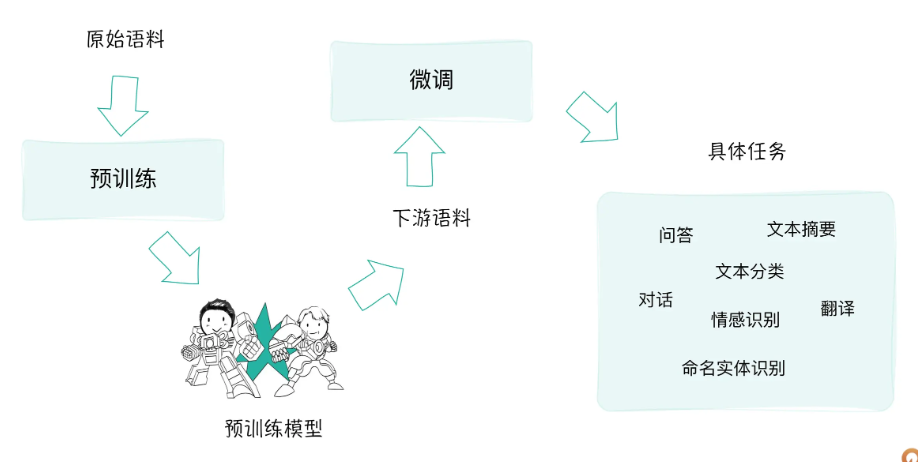
- 预训练:在大规模无标注文本数据上进行模型的训练,目标是让模型学习自然语言的基础表达、上下文信息和语义知识,为后续任务提供一个通用的、丰富的语言表示基础。
- 微调:在预训练模型的基础上,可以根据特定的下游任务对模型进行微调。现在你经常会听到各行各业的人说:我们的优势就是领域知识嘛!我们比不过国内外大模型,我们可以拿开源模型做垂直领域嘛!做垂类模型!—— 啥叫垂类?指的其实就是根据领域数据微调开源模型这件事儿。
实践
Meta(Facebook)推出的Llama2
在HuggingFace的Model中,找到 meta-llama/Llama-2-7b。注意,各种各样版本的Llama2模型多如牛毛,我们这里用的是最小的7B版。此外,还有13b\70b\chat版以及各种各样的非Meta官方版。
1 | # 导入必要的库 |
这段程序是一个很典型的HuggingFace的Transformers库的用例,该库提供了大量预训练的模型和相关的工具。
- 导入AutoTokenizer:这是一个用于自动加载预训练模型的相关分词器的工具。分词器负责将文本转化为模型可以理解的数字格式。
- 导入AutoModelForCausalLM:这是用于加载因果语言模型(用于文本生成)的工具。
- 使用from_pretrained方法来加载预训练的分词器和模型。其中,
device_map = 'auto'是为了自动地将模型加载到可用的设备上,例如GPU。 - 然后,给定一个提示(prompt):
"请给我讲个玫瑰的爱情故事?",并使用分词器将该提示转换为模型可以接受的格式,return_tensors="pt"表示返回PyTorch张量。语句中的.to("cuda")是GPU设备格式转换,因为我在GPU上跑程序,不用这个的话会报错,如果你使用CPU,可以试一下删掉它。 - 最后使用模型的
.generate()方法生成响应。max_new_tokens=2000限制生成的文本的长度。使用分词器的.decode()方法将输出的数字转化回文本,并且跳过任何特殊的标记。
把HuggingFace里面的模型接入LangChain:
第一种集成方式,是通过HuggingFace Hub。HuggingFace Hub 是一个开源模型中心化存储库,主要用于分享、协作和存储预训练模型、数据集以及相关组件。
1 | # 导入HuggingFace API Token |
既然HuggingFace Hub还不能完成Llama-2的测试,让我们来尝试另外一种方法,HuggingFace Pipeline。HuggingFace 的 Pipeline 是一种高级工具,它简化了多种常见自然语言处理(NLP)任务的使用流程,使得用户不需要深入了解模型细节,也能够很容易地利用预训练模型来做任务。
1 | # 指定预训练模型的名称 |
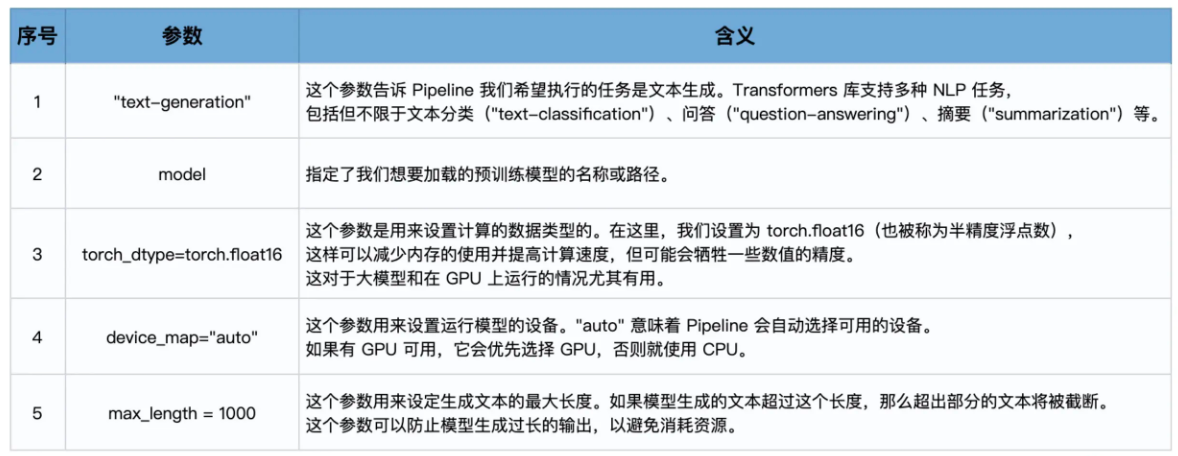
用 LangChain 调用自定义语言模型
假设你就是想训练属于自己的模型。而且出于商业秘密的原因,不想开源它,不想上传到HuggingFace,就是要在本机运行模型。此时应该如何利用LangChain的功能?
我们可以创建一个LLM的衍生类,自己定义模型。而LLM这个基类,则位于langchain.llms.base中,通过from langchain.llms.base import LLM语句导入。
这个自定义的LLM类只需要实现一个方法:
- _call方法:用于接收输入字符串并返回响应字符串。
以及一个可选方法:
- _identifying_params方法:用于帮助打印此类的属性。
假设已经有了一个自己微调后的模型llama-2-7b-chat.ggmlv3.q4_K_S.bin,CustomLLM类的构建和使用,类内部通过Llama类来实现大模型的推理功能,然后直接返回模型的回答。
1 | # 导入需要的库 |
你已经知道大模型训练涉及在大量数据上使用深度学习算法,通常需要大量计算资源和时间。训练后,模型可能不完全适合特定任务,因此需要微调,即在特定数据集上继续训练,以使模型更适应该任务。为了减小部署模型的大小和加快推理速度,模型还会经过量化,即将模型参数从高精度格式减少到较低精度。
如果你想继续深入学习大模型,那么有几个工具你不得不接着研究。
- PyTorch是一个流行的深度学习框架,常用于模型的训练和微调。
- HuggingFace是一个开源社区,提供了大量预训练模型和微调工具,尤其是NLP任务。
- LangChain则擅长于利用大语言模型的推理功能,开发新的工具或应用,完成特定的任务。
这些工具和库在AI模型的全生命周期中起到关键作用,使研究者和开发者更容易开发和部署高效的AI系统。
思考题
- 现在请你再回答一下,什么时候应该使用OpenAI的API?什么时候应该使用开源模型?或者自己开发/微调的模型? 提示:的确,文中没有给出这个问题的答案。因为这个问题并没有标准答案。
- 请你使用HuggingFace的Transformers库,下载新的模型进行推理,比较它们的性能。
- 请你在LangChain中,使用HuggingFaceHub和HuggingFace Pipeline这两种接口,调用当前最流行的大语言模型。 提示:HuggingFace Model 页面,有模型下载量的当月排序,当月下载最多的模型就是最流行的模型。
8. 输出解析:用OutputParser生成鲜花推荐列表
输出解析器是一种专用于处理和构建语言模型响应的类。一个基本的输出解析器类通常需要实现两个核心方法。
- get_format_instructions:这个方法需要返回一个字符串,用于指导如何格式化语言模型的输出,告诉它应该如何组织并构建它的回答。
- parse:这个方法接收一个字符串(也就是语言模型的输出)并将其解析为特定的数据结构或格式。这一步通常用于确保模型的输出符合我们的预期,并且能够以我们需要的形式进行后续处理。
还有一个可选的方法。
- parse_with_prompt:这个方法接收一个字符串(也就是语言模型的输出)和一个提示(用于生成这个输出的提示),并将其解析为特定的数据结构。这样,你可以根据原始提示来修正或重新解析模型的输出,确保输出的信息更加准确和贴合要求。
在LangChain中,通过实现get_format_instructions、parse 和 parse_with_prompt 这些方法,针对不同的使用场景和目标,设计了各种输出解析器。让我们来逐一认识一下。
- 列表解析器(List Parser):这个解析器用于处理模型生成的输出,当需要模型的输出是一个列表的时候使用。例如,如果你询问模型“列出所有鲜花的库存”,模型的回答应该是一个列表。
- 日期时间解析器(Datetime Parser):这个解析器用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式。
- 枚举解析器(Enum Parser):这个解析器用于处理预定义的一组值,当模型的输出应该是这组预定义值之一时使用。例如,如果你定义了一个问题的答案只能是“是”或“否”,那么枚举解析器可以确保模型的回答是这两个选项之一。
- 结构化输出解析器(Structured Output Parser):这个解析器用于处理复杂的、结构化的输出。如果你的应用需要模型生成具有特定结构的复杂回答(例如一份报告、一篇文章等),那么可以使用结构化输出解析器来实现。
- Pydantic(JSON)解析器:这个解析器用于处理模型的输出,当模型的输出应该是一个符合特定格式的JSON对象时使用。它使用Pydantic库,这是一个数据验证库,可以用于构建复杂的数据模型,并确保模型的输出符合预期的数据模型。
- 自动修复解析器(Auto-Fixing Parser):这个解析器可以自动修复某些常见的模型输出错误。例如,如果模型的输出应该是一段文本,但是模型返回了一段包含语法或拼写错误的文本,自动修复解析器可以自动纠正这些错误。
- 重试解析器(RetryWithErrorOutputParser):这个解析器用于在模型的初次输出不符合预期时,尝试修复或重新生成新的输出。例如,如果模型的输出应该是一个日期,但是模型返回了一个字符串,那么重试解析器可以重新提示模型生成正确的日期格式。
这一节主要介绍567,我没怎么看,不过代码是有的。
思考题
- 到目前为止,我们已经使用了哪些LangChain输出解析器?请你说一说它们的用法和异同。同时也请你尝试使用其他类型的输出解析器,并把代码与大家分享。
- 为什么大模型能够返回JSON格式的数据,输出解析器用了什么魔法让大模型做到了这一点?
- 自动修复解析器的“修复”功能具体来说是怎样实现的?请做debug,研究一下LangChain在调用大模型之前如何设计“提示”。
- 重试解析器的原理是什么?它主要实现了解析器类的哪个可选方法?
9. 链(上):写一篇完美鲜花推文?用SequencialChain链接不同的组件
Chain:链在内部把一系列的功能进行封装,而链的外部则又可以组合串联。链其实可以被视为LangChain中的一种基本功能单元。

