入门岛
第一关 Linux
闯关任务:完成SSH连接与端口映射并运行hello_world.py
ssh连接:打开powershell,复制登录命令。使用hostname查看开发机名称,使用uname -a查看开发机内核信息,使用lsb_release -a查看开发机版本信息,使用nvidia-smi查看GPU的信息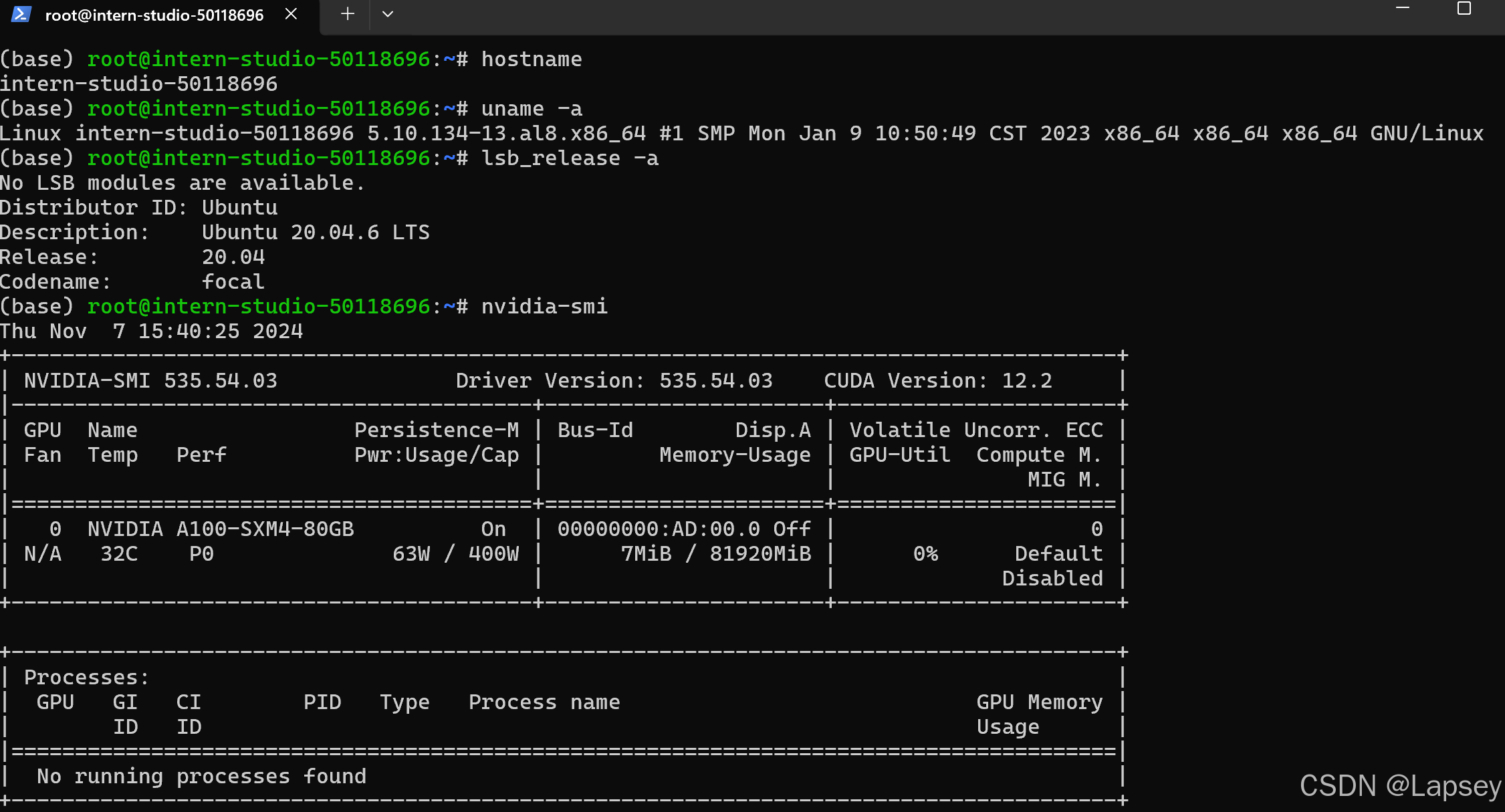
后续使用cursor进行ssh和端口映射,成功运行hello_world.py
笔记与过程
SSH
cursor安装Remote-SSH
创建开发机
SSH全称Secure Shell,中文翻译为安全外壳,它是一种网络安全协议,通过加密和认证机制实现安全的访问和文件传输等业务。SSH 协议通过对网络数据进行加密和验证,在不安全的网络环境中提供了安全的网络服务。
SSH 是(C/S架构)由服务器和客户端组成,为建立安全的 SSH 通道,双方需要先建立 TCP 连接,然后协商使用的版本号和各类算法,并生成相同的会话密钥用于后续的对称加密。在完成用户认证后,双方即可建立会话进行数据交互。
那在后面的实践中我们会配置SSH密钥,配置密钥是为了当我们远程连接开发机时不用重复的输入密码,那为什么要进行远程连接呢?