LLMChain
LLMChain围绕着语言模型推理功能又添加了一些功能,整合了PromptTemplate、语言模型(LLM或聊天模型)和 Output Parser,相当于把Model I/O放在一个链中整体操作。它使用提示模板格式化输入,将格式化的字符串传递给 LLM,并返回 LLM 输出。
如果使用链,代码结构则显得更简洁。
1 | # 导入所需的库 |
除了直接调用、run、predict,apply方法允许我们针对输入列表运行链,一次处理多个输入。generate方法类似于apply,只不过它返回一个LLMResult对象,而不是字符串。LLMResult通常包含模型生成文本过程中的一些相关信息,例如令牌数量、模型名称等。
Sequential Chain:顺序链
通过两个LLM链和一个顺序链,生成了一篇完美的文案
- 第一步,我们假设大模型是一个植物学家,让他给出某种特定鲜花的知识和介绍。
- 第二步,我们假设大模型是一个鲜花评论者,让他参考上面植物学家的文字输出,对鲜花进行评论。
- 第三步,我们假设大模型是易速鲜花的社交媒体运营经理,让他参考上面植物学家和鲜花评论者的文字输出,来写一篇鲜花运营文案。
1 | # 这是总的链,我们按顺序运行这三个链 |
思考题
- 在第4课中,我们曾经用提示模板生成过一段鲜花的描述,代码如下:
1 | for flower, price in zip(flowers, prices): |
请你使用LLMChain重构提示的format和获取模型输出部分,完成相同的功能。
提示:
1 | llm_chain = LLMChain( |
- 上一道题目中,我要求你把提示的format和获取模型输出部分整合到LLMChain中,其实你还可以更进一步,把output_parser也整合到LLMChain中,让程序结构进一步简化,请你尝试一下。
提示:
1 | llm_chain = LLMChain( |
- 选择一个LangChain中的链(我们没用到的类型),尝试使用它解决一个问题,并分享你的用例和代码。
10. 链(下):想学“育花”还是“插花”?用RouterChain确定客户意图
RouterChain,也叫路由链,能动态选择用于给定输入的下一个链。我们会根据用户的问题内容,首先使用路由器链确定问题更适合哪个处理模板,然后将问题发送到该处理模板进行回答。如果问题不适合任何已定义的处理模板,它会被发送到默认链。
在这里,我们会用LLMRouterChain和MultiPromptChain(也是一种路由链)组合实现路由功能,该MultiPromptChain会调用LLMRouterChain选择与给定问题最相关的提示,然后使用该提示回答问题。
具体步骤如下:
- 构建处理模板:为鲜花护理和鲜花装饰分别定义两个字符串模板。
- 提示信息:使用一个列表来组织和存储这两个处理模板的关键信息,如模板的键、描述和实际内容。
- 初始化语言模型:导入并实例化语言模型。
- 构建目标链:根据提示信息中的每个模板构建了对应的LLMChain,并存储在一个字典中。
- 构建LLM路由链:这是决策的核心部分。首先,它根据提示信息构建了一个路由模板,然后使用这个模板创建了一个LLMRouterChain。(引导模型选择最适合的模型提示)
- 构建默认链:如果输入不适合任何已定义的处理模板,这个默认链会被触发。(没找到合适的链就用这个处理)
- 构建多提示链:使用MultiPromptChain将LLM路由链、目标链和默认链组合在一起,形成一个完整的决策系统。
MultiPromptChain中有三个关键元素。
- router_chain(类型RouterChain):这是用于决定目标链和其输入的链。当给定某个输入时,这个router_chain决定哪一个destination_chain应该被选中,以及传给它的具体输入是什么。
- destination_chains(类型Mapping[str, LLMChain]):这是一个映射,将名称映射到可以将输入路由到的候选链。例如,你可能有多种处理文本输入的方法(或“链”),每种方法针对特定类型的问题。destination_chains可以是这样一个字典:
{'weather': weather_chain, 'news': news_chain}。在这里,weather_chain可能专门处理与天气相关的问题,而news_chain处理与新闻相关的问题。 - default_chain(类型LLMChain):当 router_chain 无法将输入映射到destination_chains中的任何一个链时,LLMChain 将使用此默认链。这是一个备选方案,确保即使路由器不能决定正确的链,也总有一个链可以处理输入。
它的工作流程如下:
- 输入首先传递给router_chain。
- router_chain根据某些标准或逻辑决定应该使用哪一个destination_chain。
- 输入随后被路由到选定的destination_chain,该链进行处理并返回结果。
- 如果router_chain不能决定正确的destination_chain,则输入会被传递给default_chain。
1 | chain = MultiPromptChain( |
思考题
- 通过verbose=True这个选项的设定,在输出时显示了链的开始和结束日志,从而得到其相互调用流程。请你尝试把该选项设置为False,看一看输出结果有何不同。
- 在这个例子中,我们使用了ConversationChain作为default_chain,这个Chain是LLMChain的子类,你能否把这个Chain替换为LLMChain?
11. 记忆:通过Memory记住客户上次买花时的对话细节
ConversationChain的对话模板:这是人类和 AI 之间的友好对话。AI 非常健谈并从其上下文中提供了大量的具体细节。 (The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. )
1 | The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. |
同时,这个提示试图通过说明以下内容来减少幻觉,也就是尽量减少模型编造的信息:
“如果 AI 不知道问题的答案,它就会如实说它不知道。”(If the AI does not know the answer to a question, it truthfully says it does not know.)