远程连接的好处就是,如果你使用的是远程办公,你可以通过SSH远程连接开发机,这样就可以在本地进行开发。而且如果你需要跑一些本地的代码,又没有环境,那么远程连接就非常有必要了。
命令:ssh -p 38267 root@ssh.intern-ai.org.cn -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null
端口映射
端口映射是一种网络技术,它可以将外网中的任意端口映射到内网中的相应端口,实现内网与外网之间的通信。通过端口映射,可以在外网访问内网中的服务或应用,实现跨越网络的便捷通信。
那么我们使用开发机为什么要进行端口映射呢?
因为在后续的课程中我们会进行模型web_demo的部署实践,那在这个过程中,很有可能遇到web ui加载不全的问题。这是因为开发机Web IDE中运行web_demo时,直接访问开发机内 http/https 服务可能会遇到代理问题,外网链接的ui资源没有被加载完全。
所以为了解决这个问题,我们需要对运行web_demo的连接进行端口映射,将外网链接映射到我们本地主机,我们使用本地连接访问,解决这个代理问题。下面让我们实践一下。
ssh -p 38267 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
这条命令会通过开发机 SSH 通道将开发机内的 {开发机_PORT} 转发到您本地机器的 (本地机器_PORT},这个过程可能会要求你输入 SSH 链接的密码。
linux文件管理命令
在 Linux 中,常见的文件管理操作包括:
- 创建文件:可以使用
touch命令创建空文件。 - 创建目录:使用
mkdir命令。 - 目录切换:使用
cd命令。 - 显示所在目录:使用
pwd命令。 - 查看文件内容:如使用
cat直接显示文件全部内容,more和less可以分页查看。 - 编辑文件:如
vi或vim等编辑器。 - 复制文件:用
cp命令。 - 创建文件链接:用
ln命令。 - 移动文件:通过
mv命令。 - 删除文件:使用
rm命令。 - 删除目录:
rmdir(只能删除空目录)或rm -r(可删除非空目录)。 - 查找文件:可以用
find命令。 - 查看文件或目录的详细信息:使用
ls命令,如使用ls -l查看目录下文件的详细信息。 - 处理文件:进行复杂的文件操作,可以使用
sed命令。
linux进程管理命令
进程管理命令是进行系统监控和进程管理时的重要工具,常用的进程管理命令有以下几种:
- ps:查看正在运行的进程
- top:动态显示正在运行的进程
- pstree:树状查看正在运行的进程
- pgrep:用于查找进程
- nice:更改进程的优先级
- jobs:显示进程的相关信息
- bg 和 fg:将进程调入后台
- kill:杀死进程
第二关 Python
闯关任务:Leetcode 383(笔记中提交代码与leetcode提交通过截图)
代码:
1 | class Solution: |