那么当有了** {history} 参数,以及 Human 和 AI这两个前缀,我们就能够把历史对话信息存储在提示模板中,并作为新的提示内容在新一轮的对话过程中传递给模型。—— 这就是记忆机制的原理
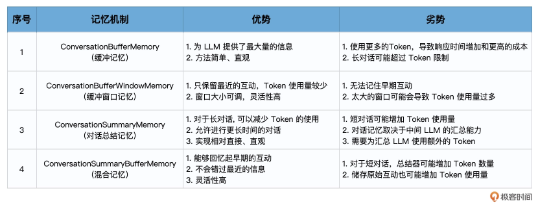
使用ConversationBufferMemory
实际上,这些聊天历史信息,都被传入了ConversationChain的提示模板中的 {history} 参数,构建出了包含聊天记录的新的提示输入。
有了记忆机制,LLM能够了解之前的对话内容,这样简单直接地存储所有内容为LLM提供了最大量的信息,但是新输入中也包含了更多的Token(所有的聊天历史记录),这意味着响应时间变慢和更高的成本。而且,当达到LLM的令牌数(上下文窗口)限制时,太长的对话无法被记住(对于text-davinci-003和gpt-3.5-turbo,每次的最大输入限制是4096个Token)。
使用ConversationBufferWindowMemory
ConversationBufferWindowMemory 是缓冲窗口记忆,它的思路就是只保存最新最近的几次人类和AI的互动。因此,它在之前的“缓冲记忆”基础上增加了一个窗口值 k。这意味着我们只保留一定数量的过去互动,然后“忘记”之前的互动。
尽管这种方法不适合记住遥远的互动,但它非常擅长限制使用的Token数量。如果只需要记住最近的互动,缓冲窗口记忆是一个很好的选择。但是,如果需要混合远期和近期的互动信息,则还有其他选择。
使用ConversationSummaryMemory
上面说了,如果模型在第二轮回答的时候,能够说出“我可以帮你为你姐姐找到…”,那么在第三轮回答时,即使窗口大小 k=1,还是能够回答出正确答案。这是为什么?因为模型在回答新问题的时候,对之前的问题进行了总结性的重述。
ConversationSummaryMemory(对话总结记忆)的思路就是将对话历史进行汇总,然后再传递给 {history} 参数。这种方法旨在通过对之前的对话进行汇总来避免过度使用 Token。
ConversationSummaryMemory有这么几个核心特点。
- 汇总对话:此方法不是保存整个对话历史,而是每次新的互动发生时对其进行汇总,然后将其添加到之前所有互动的“运行汇总”中。
- 使用LLM进行汇总:该汇总功能由另一个LLM驱动,这意味着对话的汇总实际上是由AI自己进行的。
- 适合长对话:对于长对话,此方法的优势尤为明显。虽然最初使用的 Token 数量较多,但随着对话的进展,汇总方法的增长速度会减慢。与此同时,常规的缓冲内存模型会继续线性增长。
这里,我们不仅仅利用了LLM来回答每轮问题,还利用LLM来对之前的对话进行总结性的陈述,以节约Token数量。这里,帮我们总结对话的LLM,和用来回答问题的LLM,可以是同一个大模型,也可以是不同的大模型。
ConversationSummaryMemory的优点是对于长对话,可以减少使用的 Token 数量,因此可以记录更多轮的对话信息,使用起来也直观易懂。不过,它的缺点是,对于较短的对话,可能会导致更高的 Token 使用。另外,对话历史的记忆完全依赖于中间汇总LLM的能力,还需要为汇总LLM使用 Token,这增加了成本,且并不限制对话长度。
通过对话历史的汇总来优化和管理 Token 的使用,ConversationSummaryMemory 为那些预期会有多轮的、长时间对话的场景提供了一种很好的方法。然而,这种方法仍然受到 Token 数量的限制。在一段时间后,我们仍然会超过大模型的上下文窗口限制。
而且,总结的过程中并没有区分近期的对话和长期的对话(通常情况下近期的对话更重要),所以我们还要继续寻找新的记忆管理方法。
使用ConversationSummaryBufferMemory
早期的互动进行汇总+近期的互动保留原始
我要为你介绍的最后一种记忆机制是ConversationSummaryBufferMemory,即对话总结缓冲记忆,它是一种混合记忆模型,结合了上述各种记忆机制,包括ConversationSummaryMemory 和 ConversationBufferWindowMemory的特点。这种模型旨在在对话中总结早期的互动,同时尽量保留最近互动中的原始内容。
它是通过max_token_limit这个参数做到这一点的。当最新的对话文字长度在300字之内的时候,LangChain会记忆原始对话内容;当对话文字超出了这个参数的长度,那么模型就会把所有超过预设长度的内容进行总结,以节省Token数量。
ConversationSummaryBufferMemory的优势是通过总结可以回忆起较早的互动,而且有缓冲区确保我们不会错过最近的互动信息。当然,对于较短的对话,ConversationSummaryBufferMemory也会增加Token数量。
总体来说,ConversationSummaryBufferMemory为我们提供了大量的灵活性。它是我们迄今为止的唯一记忆类型,可以回忆起较早的互动并完整地存储最近的互动。在节省Token数量方面,ConversationSummaryBufferMemory与其他方法相比,也具有竞争力。
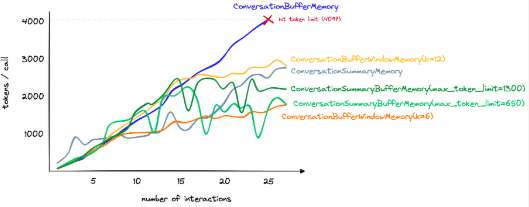
网上还有人总结了一个示意图,体现出了当对话轮次逐渐增加时,各种记忆机制对Token的消耗数量。意图向我们表达的是:有些记忆机制,比如说ConversationSummaryBufferMemory和ConversationSummaryMemory,在对话轮次较少的时候可能会浪费一些Token,但是多轮对话过后,Token的节省就逐渐体现出来了。
当然ConversationBufferWindowMemory对于Token的节省最为直接,但是它会完全遗忘掉K轮之前的对话内容,因此对于某些场景也不是最佳选择。
思考题
- 在你的客服聊天机器人设计中,你会首先告知客户:“亲,我的记忆能力有限,只能记住和你的最近10次对话哦。如果我忘了之前的对话,请你体谅我。” 当有了这样的预设,你会为你的ChatBot选择那种记忆机制?
- 尝试改变示例程序ConversationBufferWindowMemory中的k值,并增加对话轮次,看看记忆效果。
- 尝试改变示例程序ConversationSummaryBufferMemory中的max_token_limit值,看看记忆效果。
12. 代理(上):ReAct框架,推理与行动的协同
仅仅应用思维链推理并不能解决大模型的固有问题:无法主动更新自己的知识,导致出现事实幻觉。也就是说,因为缺乏和外部世界的接触,大模型只拥有训练时见过的知识,以及提示信息中作为上下文提供的附加知识。
可以让大模型先在本地知识库中进行搜索,检查一下提示中的信息的真实性,如果真实,再进行输出;如果不真实,则进行修正。如果本地知识库找不到相应的信息,可以调用工具进行外部搜索,来检查提示信息的真实性。
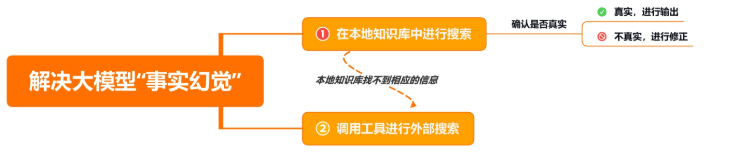
每当你遇到这种需要模型做自主判断、自行调用工具、自行决定下一步行动的时候,Agent(也就是代理)就出场了。
代理就像一个多功能的接口,它能够接触并使用一套工具。根据用户的输入,代理会决定调用哪些工具。它不仅可以同时使用多种工具,而且可以将一个工具的输出数据作为另一个工具的输入数据。
在LangChain中使用代理,我们只需要理解下面三个元素。
- 大模型:提供逻辑的引擎,负责生成预测和处理输入。
- 与之交互的外部工具:可能包括数据清洗工具、搜索引擎、应用程序等。
- 控制交互的代理:调用适当的外部工具,并管理整个交互过程的流程。
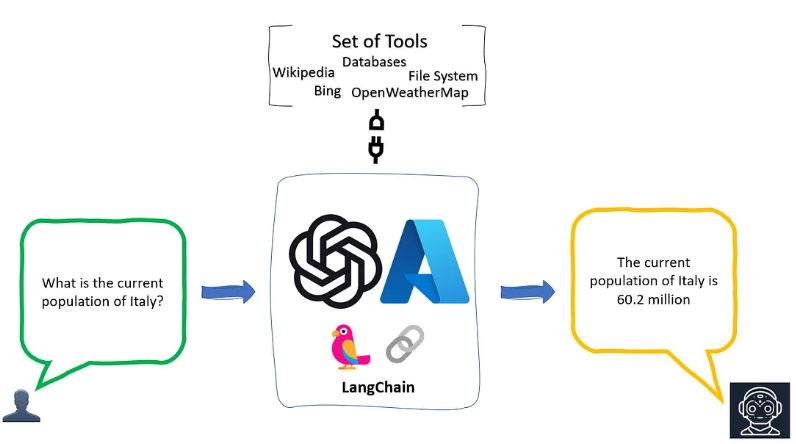
这个过程有很多地方需要大模型自主判断下一步行为(也就是操作)要做什么,如果不加引导,那大模型本身是不具备这个能力的。比如下面这一系列的操作:
- 什么时候开始在本地知识库中搜索(这个比较简单,毕竟是第一个步骤,可以预设)?
- 怎么确定本地知识库的检索已经完成,可以开始下一步?
- 调用哪一种外部搜索工具(比如Google引擎)?
- 如何确定外部搜索工具返回了想要找的内容?
- 如何确定信息真实性的检索已经全部完成,可以开始下一步?
ReAct框架
我会去Google上面查一查今天的鲜花成本价啊(行动),也就是我预计的进货的价格,然后我会根据这个价格的高低(观察),来确定我要加价多少(思考),最后计算出一个售价(行动)!
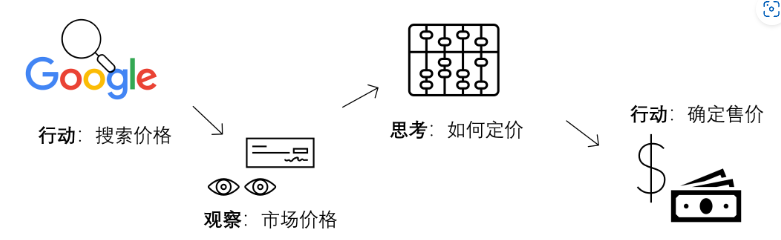
你有观察、有思考,然后才会具体行动。这里的观察和思考,我们统称为推理(Reasoning)过程,推理指导着你的行动(Acting)。
ReAct 框架的灵感正是来自“行动”和“推理”之间的协同作用,这种协同作用使得咱们人类能够学习新任务并做出决策或推理。这个框架,也是大模型能够作为“智能代理”,自主、连续、交错地生成推理轨迹和任务特定操作的理论基础。
大语言模型可以通过生成推理痕迹和任务特定行动来实现更大的协同作用。
具体来说,就是引导模型生成一个任务解决轨迹:观察环境-进行思考-采取行动,也就是观察-思考-行动。那么,再进一步进行简化,就变成了推理-行动,也就是Reasoning-Acting框架。
其中,Reasoning包括了对当前环境和状态的观察,并生成推理轨迹。这使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。Acting在于指导大模型采取下一步的行动,比如与外部源(如知识库或环境)进行交互并且收集信息,或者给出最终答案。
ReAct的每一个推理过程都会被详细记录在案,这也改善大模型解决问题时的可解释性和可信度,而且这个框架在各种语言和决策任务中都得到了很好的效果。
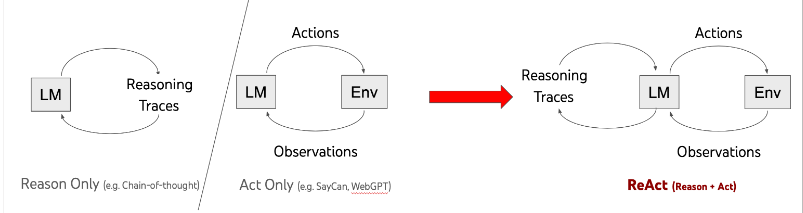
将 ReAct框架和思维链(CoT)结合使用,则能够让大模型在推理过程同时使用内部知识和获取到的外部信息,从而给出更可靠和实际的回应,也提高了 LLMs 的可解释性和可信度。
LangChain正是通过Agent类,将ReAct框架进行了完美封装和实现,这一下子就赋予了大模型极大的自主性(Autonomy),你的大模型现在从一个仅仅可以通过自己内部知识进行对话聊天的 Bot,飞升为了一个有手有脚能使用工具的智能代理。
ReAct框架会提示 LLMs 为任务生成推理轨迹和操作,这使得代理能系统地执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如Google搜索、Wikipedia)的交互,以将额外信息合并到推理中。
1 | # 设置OpenAI和SERPAPI的API密钥 |
通过ReAct框架,大模型将被引导生成一个任务解决轨迹,即观察环境-进行思考-采取行动。观察和思考阶段被统称为推理(Reasoning),而实施下一步行动的阶段被称为行动(Acting)。在每一步推理过程中,都会详细记录下来,这也改善了大模型解决问题时的可解释性和可信度。
- 在推理阶段,模型对当前环境和状态进行观察,并生成推理轨迹,从而使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。
- 在行动阶段,模型会采取下一步的行动,如与外部源(如知识库或环境)进行交互并收集信息,或给出最终答案。
ReAct框架的这些优点,使得它在未来的发展中具有巨大的潜力。随着技术的进步,我们可以期待ReAct框架将能够处理更多、更复杂的任务。特别是随着具身智能的发展,ReAct框架将能够使智能代理在虚拟或实际环境中进行更复杂的交互。例如,智能代理可能会在虚拟环境中进行导航,或者在实际环境中操作物理对象。这将大大扩展AI的应用范围,使得它们能够更好地服务于我们的生活和工作。
思考题
- 在ReAct框架中,推理和行动各自代表什么?其相互之间的关系如何?
- 为什么说ReAct框架能改善大模型解决问题时的可解释性和可信度?
- 你能否说一说LangChain中的代理和链的核心差异?答:在链中,一系列操作被硬编码(在代码中)。在代理中,语言模型被用作推理引擎来确定要采取哪些操作以及按什么顺序执行这些操作。
13. 代理(中):AgentExecutor究竟是怎样驱动模型和工具完成任务的?
上节课中,你了解了ReAct框架的原理,最后我给你留了一道思考题,让你说一说LangChain中的“代理”和“链”的差异究竟是什么。
我的答案是:在链中,一系列操作被硬编码(在代码中)。在代理中,语言模型被用作推理引擎来确定要采取哪些操作以及按什么顺序执行这些操作。
下面这个图,就展现出了Agent接到任务之后,自动进行推理,然后自主调用工具完成任务的过程。
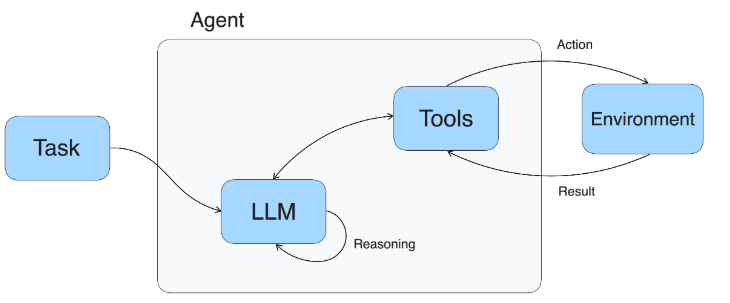
那么,你看LangChain,乃至整个大模型应用开发的核心理念就呼之欲出了。这个核心理念就是操作的序列并非硬编码在代码中,而是使用语言模型(如GPT-3或GPT-4)来选择执行的操作序列。
Agent 的关键组件
在LangChain的代理中,有这样几个关键组件。
- 代理(Agent):这个类决定下一步执行什么操作。它由一个语言模型和一个提示(prompt)驱动。提示可能包含代理的性格(也就是给它分配角色,让它以特定方式进行响应)、任务的背景(用于给它提供更多任务类型的上下文)以及用于激发更好推理能力的提示策略(例如ReAct)。LangChain中包含很多种不同类型的代理。
- 工具(Tools):工具是代理调用的函数。这里有两个重要的考虑因素:一是让代理能访问到正确的工具,二是以最有帮助的方式描述这些工具。如果你没有给代理提供正确的工具,它将无法完成任务。如果你没有正确地描述工具,代理将不知道如何使用它们。LangChain提供了一系列的工具,同时你也可以定义自己的工具。
- 工具包(Toolkits):工具包是一组用于完成特定目标的彼此相关的工具,每个工具包中包含多个工具。比如LangChain的Office365工具包中就包含连接Outlook、读取邮件列表、发送邮件等一系列工具。当然LangChain中还有很多其他工具包供你使用。
- 代理执行器(AgentExecutor):代理执行器是代理的运行环境,它调用代理并执行代理选择的操作。执行器也负责处理多种复杂情况,包括处理代理选择了不存在的工具的情况、处理工具出错的情况、处理代理产生的无法解析成工具调用的输出的情况,以及在代理决策和工具调用进行观察和日志记录。
总的来说,代理就是一种用语言模型做出决策、调用工具来执行具体操作的系统。通过设定代理的性格、背景以及工具的描述,你可以定制代理的行为,使其能够根据输入的文本做出理解和推理,从而实现自动化的任务处理。而代理执行器(AgentExecutor)就是上述机制得以实现的引擎。