通过截图: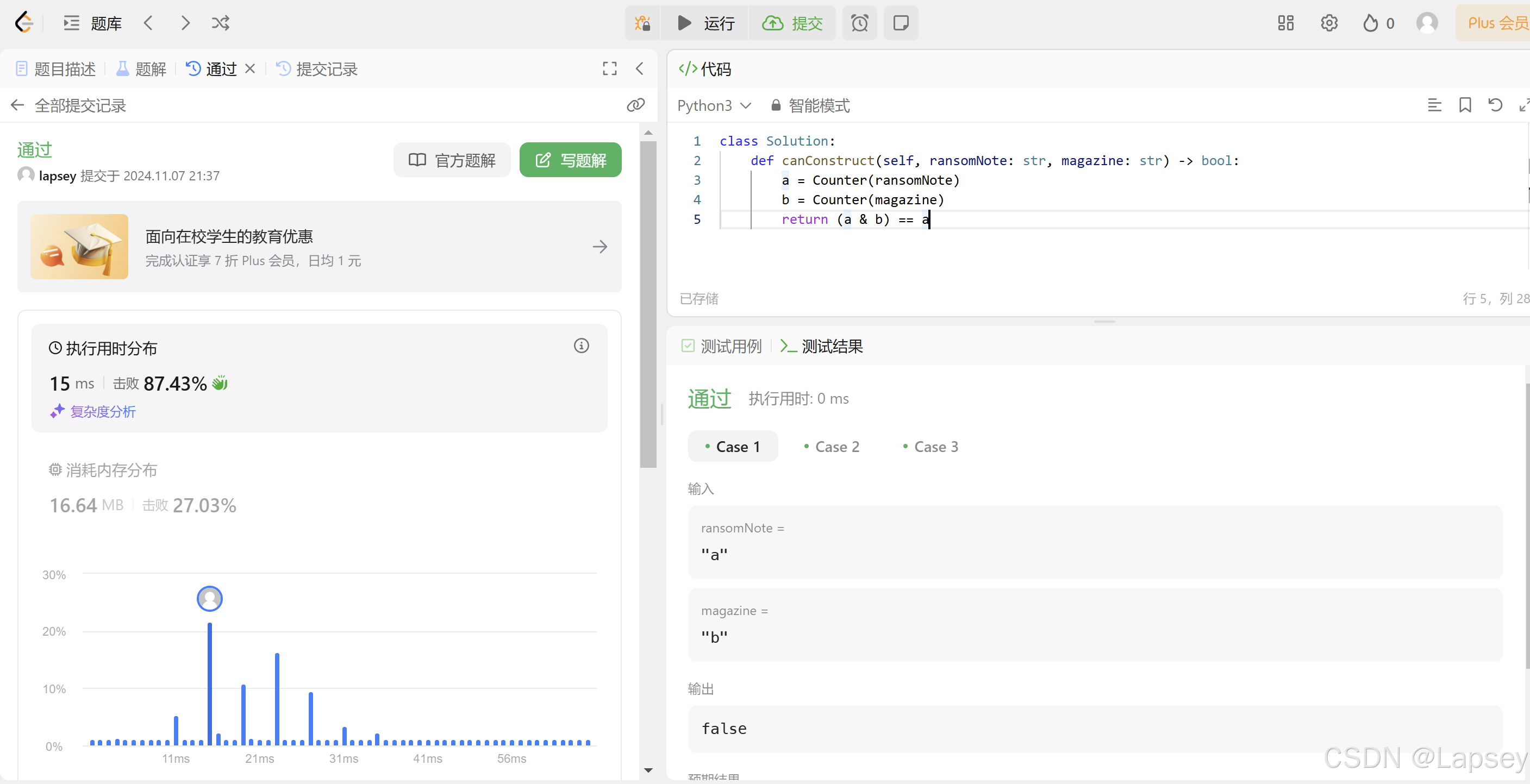
思路:一开始的想法是用map统计每个字母的出现次数,保证magazine中每个字母的统计次数>=ransomNote中的;python3正好有很方便的库Collection用来跟踪值出现的次数,常见操作如下,用交集就可以满足该题的要求。
1 | c = Counter("abcdcba") |
闯关任务:Vscode连接InternStudio debug笔记
pip下载openai环境,运行后发现有bug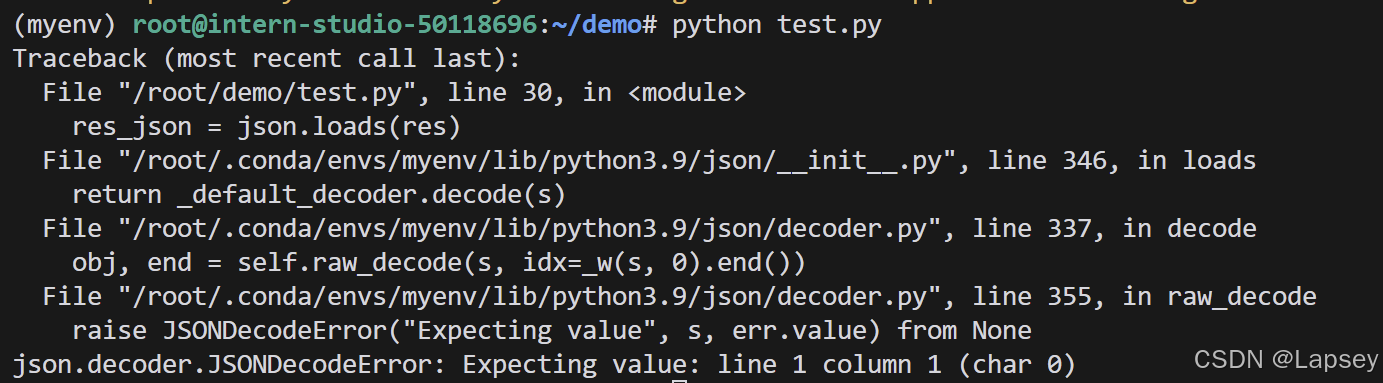
打断点排查,发现json.loads理应处理的json字符串res有一些多余的字符:
使用res.strip()去除后即可顺利运行:
完整代码:
1 | from openai import OpenAI#调用书生浦语API实现将非结构化文本转化成结构化json的例子 |
笔记与过程
conda虚拟环境
虚拟环境是Python开发中不可或缺的一部分,它允许你在不同的项目中使用不同版本的库,避免依赖冲突。Conda是一个强大的包管理器和环境管理器。
pip只管理python包,conda
1 | conda create --name myenv python=3.9 |
pip安装
pip install -r requirements.txt
为了节省大家的存储空间,本次实战营可以直接使用share目录下的conda环境,但share目录只有读权限,所以要安装额外的包时我们不能直接使用pip将包安装到对应环境中,需要安装到我们自己的目录下。
这里我们用本次实战营最常用的环境/root/share/pre_envs/pytorch2.1.2cu12.1来举例。
1 | # 首先激活环境 |
要使用安装在指定目录的python包,可以在python脚本开头临时动态地将该路径加入python环境变量中去
1 | import sys |
配debug环境
下载python插件,首次debug需要配置以下,点击“create a launch.json file”,选择python debugger后选择“Python File” config。
第三关 git
任务1: 破冰活动:自我介绍
fork后下载有一些问题,是网络,多试几次
写自我介绍文件并提交到本地仓库
提交pr。pr链接:https://github.com/InternLM/Tutorial/pull/2517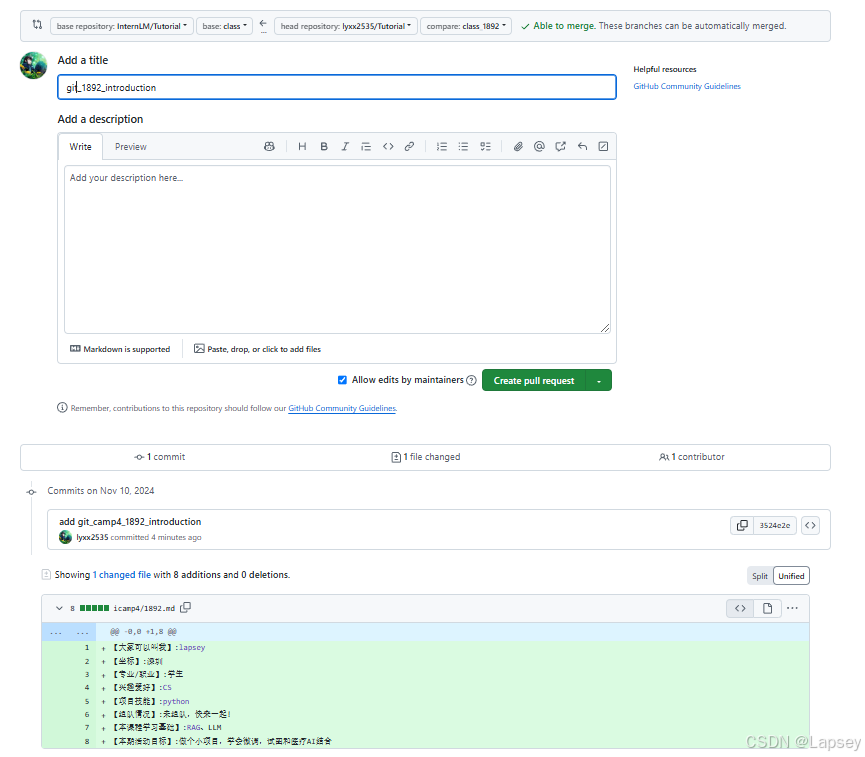
任务2: 实践项目:构建个人项目
因为github经常出现网络问题,使用gitee平台,在其上上传了深度学习相关的个人毕设项目(因为暂无大模型项目),并将书生大模型的超链接加入readme:https://gitee.com/sammmmy/cfg-gnn
因为个人时间和能力有限,以及主题不相关,不报名第四期实战营项目。
笔记与过程
工作区、暂存区和 Git 仓库区