现在,请你用你的代码编辑工具(比如VS Code)在agent.run这个语句设置一个断点,用 “Step Into” 功能深入几层LangChain内部代码,直到我们进入了 agent.py文件的AgentExecutor类的内部方法 _take_next_step。
这个 _take_next_step 方法掌控着下一步要调用什么的计划,你可以看到self.agent.plan方法被调用,这是计划开始之处。
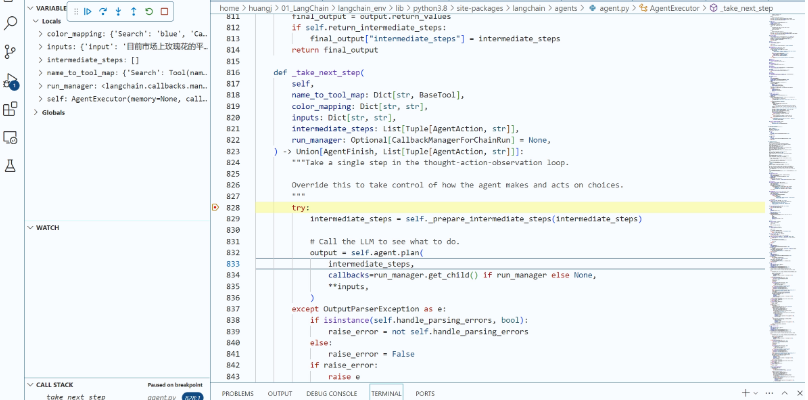
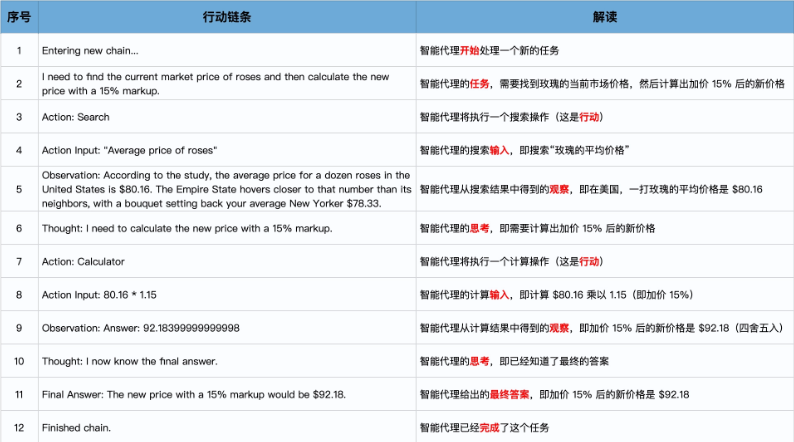
第一轮思考:模型决定搜索
在AgentExecutor 的_take_next_step 方法的驱动下,我们进一步Debug,深入self.agent.plan方法,来到了整个行为链条的第一步—— Plan,这个Plan的具体细节是由Agent类的Plan方法来完成的,你可以看到,输入的问题将会被传递给llm_chain,然后接收llm_chain调用大模型的返回结果。
- 即这里会把agent.run(“input”)中用户的问题输入给llm_chain
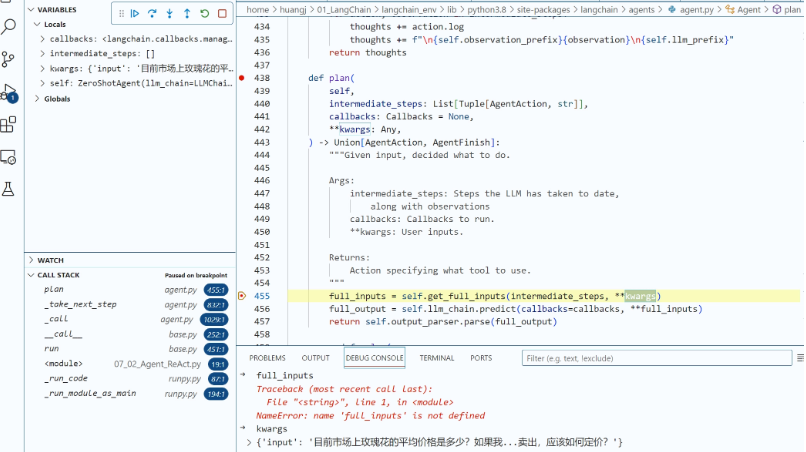
再往前进一步,我们就要开始调用大模型了,那么,LangChain到底传递给了大模型什么具体的提示信息,让大模型能够主动进行工具的选择呢?秘密在 LLMChain类的generate方法中,我们可以看到提示的具体内容。
在Debug过程中,你可以观察prompt,也就是提示的具体内容,这里我把这个提示Copy出来,你可以看一下。
我来给你详细拆解一下这个prompt。注意,下面的解释文字不是原始提示,而是我添加的说明。
0: StringPromptValue(text=’Answer the following questions as best you can. You have access to the following tools:\n\n
这句提示是让模型尽量回答问题,并告诉模型拥有哪些工具。
Search: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\n
这是向模型介绍第一个工具:搜索。
Calculator: Useful for when you need to answer questions about math.\n\n
这是向模型介绍第二个工具:计算器。
Use the following format:\n\n (指导模型使用下面的格式)
Question: the input question you must answer\n (问题)
Thought: you should always think about what to do\n (思考)
Action: the action to take, should be one of [Search, Calculator]\n (行动)
Action Input: the input to the action\n (行动的输入)
Observation: the result of the action\n… (观察:行动的返回结果)
(this Thought/Action/Action Input/Observation can repeat N times)\n (上面这个过程可以重复多次)
Thought: I now know the final answer\n (思考:现在我知道最终答案了)
Final Answer: the final answer to the original input question\n\n (最终答案)
上面,就是给模型的思考框架。具体解释可以看一下括号中的文字
Begin!\n\n
现在开始!
Question: 目前市场上玫瑰花的平均价格是多少?如果我在此基础上加价15%卖出,应该如何定价?
\nThought:’)
具体问题,也就是具体任务。
上面我一句句拆解的这个提示词,就是Agent之所以能够趋动大模型,进行思考-行动-观察行动结果-再思考-再行动-再观察这个循环的核心秘密。有了这样的提示词,模型就会不停地思考、行动,直到模型判断出问题已经解决,给出最终答案,跳出循环。
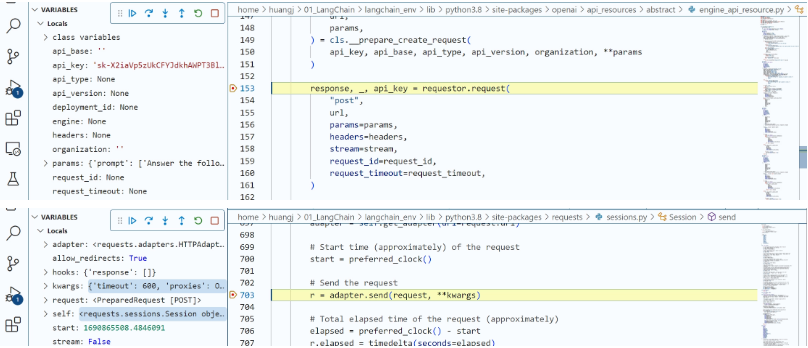
那么,调用大模型之后,模型具体返回了什么结果呢?在Debug过程中,我们发现调用模型之后的outputs中包含下面的内容。
1 | 0: LLMResult(generations=[[Generation(text=' I need to find the current market price of roses and then calculate the new price with a 15% markup.\n |
把上面的内容拆解如下:
‘text’: ‘ I need to find the current market price of roses and then calculate the new price with a 15% markup.\n (Text:问题文本)
Action: Search\n (行动:搜索)
Action Input: “Average price of roses”‘ (行动的输入:搜索玫瑰平均价格)
看来,模型知道面对这个问题,它自己根据现有知识解决不了,下一步行动是需要选择工具箱中的搜索工具。而此时,命令行中也输出了模型的第一步计划——调用搜索工具。
现在模型知道了要调用什么工具,第一轮的Plan部分就结束了。下面,我们就来到了AgentExecutor 的_take_next_step 的工具调用部分。
在这里,因为模型返回了Action为Search,OutputParse解析了这个结果之后,LangChain很清楚地知道,Search工具会被调用。
工具调用完成之后,我们就拥有了一个对当前工具调用的 Observation,也就是当前工具调用的结果。
下一步,我们要再次调用大模型,形成新的 Thought,看看任务是否已经完成了,或者仍需要再次调用工具(新的工具或者再次调用同一工具)。
第二轮思考:模型决定计算
因为任务尚未完成,第二轮思考开始,程序重新进入了Plan环节。
此时,LangChain的LLM Chain根据目前的input,也就是历史对话记录生成了新的提示信息(Thought之前与第一步一模一样,省略)
Thought: I need to find the current market price of roses and then calculate the new price with a 15% markup.\n (思考:我需要找到玫瑰花的价格,并加入15%的加价)
Action: Search\nAction (行动:搜索)
Input: “Average price of roses”\n (行动的输入:玫瑰花的平均价格)
Observation: The average price for a dozen roses in the U.S. is $80.16. The state where a dozen roses cost the most is Hawaii at $108.33. That’s 35% more expensive than the national average. A dozen roses are most affordable in Pennsylvania, costing $66.15 on average.\n (观察:这里时搜索工具返回的玫瑰花价格信息)
Thought:’
思考:后面是大模型应该进一步推理的内容。大模型根据上面这个提示,返回了下面的output信息。
有了上面的Thought做指引,AgentExecutor调用了第二个工具:LLMMath。现在开始计算。这个提示,我把它拷贝出来,也拆解一下。
0: StringPromptValue(text=’Translate a math problem into a expression that can be executed using Python’s numexpr library. Use the output of running this code to answer the question.\n\n
指定模型用Python的数学库来编程解决数学问题,而不是自己计算。这就规避了大模型数学推理能力弱的局限。
Question: ${Question with math problem.}\n (问题)
text\n${single line mathematical expression that solves the problem} n```\n (问题的数学描述)
…numexpr.evaluate(text)…\n``` (通过Python库运行问题的数学描述)
output\n${Output of running the code}\n```\n (输出的Python代码运行结果)
Answer: ${Answer}\n\n (问题的答案)
Begin.\n\n (开始)
从这里开始是两个数学式的解题示例。
Question: What is 37593 * 67?\n
```text\n37593 * 67\n```
\n…numexpr.evaluate(“37593 * 67”)…\n
```output\n2518731\n```\n
Answer: 2518731\n\n
Question: 37593^(1/5)\n
```text\n37593**(1/5)\n```\n…
numexpr.evaluate(“37593**(1/5)”)…\n
```output\n8.222831614237718\n```\n
Answer: 8.222831614237718\n\n
两个数学式的解题示例结束。
Question: 80.16 * 1.15\n’)
这里是玫瑰花问题的具体描述。
第三轮思考:模型完成任务
继续Debug,发现模型在这一轮思考之后的输出中终于包含了 “**I now know the final answer.**”,这说明模型意识到任务已经成功地完成了。
此时,AgentExcutor的plan方法返回一个 AgentFinish 实例,这表示代理经过对输出的检查,其内部逻辑判断出任务已经完成,思考和行动的循环要结束了。
总结
这一课中,我们深入到AgentExecutor的代码内部,深挖其运行机制,了解了AgentExecutor是如何通过计划和工具调用,一步一步完成Thought、Action和Observation的。
如果我们审视一下AgentExecutor 的代码实现,会发现AgentExecutor这个类是作为链(Chain)而存在,同时也为代理执行各种工具,完成任务。它会接收代理的计划,并执行代理思考链路中每一步的行动。
AgentExecutor中最重要的方法是步骤处理方法,_take_next_step方法。它用于在思考-行动-观察的循环中采取单步行动。先调用代理的计划,查找代理选择的工具,然后使用选定的工具执行该计划(此时把输入传给工具),从而获得观察结果,然后继续思考,直到输出是 AgentFinish 类型,循环才会结束。
思考题
- 请你在 agent.py 文件中找到AgentExecutor类。
- 请你在AgentExecutor类中找到_take_next_step方法,对应本课的内容,分析AgentExecutor类是怎样实现Plan和工具调用的。
14. 代理(下):结构化工具对话、Self-Ask with Search以及Plan and execute代理
举例来说,结构化工具的示例包括:
- 文件管理工具集:支持所有文件系统操作,如写入、搜索、移动、复制、列目录和查找。
- Web 浏览器工具集:官方的 PlayWright 浏览器工具包,允许代理访问网站、点击、提交表单和查询数据。
Playwright
Playwright是一个开源的自动化框架,它可以让你模拟真实用户操作网页,帮助开发者和测试者自动化网页交互和测试。用简单的话说,它就像一个“机器人”,可以按照你给的指令去浏览网页、点击按钮、填写表单、读取页面内容等等,就像一个真实的用户在使用浏览器一样。
Playwright支持多种浏览器,比如Chrome、Firefox、Safari等,这意味着你可以用它来测试你的网站或测试应用在不同的浏览器上的表现是否一致。
使用 Self-Ask with Search 代理
Self-Ask with Search 也是LangChain中的一个有用的代理类型(SELF_ASK_WITH_SEARCH)。它利用一种叫做 “Follow-up Question(追问)”加“Intermediate Answer(中间答案)”的技巧,来辅助大模型寻找事实性问题的过渡性答案,从而引出最终答案。
其实,细心的你可能会发现,“使用玫瑰作为国花的国家的首都是哪里?”这个问题不是一个简单的问题,它其实是一个多跳问题——在问题和最终答案之间,存在中间过程。
多跳问题(Multi-hop question)是指为了得到最终答案,需要进行多步推理或多次查询。这种问题不能直接通过单一的查询或信息源得到答案,而是需要跨越多个信息点,或者从多个数据来源进行组合和整合。
也就是说,问题的答案依赖于另一个子问题的答案,这个子问题的答案可能又依赖于另一个问题的答案。这就像是一连串的问题跳跃,对于人类来说,解答这类问题可能需要从不同的信息源中寻找一系列中间答案,然后结合这些中间答案得出最终结论。
“使用玫瑰作为国花的国家的首都是哪里?”这个问题并不直接询问哪个国家使用玫瑰作为国花,也不是直接询问英国的首都是什么。而是先要推知使用玫瑰作为国花的国家(英国)之后,进一步询问这个国家的首都。这就需要多跳查询。
为什么 Self-Ask with Search 代理适合解决多跳问题呢?有下面几个原因。
- 工具集合:代理包含解决问题所必须的搜索工具,可以用来查询和验证多个信息点。这里我们在程序中为代理武装了SerpAPIWrapper工具。
- 逐步逼近:代理可以根据第一个问题的答案,提出进一步的问题,直到得到最终答案。这种逐步逼近的方式可以确保答案的准确性。
- 自我提问与搜索:代理可以自己提问并搜索答案。例如,首先确定哪个国家使用玫瑰作为国花,然后确定该国家的首都是什么。
- 决策链:代理通过一个决策链来执行任务,使其可以跟踪和处理复杂的多跳问题,这对于解决需要多步推理的问题尤为重要。