- 工作区(Working Directory): 当我们在本地创建一个 Git 项目,或者从 GitHub 上 clone 代码到本地后,项目所在的这个目录就是“工作区”。这里是我们对项目文件进行编辑和使用的地方。
- 暂存区(Staging Area): 暂存区是 Git 中独有的一个概念,位于 .git 目录中的一个索引文件,记录了下一次提交时将要存入仓库区的文件列表信息。使用 git add 指令可以将工作区的改动放入暂存区。
- 仓库区 / 本地仓库(Repository): 在项目目录中,.git 隐藏目录不属于工作区,而是 Git 的版本仓库。这个仓库区包含了所有历史版本的完整信息,是 Git 项目的“本体”。
常用指令
常用指令
| 指令 | 描述 |
|---|---|
git config |
配置用户信息和偏好设置 |
git init |
初始化一个新的 Git 仓库 |
git clone |
克隆一个远程仓库到本地 |
git status |
查看仓库当前的状态,显示有变更的文件 |
git add |
将文件更改添加到暂存区 |
git commit |
提交暂存区到仓库区 |
git branch |
列出、创建或删除分支 |
git checkout |
切换分支或恢复工作树文件 |
git merge |
合并两个或更多的开发历史 |
git pull |
从另一仓库获取并合并本地的版本 |
git push |
更新远程引用和相关的对象 |
git remote |