使用 Plan and execute 代理
计划和执行代理通过首先计划要做什么,然后执行子任务来实现目标。这个想法是受到 Plan-and-Solve 论文的启发。论文中提出了计划与解决(Plan-and-Solve)提示。它由两部分组成:首先,制定一个计划,并将整个任务划分为更小的子任务;然后按照该计划执行子任务。
这种代理的独特之处在于,它的计划和执行不再是由同一个代理所完成,而是:
- 计划由一个大语言模型代理(负责推理)完成。
- 执行由另一个大语言模型代理(负责调用工具)完成。

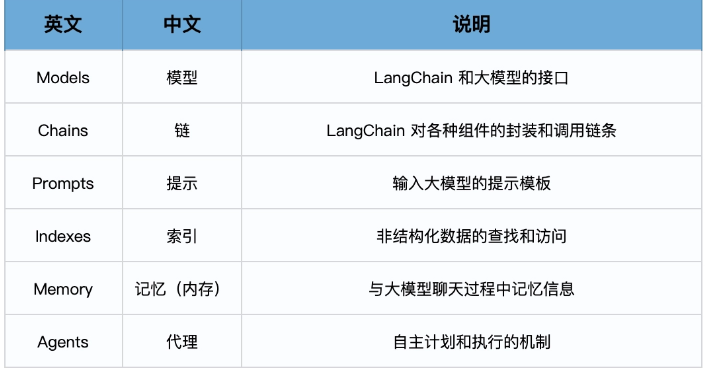
图中的 Indexes,到底是什么,其实这个Indexes是LangChang早期版本的一个组件,现在已经被整合到Retrieval(数据检索)这个单元中了。而Retrieval(包括Indexes),讲的其实就是如何把离散的文档及其他信息做嵌入,存储到向量数据库中,然后再提取的过程。
思考题
- 在结构化工具对话代理的示例中,请你打印出PlayWrightBrowserToolkit中的所有具体工具名称的列表。
提示:
1 | tools = toolkit.get_tools() |
- 在Plan and execute代理的示例中,请你分析PlanAndExecute、AgentExecutor和LLMMathChain链的调用流程以及代理的思考过程。
应用篇
在这个模块中,我们会展示如何将LangChain组件应用到实际场景中。你将学会如何使用LangChain的工具和接口,进行嵌入式存储,连接数据库,引入异步通信机制,通过智能代理进行各种角色扮演、头脑风暴,并进行自主搜索,制定自动策略,尝试不同方案完成任务。
我们将不仅仅是讲解这些组件的功能,还会通过实际应用场景来展示它们是如何互相配合,共同完成复杂任务的。本模块中的很多机制都来源于最新论文,其中对AI智能代理机制的各种使用方式将令你大开脑洞,或许你会哈哈一笑,或许你会击节赞叹,钦佩设计者思路之清奇。
15. 工具和工具箱:LangChain中的Tool和Toolkits一览
LangChain通过提供一个统一的框架来集成功能的具体实现。在这个框架中,每个功能都被封装成一个工具。每个工具都有自己的输入和输出,以及处理这些输入和生成输出的方法。
当代理接收到一个任务时,它会根据任务的类型和需求,通过大模型的推理,来选择合适的工具处理这个任务。这个选择过程可以基于各种策略,例如基于工具的性能,或者基于工具处理特定类型任务的能力。
一旦选择了合适的工具,LangChain就会将任务的输入传递给这个工具,然后工具会处理这些输入并生成输出。这个输出又经过大模型的推理,可以被用作其他工具的输入,或者作为最终结果,被返回给用户。


arXiv本身就是一个论文研究的利器,里面的论文数量比AI顶会还早、还多、还全。那么把它以工具的形式集成到LangChain中,能让你在研究学术最新进展时如虎添翼。
- 通过Gmail工具箱,你可以通过LangChain应用检查邮件、删除垃圾邮件,甚至让它帮你撰写邮件草稿。
- 通过Office365工具箱,你可以让LangChain应用帮你读写文档、总结文档,甚至做PPT。
- 通过GitHub工具箱,你可以指示LangChain应用来检查最新的代码,Commit Changes、Merge Branches,甚至尝试让大模型自动回答 Issues 中的问题——反正大模型解决代码问题的能力本来就更强。
学到现在,你应该对LangChain 的核心价值有了更深的感悟吧。它的价值,在于它将模型运行和交互的复杂性进行了封装和抽象化,为开发者提供了一个更简单、更直观的接口来利用大模型。
- 集成多模型和多策略: LangChain 提供了一种方法,使得多个模型或策略能够在一个统一的框架下工作。例如,arXiv 是一个单独的工具,它负责处理特定的任务。这种工具可以与其他工具(例如用于处理自然语言查询或者数据库查询的工具)一起作为一个集成的系统存在。这样,你可以轻松地创建一个系统,该系统可以处理多种类型的输入并执行多种任务,而不必为每个任务单独写代码。
- 更易于交互和维护: 通过 LangChain,你可以更方便地管理和维护你的工具和模型。LangChain 提供的工具和代理(Agent)抽象使得开发者可以将关注点从底层实现细节转向实现应用的高层逻辑。而且,LangChain封装了像模型的加载、输入输出的处理、工具的调度等底层任务,使得开发者能够更专注于如何组合这些工具以解决实际问题。
- 适应性: LangChain 提供的架构允许你轻松地添加新的工具或模型,或者替换现有的工具或模型。这种灵活性使得你的系统可以很容易地适应新的需求或改变。
- 可解释性: LangChain 还提供了对模型决策的可解释性。在你的示例中,LangChain 提供的对话历史和工具选择的记录可以帮助理解系统做出某些决策的原因。
总的来说,尽管直接调用模型可能对于单一任务或简单应用来说足够了,但是当你需要处理更复杂的场景,例如需要协调多个模型或工具,或者需要处理多种类型的输入时,使用像 LangChain 这样的框架可以大大简化你的工作。
思考题
- 上面Gmail的示例中我只是展示了邮件读取功能,你能否让你的AI助理帮你写邮件的草稿甚至发送邮件?
- 你可否尝试使用GitHub工具开发一些App来自动完成一部分GitHub任务,比如查看Issues、Merge Branches之类的事儿。
提示:参考此链接创建 GitHub App,以及LangChain的参考文档。


16. 检索增强生成:通过RAG助力鲜花运营
什么是RAG?其全称为Retrieval-Augmented Generation,即检索增强生成,它结合了检索和生成的能力,为文本序列生成任务引入外部知识。RAG将传统的语言生成模型与大规模的外部知识库相结合,使模型在生成响应或文本时可以动态地从这些知识库中检索相关信息。这种结合方法旨在增强模型的生成能力,使其能够产生更为丰富、准确和有根据的内容,特别是在需要具体细节或外部事实支持的场合。
RAG 的工作原理可以概括为几个步骤。
- 检索:对于给定的输入(问题),模型首先使用检索系统从大型文档集合中查找相关的文档或段落。这个检索系统通常基于密集向量搜索,例如ChromaDB、Faiss这样的向量数据库。
- 上下文编码:找到相关的文档或段落后,模型将它们与原始输入(问题)一起编码。
- 生成:使用编码的上下文信息,模型生成输出(答案)。这通常当然是通过大模型完成的。
RAG 的一个关键特点是,它不仅仅依赖于训练数据中的信息,还可以从大型外部知识库中检索信息。这使得RAG模型特别适合处理在训练数据中未出现的问题。

文档加载
RAG的第一步是文档加载。LangChain 提供了多种类型的文档加载器,以加载各种类型的文档(HTML、PDF、代码),并与该领域的其他主要提供商如 Airbyte 和 Unstructured.IO 进行了集成。

文本转换
加载文档后,下一个步骤是对文本进行转换,而最常见的文本转换就是把长文档分割成更小的块(或者是片,或者是节点),以适合模型的上下文窗口。LangChain 有许多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档。
文本分割器
把长文本分割成块听起来很简单,其实也存在一些细节。文本分割的质量会影响检索的结果质量。理想情况下,我们希望将语义相关的文本片段保留在一起。
LangChain中,文本分割器的工作原理如下:
- 将文本分成小的、具有语义意义的块(通常是句子)。
- 开始将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,一个块就形成了,可以开始创建新文本块。这个新文本块和刚刚生成的块要有一些重叠,以保持块之间的上下文。
因此,LangChain提供的各种文本拆分器可以帮助你从下面几个角度设定你的分割策略和参数:
- 文本如何分割
- 块的大小
- 块之间重叠文本的长度
这些文本分割器的说明和示例如下:

你可能会关心,文本分割在实践,有哪些具体的考量因素,我总结了下面几点。
首先,就是LLM 的具体限制。GPT-3.5-turbo支持的上下文窗口为4096个令牌,这意味着输入令牌和生成的输出令牌的总和不能超过4096,否则会出错。为了保证不超过这个限制,我们可以预留约2000个令牌作为输入提示,留下约2000个令牌作为返回的消息。这样,如果你提取出了五个相关信息块,那么每个片的大小不应超过400个令牌。
此外,文本分割策略的选择和任务类型相关。
- 需要细致查看文本的任务,最好使用较小的分块。例如,拼写检查、语法检查和文本分析可能需要识别文本中的单个单词或字符。垃圾邮件识别、查找剽窃和情感分析类任务,以及搜索引擎优化、主题建模中常用的关键字提取任务也属于这类细致任务。
- 需要全面了解文本的任务,则使用较大的分块。例如,机器翻译、文本摘要和问答任务需要理解文本的整体含义。而自然语言推理、问答和机器翻译需要识别文本中不同部分之间的关系。还有创意写作,都属于这种粗放型的任务。
最后,你也要考虑所分割的文本的性质。例如,如果文本结构很强,如代码或HTML,你可能想使用较大的块,如果文本结构较弱,如小说或新闻文章,你可能想使用较小的块。
其他形式的文本转换
除拆分文本之外,LangChain中还集成了各种工具对文档执行的其他类型的转换。下面让我们对其进行逐点分析。
- 过滤冗余的文档:使用 EmbeddingsRedundantFilter 工具可以识别相似的文档并过滤掉冗余信息。这意味着如果你有多份高度相似或几乎相同的文档,这个功能可以帮助识别并删除这些多余的副本,从而节省存储空间并提高检索效率。
- 翻译文档:通过与工具 doctran 进行集成,可以将文档从一种语言翻译成另一种语言。
- 提取元数据:通过与工具 doctran 进行集成,可以从文档内容中提取关键信息(如日期、作者、关键字等),并将其存储为元数据。元数据是描述文档属性或内容的数据,这有助于更有效地管理、分类和检索文档。
- 转换对话格式:通过与工具 doctran 进行集成,可以将对话式的文档内容转化为问答(Q/A)格式,从而更容易地提取和查询特定的信息或回答。这在处理如访谈、对话或其他交互式内容时非常有用。
所以说,文档转换不仅限于简单的文本拆分,还可以包含附加的操作,这些操作的目的都是更好地准备和优化文档,以供后续生成更好的索引和检索功能。
文本嵌入
文本块形成之后,我们就通过LLM来做嵌入(Embeddings),将文本转换为数值表示,使得计算机可以更容易地处理和比较文本。OpenAI、Cohere、Hugging Face 中都有能做文本嵌入的模型。
Embeddings 会创建一段文本的向量表示,让我们可以在向量空间中思考文本,并执行语义搜索之类的操作,在向量空间中查找最相似的文本片段。

它提供两种方法:
- 第一种是 embed_documents 方法,为文档创建嵌入。这个方法接收多个文本作为输入,意味着你可以一次性将多个文档转换为它们的向量表示。
- 第二种是 embed_query 方法,为查询创建嵌入。这个方法只接收一个文本作为输入,通常是用户的搜索查询。
为什么需要两种方法?虽然看起来这两种方法都是为了文本嵌入,但是LangChain将它们分开了。原因是一些嵌入提供者对于文档和查询使用的是不同的嵌入方法。文档是要被搜索的内容,而查询是实际的搜索请求。这两者可能因为其性质和目的,而需要不同的处理或优化。
存储嵌入
计算嵌入可能是一个时间消耗大的过程。为了加速这一过程,我们可以将计算出的嵌入存储或临时缓存,这样在下次需要它们时,就可以直接读取,无需重新计算。
缓存存储
CacheBackedEmbeddings是一个支持缓存的嵌入式包装器,它可以将嵌入缓存在键值存储中。具体操作是:对文本进行哈希处理,并将此哈希值用作缓存的键。
要初始化一个CacheBackedEmbeddings,主要的方式是使用from_bytes_store。其需要以下参数:
- underlying_embedder:实际计算嵌入的嵌入器。
- document_embedding_cache:用于存储文档嵌入的缓存。
- namespace(可选):用于文档缓存的命名空间,避免与其他缓存发生冲突。
不同的缓存策略如下:
- InMemoryStore:在内存中缓存嵌入。主要用于单元测试或原型设计。如果需要长期存储嵌入,请勿使用此缓存。
- LocalFileStore:在本地文件系统中存储嵌入。适用于那些不想依赖外部数据库或存储解决方案的情况。
- RedisStore:在Redis数据库中缓存嵌入。当需要一个高速且可扩展的缓存解决方案时,这是一个很好的选择。
在内存中缓存嵌入的示例代码如下:
1 | # 导入内存存储库,该库允许我们在RAM中临时存储数据 |
解释下这段代码。首先我们在内存中设置了一个存储空间,然后初始化了一个嵌入工具,该工具将实际生成嵌入。之后,这个嵌入工具被包装在一个缓存工具中,用于为两段文本生成嵌入。
向量数据库(向量存储)
更常见的存储向量的方式是通过向量数据库(Vector Store)来保存它们。LangChain支持非常多种向量数据库,其中有很多是开源的,也有很多是商用的。比如Elasticsearch、Faiss、Chroma和Qdrant等等。因为选择实在是太多了,我也给你列出来了一个表。

那么问题来了,面对这么多种类的向量数据库,应该如何选择呢?这就涉及到许多技术和业务层面的考量,你应该根据具体需求进行选型。
- 数据规模和速度需求:考虑你的数据量大小以及查询速度的要求。一些向量数据库在处理大规模数据时更加出色,而另一些在低延迟查询中表现更好。
- 持久性和可靠性:根据你的应用场景,确定你是否需要数据的高可用性、备份和故障转移功能。
- 易用性和社区支持:考虑向量数据库的学习曲线、文档的完整性以及社区的活跃度。
- 成本:考虑总体拥有成本,包括许可、硬件、运营和维护成本。
- 特性:考虑你是否需要特定的功能,例如多模态搜索等。
- 安全性:确保向量数据库符合你的安全和合规要求。
在进行向量数据库的评测时,进行性能基准测试是了解向量数据库实际表现的关键。这可以帮助你评估查询速度、写入速度、并发性能等。
数据检索
Retriever,也就是检索器,是数据检索模块的核心入口,它通过非结构化查询返回相关的文档。
向量存储检索器
向量存储检索器是最常见的,它主要支持向量检索。当然LangChain也有支持其他类型存储格式的检索器。
下面实现一个端到端的数据检索功能,我们通过VectorstoreIndexCreator来创建索引,并在索引的query方法中,通过vectorstore类的as_retriever方法,把向量数据库(Vector Store)直接作为检索器,来完成检索任务。
1 | # 设置OpenAI的API密钥 |
你可能会觉得,这个数据检索过程太简单了。这就要归功于LangChain的强大封装能力。如果我们审视一下位于vectorstore.py中的VectorstoreIndexCreator类的代码,你就会发现,它其中封装了vectorstore、embedding以及text_splitter,甚至document loader(如果你使用from_documents方法的话)。
1 | class VectorstoreIndexCreator(BaseModel): |
因此,上面的检索功能就相当于我们第3课中讲过的一系列工具的整合。而我们也可以用下面的代码,来显式地指定索引创建器的vectorstore、embedding以及text_splitter,并把它们替换成你所需要的工具,比如另外一种向量数据库或者别的Embedding模型。
1 | from langchain.text_splitter import CharacterTextSplitter |
那么,下一个问题是 index.query(query),又是如何完成具体的检索及文本生成任务的呢?我们此处既没有看到大模型,又没有看到LangChain的文档检索工具(比如我们在第3课中见过的QARetrival链)。
秘密仍然存在于源码中,在VectorStoreIndexWrapper类的query方法中,可以看到,在调用方法的同时,RetrievalQA链被启动,以完成检索功能。
1 | class VectorStoreIndexWrapper(BaseModel): |
上面我们用到的向量存储检索器,是向量存储类的轻量级包装器,使其符合检索器接口。它使用向量存储中的搜索方法(例如相似性搜索和 MMR)来查询向量存储中的文本。
各种类型的检索器
除向量存储检索器之外,LangChain中还提供很多种其他的检索工具。

这些检索工具,各有其功能特点,你可以查找它们的文档说明,并尝试使用。
索引
索引是一种高效地管理和定位文档信息的方法,确保每个文档具有唯一标识并便于检索。
尽管在第3课的示例中,我们并没有显式的使用到索引就完成了一个RAG任务,但在复杂的信息检索任务中,有效地管理和索引文档是关键的一步。LangChain 提供的索引 API 为开发者带来了一个高效且直观的解决方案。具体来说,它的优势包括:
- 避免重复内容:确保你的向量存储中不会有冗余数据。
- 只更新更改的内容:能检测哪些内容已更新,避免不必要的重写。
- 省时省钱:不对未更改的内容重新计算嵌入,从而减少了计算资源的消耗。
- 优化搜索结果:减少重复和不相关的数据,从而提高搜索的准确性。
LangChain 利用了记录管理器(RecordManager)来跟踪哪些文档已经被写入向量存储。
在进行索引时,API 会对每个文档进行哈希处理,确保每个文档都有一个唯一的标识。这个哈希值不仅仅基于文档的内容,还考虑了文档的元数据。
一旦哈希完成,以下信息会被保存在记录管理器中:
- 文档哈希:基于文档内容和元数据计算出的唯一标识。
- 写入时间:记录文档何时被添加到向量存储中。
- 源 ID:这是一个元数据字段,表示文档的原始来源。
这种方法确保了即使文档经历了多次转换或处理,也能够精确地跟踪它的状态和来源,确保文档数据被正确管理和索引。
总结
通过检索增强生成来存储和搜索非结构化数据的最常见方法是,给这些非结构化的数据做嵌入并存储生成的嵌入向量,然后在查询时给要查询的文本也做嵌入,并检索与嵌入查询“最相似”的嵌入向量。向量数据库则负责存储嵌入数据,并为你执行向量的搜索。