管理跟踪远程仓库的命令 |
git fetch |
从远程仓库获取数据到本地仓库,但不自动合并 |
进阶指令
| 指令 | 描述 |
|---|---|
git stash |
暂存当前工作目录的修改,以便可以切换分支 |
git cherry-pick |
选择一个提交,将其作为新的提交引入 |
git rebase |
将提交从一个分支移动到另一个分支 |
git reset |
重设当前 HEAD 到指定状态,可选修改工作区和暂存区 |
git revert |
通过创建一个新的提交来撤销之前的提交 |
git mv |
移动或重命名一个文件、目录或符号链接,并自动更新索引 |
git rm |
从工作区和索引中删除文件 |
第四关 玩转HF/魔搭/魔乐社区
HF平台使用过程
Hugging Face Spaces 是一个允许我们轻松地托管、分享和发现基于机器学习模型的应用的平台。Spaces 使得开发者可以快速将我们的模型部署为可交互的 web 应用,且无需担心后端基础设施或部署的复杂性。
基础岛
第一关 书生大模型全链路开源体系
InternLM开源一周年
性能天梯:与GPT靠近

推理能力:指原生的推理性能,不包括agent等自定义逻辑

核心技术思路:迭代,数据质量驱动(基于规则、模型、反馈)
100万token上下文:大海捞针实验(给很长的信息,看能否定位任何位置的任何信息)
- 以前要RAG:拆分、向量化、匹配分块

7B感觉还是在检索信息,20B开始有思考的感觉

- 预训练:迁移