你看,RAG实际上是为非结构化数据创建了一个“地图”。当用户有查询请求时,该查询同样被嵌入,然后你的应用程序会在这个“地图”中寻找与之最匹配的位置,从而快速准确地检索信息。
在我们的鲜花运营场景中,RAG当然可以在很多方面发挥巨大的作用。你的鲜花有各种各样的品种、颜色和花语,这些数据往往是自然的、松散的,也就是非结构化的。使用RAG,你可以通过嵌入向量,把库存的鲜花与相关的非结构化信息(如花语、颜色、产地等)关联起来。当客户或者员工想要查询某种鲜花的信息时,系统可以快速地提供准确的答案。
此外,RAG还可以应用于订单管理。每个订单,无论是客户的姓名、地址、购买的鲜花种类,还是订单状态,都可以被视为非结构化数据。通过RAG,我们可以轻松地嵌入并检索这些订单,为客户提供实时的订单更新、跟踪和查询服务。
当然,对于订单这样的信息,更常见的情况仍是把它们组织成结构化的数据,存储在数据库中(至少也是CSV或者Excel表中),以便高效、精准地查询。那么,LLM能否帮助我们查询数据库表中的条目呢?在下一课中,我将为你揭晓答案。
思考题
- 请你尝试使用一种文本分割器来给你的文档分块。
- 请你尝试使用一种新的向量数据库来存储你的文本嵌入。
- 请你尝试使用一种新的检索器来提取信息。
17. 连接数据库:通过链和代理查询鲜花信息
一直以来,在计算机编程和数据库管理领域,所有的操作都需要通过严格、专业且结构化的语法来完成。这就是结构化查询语言(SQL)。当你想从一个数据库中提取信息或进行某种操作时,你需要使用这种特定的语言明确地告诉计算机你的要求。这不仅需要我们深入了解正在使用的技术,还需要对所操作的数据有充分的了解。
现在,我们正进入一个全新的编程范式,其中机器学习和自然语言处理技术使得与计算机的交互变得更加自然。这意味着,我们可以用更加接近我们日常话语的自然语言来与计算机交流。例如,不用复杂的SQL语句查询数据库,我们可以简单地问:“请告诉我去年的销售额是多少?” 计算机能够理解这个问题,并给出相应的答案。(就是不懂SQL也可以和计算机对话,AI帮助写sql)
这种转变不仅使得非技术人员更容易与计算机交互,还为开发者提供了更大的便利性。简而言之,我们从“告诉计算机每一步怎么做”,转变为“告诉计算机我们想要什么”,整个过程变得更加人性化和高效。
下面这个图,非常清晰地解释了这个以LLM为驱动引擎,从自然语言的(模糊)询问,到自然语言的查询结果输出的流程。
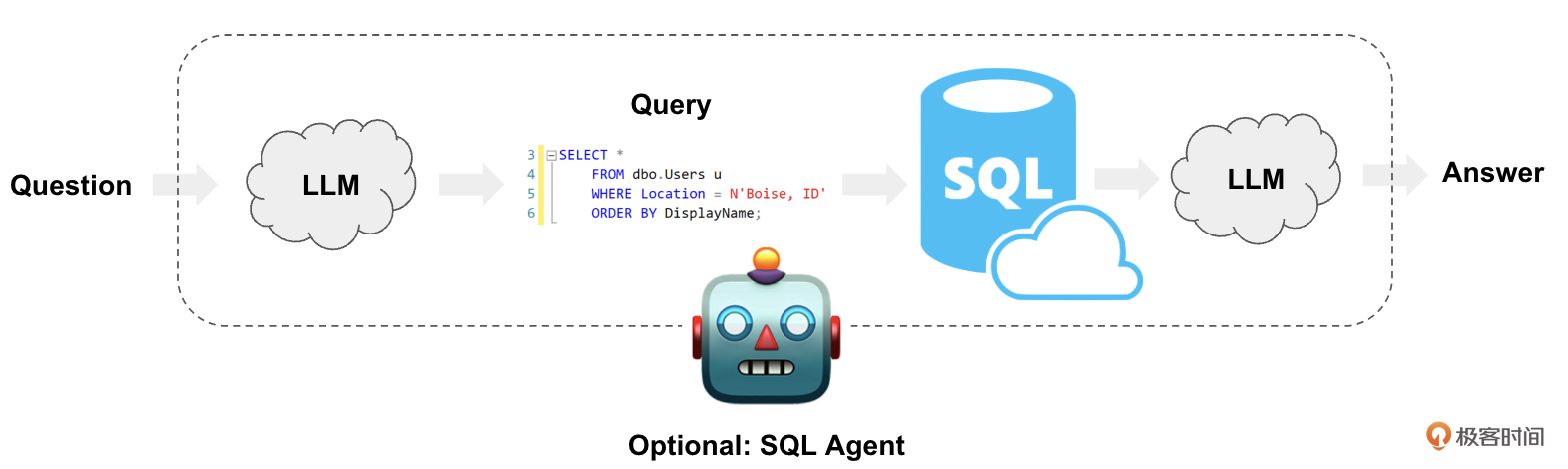
这种范式结合了自然语言处理和传统数据库查询的功能,为用户提供了一个更为直观和高效的交互方式。下面我来解释下这个过程。
- 提出问题:用户用自然语言提出一个问题,例如“去年的总销售额是多少?”。
- LLM理解并转译:LLM首先会解析这个问题,理解其背后的意图和所需的信息。接着,模型会根据解析的内容,生成相应的SQL查询语句,例如 “SELECT SUM(sales) FROM sales_data WHERE year = ‘last_year’;”。
- 执行SQL查询:生成的SQL查询语句会被发送到相应的数据库进行执行。数据库处理这个查询,并返回所需的数据结果。
- LLM接收并解释结果:当数据库返回查询结果后,LLM会接收到这些数据。然后,LLM会开始解析这些数据,并将其转化为更容易被人类理解的答案格式。
- 提供答案:最后,LLM将结果转化为自然语言答案,并返回给用户。例如“去年的总销售额为1,000,000元”。
你看,用户不需要知道数据库的结构,也不需要具备编写SQL的技能。他们只需要用自然语言提问,然后就可以得到他们所需的答案。这大大简化了与数据库的交互过程,并为各种应用场景提供了巨大的潜力。
创建数据库表
这里,我们使用SQLite作为我们的示例数据库。它提供了轻量级的磁盘文件数据库,并不需要单独的服务器进程或系统,应用程序可以直接与数据库文件交互。同时,它也不需要配置、安装或管理,非常适合桌面应用、嵌入式应用或初创企业的简单需求。
SQLite支持ACID(原子性、一致性、隔离性、持久性),这意味着你的数据库操作即使在系统崩溃或电源失败的情况下也是安全的。虽然SQLite被认为是轻量级的,但它支持大多数SQL的标准特性,包括事务、触发器和视图。
因此,它也特别适用于那些不需要大型数据库系统带来的全部功能,但仍然需要数据持久性的应用程序,如移动应用或小型Web应用。当然,也非常适合我们做Demo。
sqlite3库,则是Python内置的轻量级SQLite数据库。通过sqlite3库,Python为开发者提供了一个简单、直接的方式来创建、查询和管理SQLite数据库。当你安装Python时,sqlite3模块已经包含在内,无需再进行额外的安装。
基于这个sqlite3库,创建业务数据的代码如下:
1 | # 导入sqlite3库 |
首先,我们连接到FlowerShop.db数据库。然后,我们创建一个名为Flowers的新表,此表将存储与每种鲜花相关的各种数据。
该表有以下字段:

接着,我们创建了一个名为flowers的列表,其中包含5种鲜花的所有相关数据。使用for循环,我们遍历flowers列表,并将每种鲜花的数据插入到Flowers表中。然后提交这些更改,把它们保存到数据库中。最后,我们关闭与数据库的连接。
和RAG相比没有经过嵌入,就是原始数据
用 Chain 查询数据库
用db_chain.run()方法来查询多个与鲜花运营相关的问题,Chain的内部会把这些自然语言转换为SQL语句,并查询数据库表,得到查询结果之后,又通过LLM把这个结果转换成自然语言。
因此,Chain的输出结果是我们可以理解的,也是可以直接传递给Chatbot的人话。

SQLDatabaseChain调用大语言模型,完美地完成了从自然语言(输入)到自然语言(输出)的新型SQL查询。
用 Agent 查询数据库
除了通过Chain完成数据库查询之外,LangChain 还可以通过SQL Agent来完成查询任务。相比SQLDatabaseChain,使用 SQL 代理有一些优点。
- 它可以根据数据库的架构以及数据库的内容回答问题(例如它会检索特定表的描述)。
- 它具有纠错能力,当执行生成的查询遇到错误时,它能够捕获该错误,然后正确地重新生成并执行新的查询。
LangChain使用create_sql_agent函数来初始化代理,通过这个函数创建的SQL代理包含SQLDatabaseToolkit,这个工具箱中包含以下工具:
- 创建并执行查询
- 检查查询语法
- 检索数据表的描述
1 | from langchain.utilities import SQLDatabase |
可以看到,和Chain直接生成SQL语句不同,代理会使用 ReAct 风格的提示。首先,它思考之后,将先确定第一个action是使用工具 sql_db_list_tables,然后观察该工具所返回的表格,思考后再确定下一个 action是sql_db_schema,也就是创建SQL语句,逐层前进,直到得到答案。
总结
我最想强调的,仍然是从“告诉计算机要做什么”的编程范式向“告诉计算机我们想要什么”的范式的转变。
这种转变具有深远的意义。
- 更大的可达性:不再需要深入的技术知识或特定的编程背景。这意味着非技术人员,比如业务分析师、项目经理甚至是终端用户,都可以直接与数据交互。
- 高效率与生产力:传统的编程方法需要大量的时间和努力,尤其是在复杂的数据操作中。自然语言处理和理解能够显著减少这种负担,使得复杂的数据操作变得更加直观。
- 错误的减少:许多编程错误源于对特定语法或结构的误解,通过使用自然语言,这些源于误解的错误将大大减少。
- 人与机器的紧密结合:在这种新范式下,机器更像是人类的合作伙伴,而不仅仅是一个工具。它们可以理解我们的需求,并为我们提供解决方案,而无需我们明确指导每一步。
但这种转变也带来了挑战。
- 模糊性的问题:自然语言本身是模糊的,机器必须能够准确地解释这种模糊性,并在必要时寻求澄清。
- 对现有系统的依赖:虽然自然语言查询看起来很有吸引力,但许多现有系统可能不支持或不兼容这种新范式。
- 过度依赖:如果过于依赖机器为我们做决策,那么我们可能会失去对数据的深入了解和对结果的质疑。
思考题
- LangChain中用Chain和Agent来查询数据库,这两种方式有什么异同?
- 你能否深入上面这两种方法的代码,看一看它们的底层实现。尤其是要看LangChain是如何做提示工程,指导模型生成 SQL 代码的。
18. 回调函数:在AI应用中引入异步通信机制
回调函数,你可能并不陌生。它是函数A作为参数传给另一个函数B,然后在函数B内部执行函数A。当函数B完成某些操作后,会调用(即“回调”)函数A。这种编程模式常见于处理异步操作,如事件监听、定时任务或网络请求。
在编程中,异步通常是指代码不必等待某个操作完成(如I/O操作、网络请求、数据库查询等)就可以继续执行的能力。异步机制的实现涉及事件循环、任务队列和其他复杂的底层机制。这与同步编程形成对比,在同步编程中,操作必须按照它们出现的顺序完成。
1 | import asyncio |
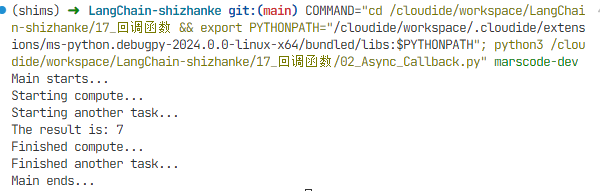
这个示例中,当我们调用 asyncio.create_task(compute(3, 4, print_result)),compute函数开始执行。当它遇到 await asyncio.sleep(2) 时,它会暂停,并将控制权交还给事件循环。这时,事件循环可以选择开始执行another_task,这是另一个异步任务。这样,你可以清晰地看到,尽管compute函数还没有完成,another_task函数也得以开始执行并完成。这就是异步编程,允许你同时执行多个操作,而不需要等待一个完成后再开始另一个。
LangChain 中的 Callback 处理器
LangChain 的 Callback 机制允许你在应用程序的不同阶段进行自定义操作,如日志记录、监控和数据流处理,这个机制通过 CallbackHandler(回调处理器)来实现。
回调处理器是LangChain中实现 CallbackHandler 接口的对象,为每类可监控的事件提供一个方法。当该事件被触发时,CallbackManager 会在这些处理器上调用适当的方法。
BaseCallbackHandler是最基本的回调处理器,你可以继承它来创建自己的回调处理器。它包含了多种方法,如on_llm_start/on_chat(当 LLM 开始运行时调用)和on_llm_error(当 LLM 出现错误时调用)等。
LangChain 也提供了一些内置的处理器,例如 StdOutCallbackHandler,它会将所有事件记录到标准输出。还有FileCallbackHandler,会将所有的日志记录到一个指定的文件中。
在 LangChain 的各个组件,如 Chains、Models、Tools、Agents 等,都提供了两种类型的回调设置方法:构造函数回调和请求回调。你可以在初始化 LangChain 时将回调处理器传入,或者在单独的请求中使用回调。例如,当你想要在整个链的所有请求中进行日志记录时,可以在初始化时传入处理器;而当你只想在某个特定请求中使用回调时,可以在请求时传入。
这两者的区别,我给你整理了一下。

并发是指多个任务在同一时间段内交替执行,但并不一定同时进行。换句话说,系统通过时间分片的方式,在一段时间内快速切换任务,使得这些任务看起来像是在“同时”运行。
并行是指多个任务真正同时执行,通常需要硬件支持(如多核 CPU 或分布式计算环境)。每个任务独立运行在不同的计算单元上,彼此互不干扰。
在 Python 中,async 和 await 是用于实现异步编程 的关键字。它们是 Python 3.5 引入的特性,主要用于处理 I/O 密集型任务(如网络请求、文件读写等),从而提高程序的效率和响应速度。
异步编程的核心思想是:当某个任务需要等待(例如等待网络响应或文件读取完成)时,程序不会阻塞,而是可以切换到其他任务继续执行,从而充分利用 CPU 时间。
async 关键字用于定义一个异步函数 (也称为协程函数)。异步函数与普通函数的主要区别在于:
- 异步函数返回的是一个协程对象 (coroutine object),而不是直接执行函数体。
- 协程对象需要通过事件循环(event loop)来驱动执行。
await 关键字用于暂停 当前协程的执行,直到等待的操作完成。它只能在异步函数中使用,并且后面必须跟一个可等待对象 (awaitable object),例如:
- 另一个协程
asyncio.Future对象- 其他实现了
__await__方法的对象
事件循环是异步编程的核心机制,负责调度和执行协程。Python 提供了 asyncio 模块来管理事件循环。
总结
回调函数是计算机科学中一个重要和广泛应用的概念,它允许我们在特定的时间或条件下执行特定的代码。
回调函数在开发过程中有很多应用场景。
- 异步编程:在JavaScript中,回调函数常常用于异步编程。例如,当你发送一个AJAX请求到服务器时,你可以提供一个回调函数,这个函数将在服务器的响应到达时被调用。
- 事件处理:在许多编程语言和框架中,回调函数被用作事件处理器。例如,你可能会写一个回调函数来处理用户的点击事件,当用户点击某个按钮时,这个函数就会被调用。
- 定时器:你可以使用回调函数来创建定时器。例如,你可以使用JavaScript的setTimeout或setInterval函数,并提供一个回调函数,这个函数会在指定的时间过后被调用。
在 LangChain 中,回调机制同样为用户提供了灵活性和自定义能力,以便更好地控制和响应事件。CallbackHandler允许开发者在链的特定阶段或条件下注入自定义的行为,例如异步编程中的响应处理、事件驱动编程中的事件处理等。这为 LangChain 提供了灵活性和扩展性,使其能够适应各种应用场景。
思考题
- 我通过get_openai_callback重构了ConversationBufferMemory的程序,你能否把这个令牌计数器实现到其他记忆机制中?
- 在LangChain开发过程中,可以在构造函数中引入回调机制,我给出了一个示例,你能否尝试在请求过程(run/apply方法)中引入回调机制?
提示:请求回调常用在流式传输的实现中。在传统的传输中,我们必须等待这个函数生成所有数据后才能开始处理。在流式传输中,我们可以在数据被生成时立即开始处理。如果你想将单个请求的输出流式传输到一个WebSocket,你可以将一个Callback处理器传递给 call() 方法。
实战篇
你将学习如何部署一个鲜花网络电商的人脉工具,并开发一个易速鲜花聊天客服机器人。从模型的调用细节,到数据连接的策略,再到记忆的存储与检索,每一个环节都是为了打造出一个更加智能、更加人性化的系统。
至此,你将能够利用LangChain构建出属于自己的智能问答系统,不论是用于企业的应用开发,还是个人的日常应用,都能够得心应手,游刃有余。
19. CAMEL:通过角色扮演脑暴一个鲜花营销方案
- 交流式代理 Communicative Agents,是一种可以与人类或其他代理进行交流的计算机程序。这些代理可以是聊天机器人、智能助手或任何其他需要与人类交流的软件。为了使这些代理能够更好地与人类交流,研究人员一直在寻找方法来提高它们的交流能力。
- 角色扮演 role-playing,则是这篇论文提出的主要思路,它允许交流代理扮演不同的角色,以更好地与人类或其他代理交流。这意味着代理可以模仿人类的行为,理解人类的意图,并据此做出反应。
- 启示式提示 inception prompting,是一种指导代理完成任务的方法。通过给代理提供一系列的提示或指示,代理可以更好地理解它应该如何行动。这种方法可以帮助代理更好地与人类交流,并完成与人类的合作任务。
智能代理在未来世界中将扮演越来越重要的角色。为了使这些代理能够更好地为人类服务,我们需要找到方法来提高它们的交流能力。CAMEL这篇论文提供了一个全新的视角来看待交流代理的发展。通过使用“角色扮演”框架,可以开发出更加智能和人性化的交流代理,这将为我们的日常生活带来更多的便利。
同时,我们也回顾一下CAMEL框架的实现,以及在这个实现中提示设计的特别之处。
- 角色扮演:每个代理都被赋予了一个角色,且每个角色都有清晰的责任和行为准则。比如,Python程序员(助手)的角色是根据股票交易员(用户)的指示提供具体的解决方案,而股票交易员的角色是提供详细的任务指示。这种角色扮演机制有助于模拟人类之间的交互过程,更加真实地完成任务。
- 任务的具体化:为了使AI更好地理解和执行任务,提出了将抽象任务具体化的步骤。这可以帮助AI更清晰地理解任务需求,更准确地给出解决方案。
- 初始提示的设定:为了启动会话并提供合适的引导,系统初始化时会提供两个初始提示,一条是助手角色的提示,另一条是用户角色的提示。这两条提示分别描述了各自角色的行为准则和任务细节,为整个对话过程提供了框架和指引。
- 交互规范:该代码实现中有明确的交互规范,如一次只能给出一个指令,解决方案必须具有详细的解释,使用 “Solution: ” 开始输出解决方案,等等。这些规范有助于保持对话的清晰性和高效性。
与传统的提示设计不同,CAMEL中提示的设计更加复杂和细致,更像是一种交互协议或规范。这种设计在一定程度上提高了AI与AI之间自主合作的能力,并能更好地模拟人类之间的交互过程。
思考题
- 在你的业务需求中,有什么需要细化、具体化的业务场景吗?不妨套用这里的CAMEL代码模板,做一次头脑风暴。
- 对于这个AI交流代理指导框架和提示模板的设计,你能否说说其优劣之处?有没有能进一步改进的地方?
20. BabyAGI:根据气候变化自动制定鲜花存储策略
随着ChatGPT的崭露头角,我们迎来了一种新型的代理——Autonomous Agents(自治代理或自主代理)。这些代理的设计初衷就是能够独立地执行任务,并持续地追求长期目标。在LangChain的代理、工具和记忆这些组件的支持下,它们能够在无需外部干预的情况下自主运行,这在真实世界的应用中具有巨大的价值。
思考题
- 请你阅读 AutoGPT 的细节,并构造自己的AI代理。
- 请你阅读 HuggingGPT 的细节,并构造自己的AI代理。
21. 部署一个鲜花网络电商的人脉工具(上)
这节课我们完成了前两步的工作。分别是,找到适合推广某种鲜花的大V的微博UID,并且爬取了大V的资料。这为我们后续生成文本、进一步链接大V打下了良好的基础。
其中,我们用到了大量之前学习过的LangChain组件,具体包括:
- 用提示模板告诉大模型我们要找到内容(UID)。
- 调用LLM。
- 使用Chain。
- 使用Agent。
- 在Agent中,我们使用了一个Customized Tool,因为LangChain内置的SerpAPI Tool不能完全满足我们的需要。这给了我们一个好机会创建自己的“私人定制” Tool。
思考题
- 如果Agent不返回UID,而是返回URL,是不是也能够完成这个任务?你可以尝试重构提示模板以及后续逻辑,返回URL,然后手动从URL中解析出UID。
- 研究一下SerpAPIWrapper类的_process_response中的代码,看看这个方法具体是怎么设计的,用来实现了什么功能?
22. 部署一个鲜花网络电商的人脉工具(下)
第一步: 通过LangChain的搜索工具,以模糊搜索的方式,帮助运营人员找到微博中有可能对相关鲜花推广感兴趣的大V(比如喜欢牡丹花的大V),并返回UID。
第二步: 根据微博UID,通过爬虫工具拿到相关大V的微博公开信息,并以JSON格式返回大V的数据。
第三步: 通过LangChain调用LLM,通过信息整合以及文本生成功能,根据大V的个人信息,写一篇热情洋溢的介绍型文章,谋求与该大V的合作。
第四步: 把LangChain输出解析功能加入进来,让LLM生成可以嵌入提示模板的格式化数据结构。
第五步: 添加HTML、CSS,并用Flask创建一个App,在网络上部署及发布这个鲜花电商人脉工具,供市场营销部门的人员使用。
思考题
- 修改提示模板,让LLM为你生成更多更有创意、业务上更实用的文案。
- 试试爬取其他网站(比如豆瓣)上的公开数据,制作更全面的人脉工具。
- 你或许已经发现,我的这个程序不够鲁棒。这里,我用了牡丹、月季进行了测试,程序都找到了相关的UID,但是当我使用其他一些花的时候,比如玫瑰、野菊花,会出现各种各样的错误。你能否修改程序(比如提示模板、输出解析、整体结构),让程序更健壮?
23. 易速鲜花聊天客服机器人的开发(上)
这个项目的具体技术实现步骤,这里简述一下。
第一步: 通过LangChain的ConversationChain,实现一个最基本的聊天对话工具。
第二步: 通过LangChain中的记忆功能,让这个聊天机器人能够记住用户之前所说的话。
第三步: 通过LangChain中的检索功能,整合易速鲜花的内部文档资料,让聊天机器人不仅能够基于自己的知识,还可以基于易速鲜花的业务流程,给出专业的回答。
第四步(可选): 通过LangChain中的数据库查询功能,让用户可以输入订单号来查询订单状态,或者看看有没有存货等等。
第五步: 在网络上部署及发布这个聊天机器人,供企业内部员工和易速鲜花用户使用。
在上面的 5 个步骤中,我们使用到了很多LangChain技术,包括提示工程、模型、链、代理、RAG、数据库检索等。
思考题
如果你回忆第11讲,会发现我当时是在ConversationChain中实现了记忆机制。在这节课的示例中,我直接把Memory应用到了LLMChain中,你能否用ConversationChain中的Memory来重构并简化代码?
提示:ConversationChain实际上是对Memory和LLMChain进行了封装,简化了初始化Memory的步骤。
我希望在聊天机器人中增加对数据库的查询能力,让用户或者业务人员知道某种鲜花的库存情况、销售情况等等。你能否参考第17讲的内容,把这个功能整合到这个Chatbot中呢?
24. 易速鲜花聊天客服机器人的开发(下)
使用streamlit和Gradio部署ui
思考题
- 我的易速鲜花Chatbot有很多不完美的地方,比如,检索功能的设计不够细致,UI不够美观,等等。请你在这个Repo的基础上,大刀阔斧地进行改进。
- 请你用Flask框架设计自己的Chatbot UI,重构聊天机器人,实现更多、更完善的功能。
- 请你回过头去看看第 02 讲我给你留的3道思考题。那时候,你不了解LangChain,现在你已经基本掌握了它的精髓,能否把第01讲的思考题重新回答一遍呢?应该很有趣吧!