- 微调:常用的框架,企业经常使用
数据

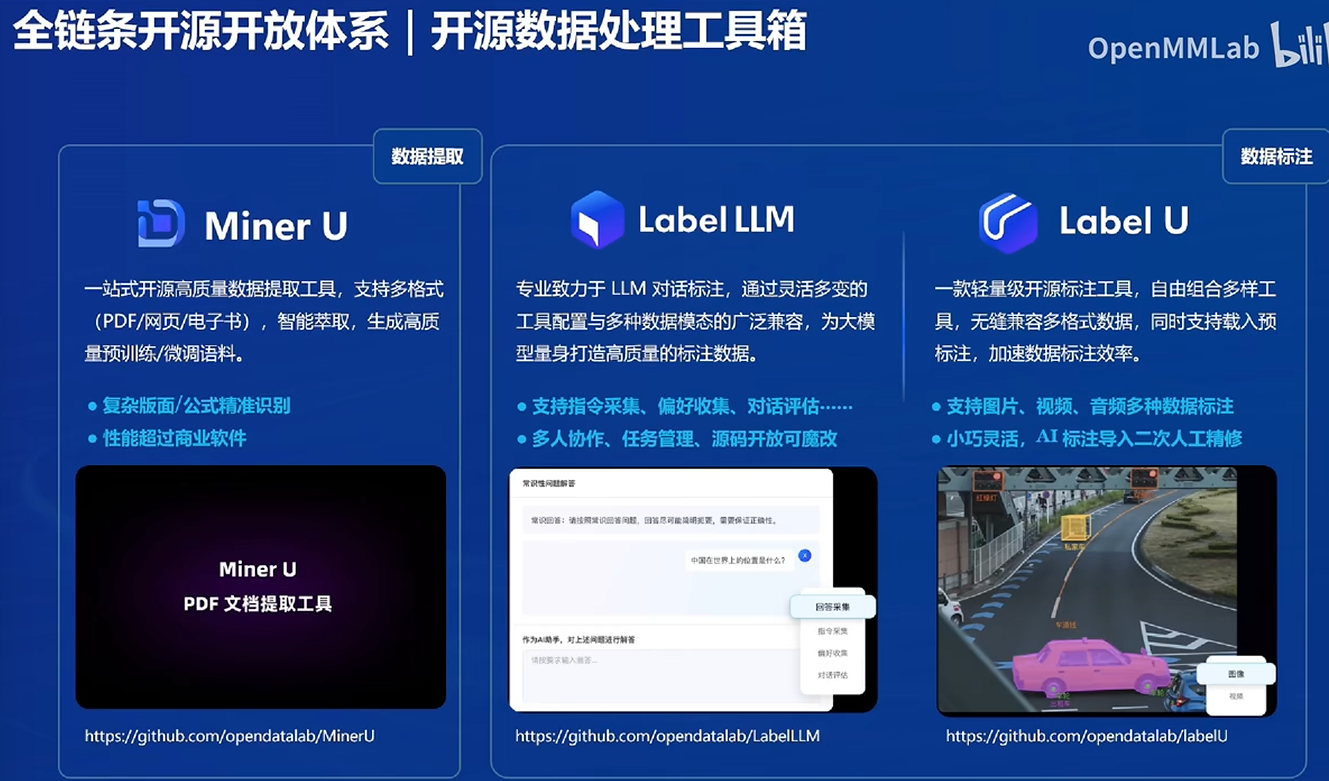
Miner U:可以解析PDF的文字内容
Label:支持标注数据
预训练

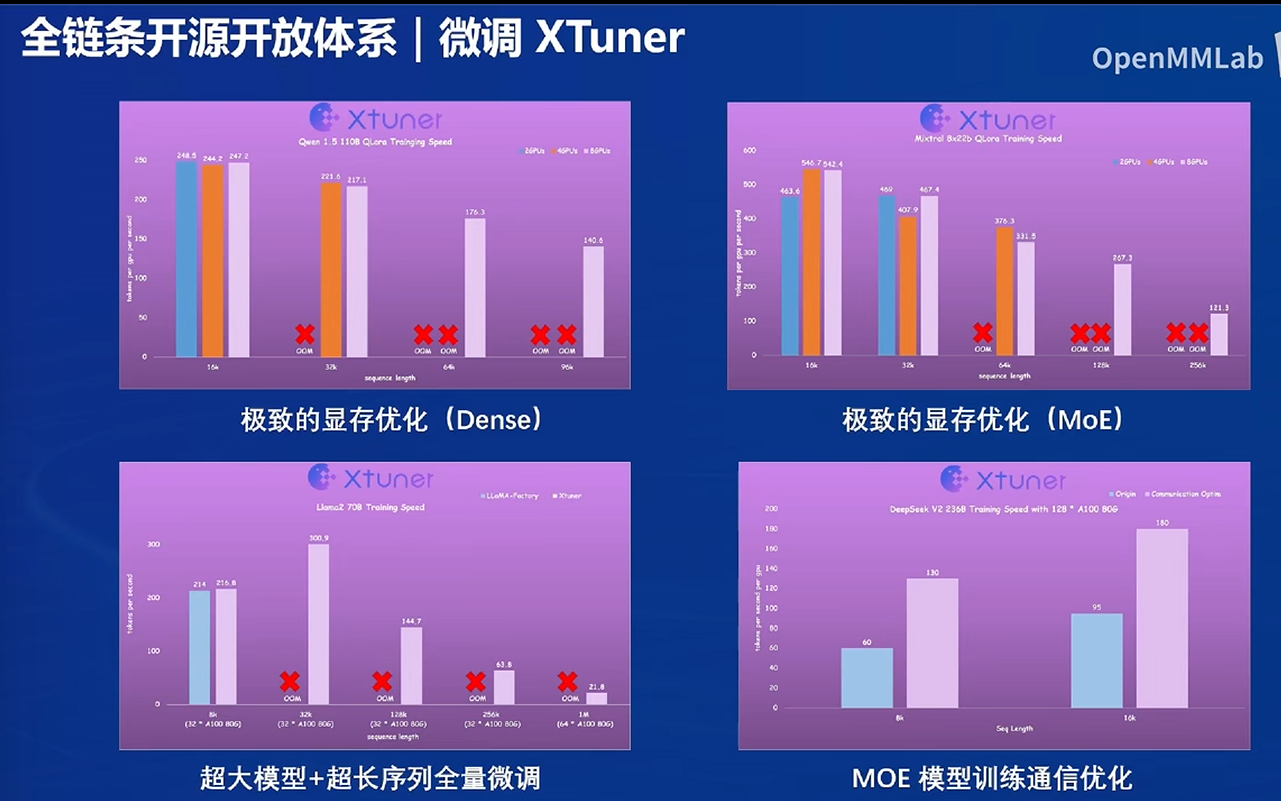
帮助降低硬件要求
全量微调个人计算机跑不起来
XTuner可以节约显存
评测


部署

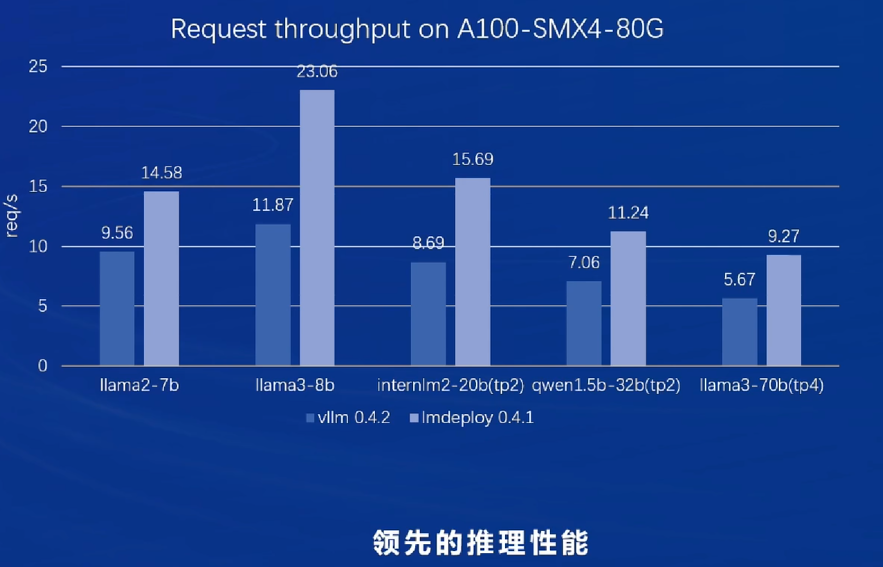
领先VLLM
应用
智能体
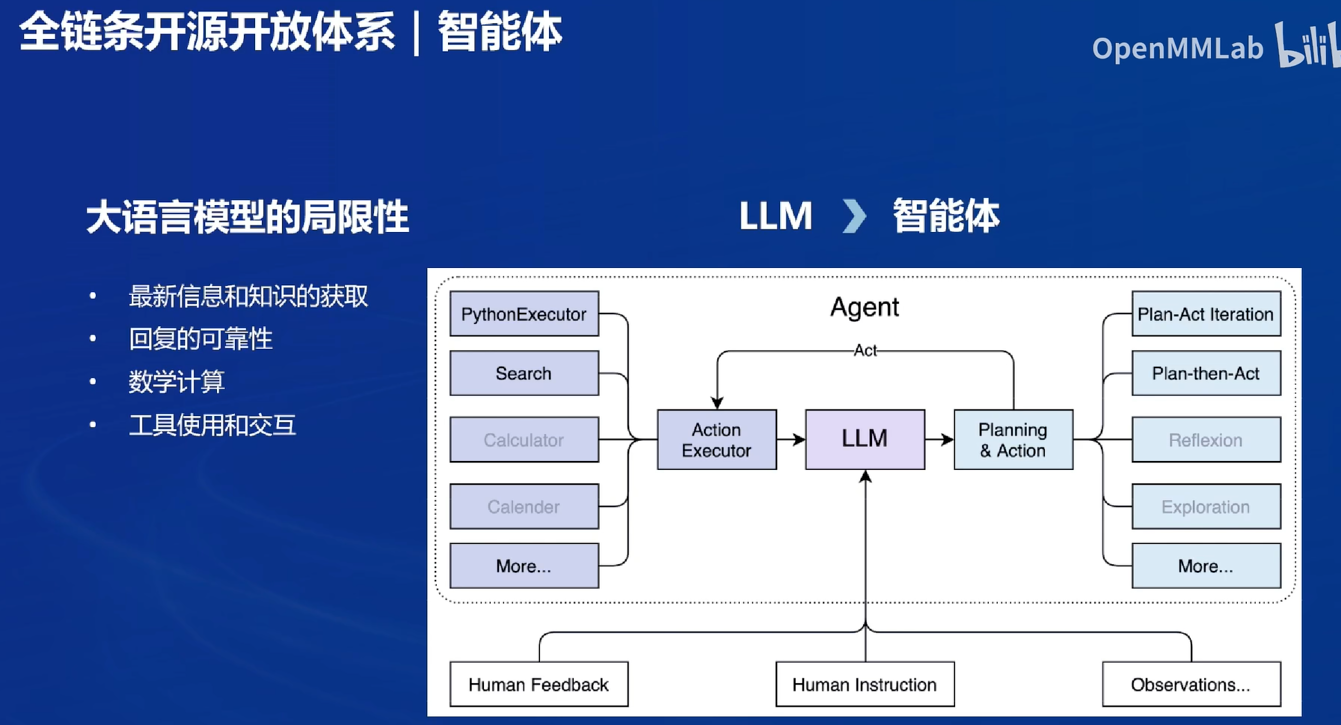

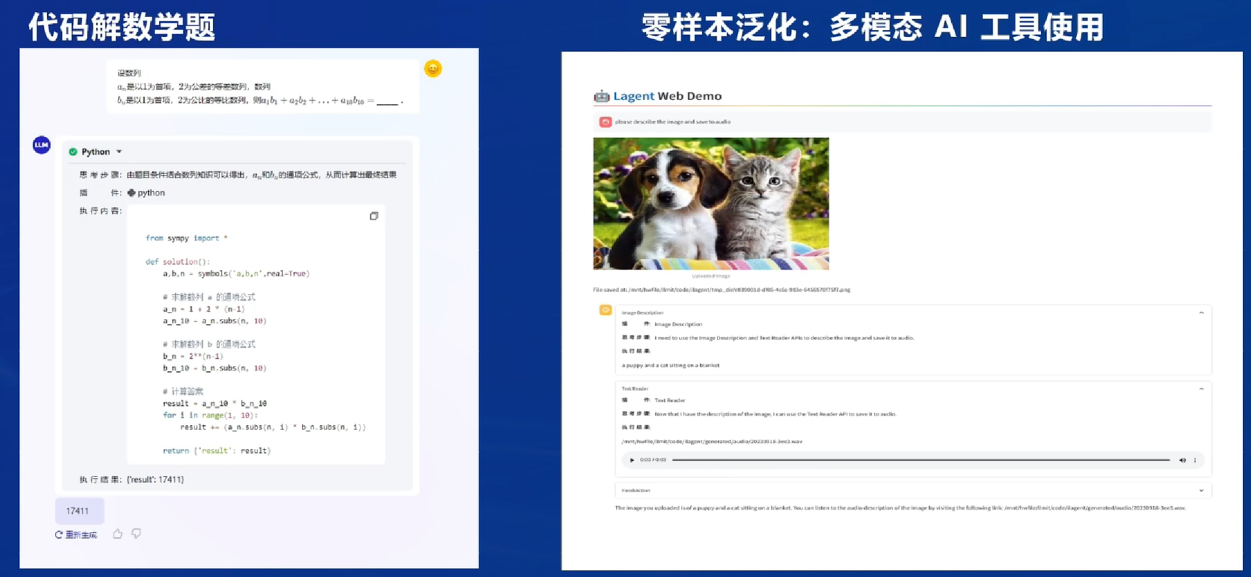
与外部进行交互:Lagent框架
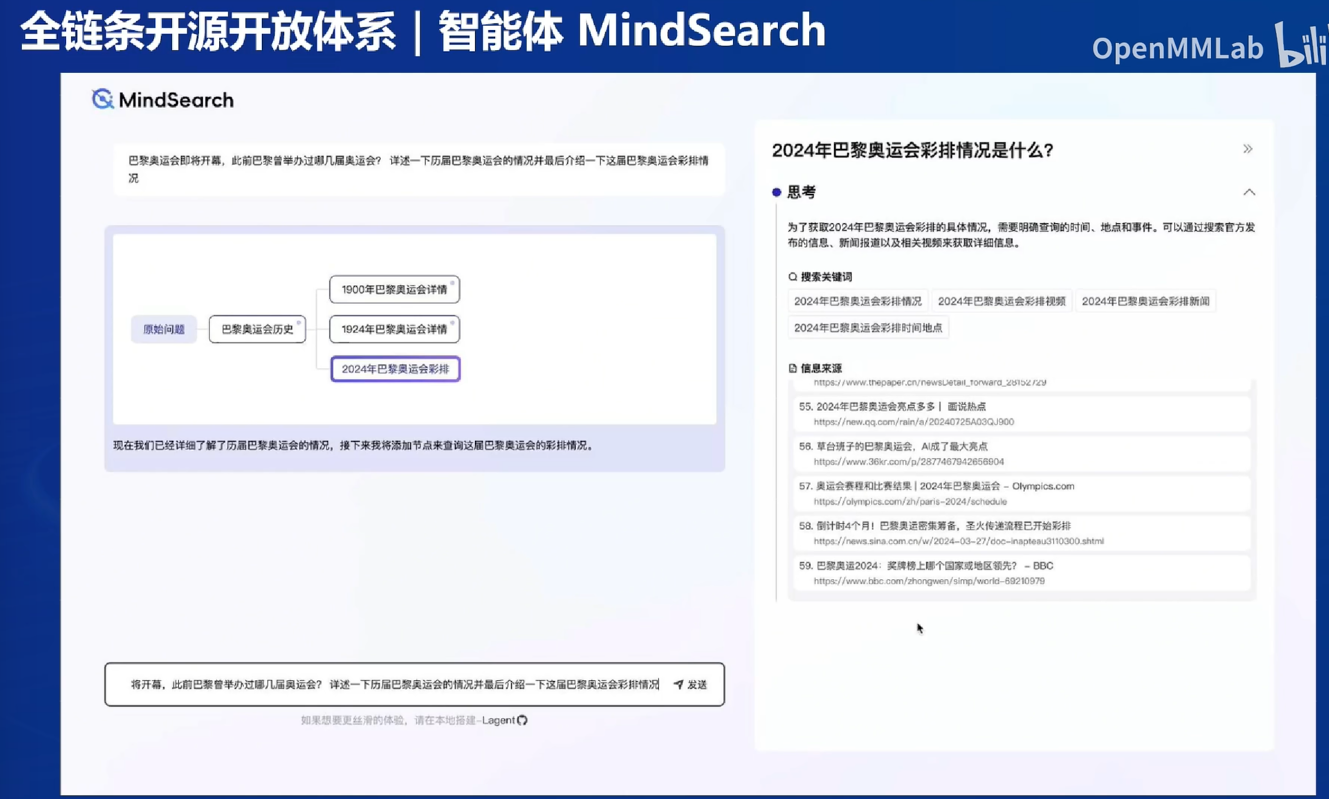
会显示每一步的思路(可视化人脑的思考路径)
知识库

知识图谱和RAG都支持

第二关 玩转书生「多模态对话」与「AI搜索」产品
基础任务
- MindSearch:点击子节点可以看到学术界或工业界的答案

- 书生浦语:翻译任务

- InternVL:图片OCR+内容理解

书生浦语:提供API控制台,20B版本,可以申请tokens
MindSearch:可以看思考过程、拆解问题、点击思维导图
文档助手:可以阅读长论文
第三关 浦语提示词工程实践
基础任务
很容易回答错误成2次,所在的位置也不对,所以引导输出每一位的字母并与r比较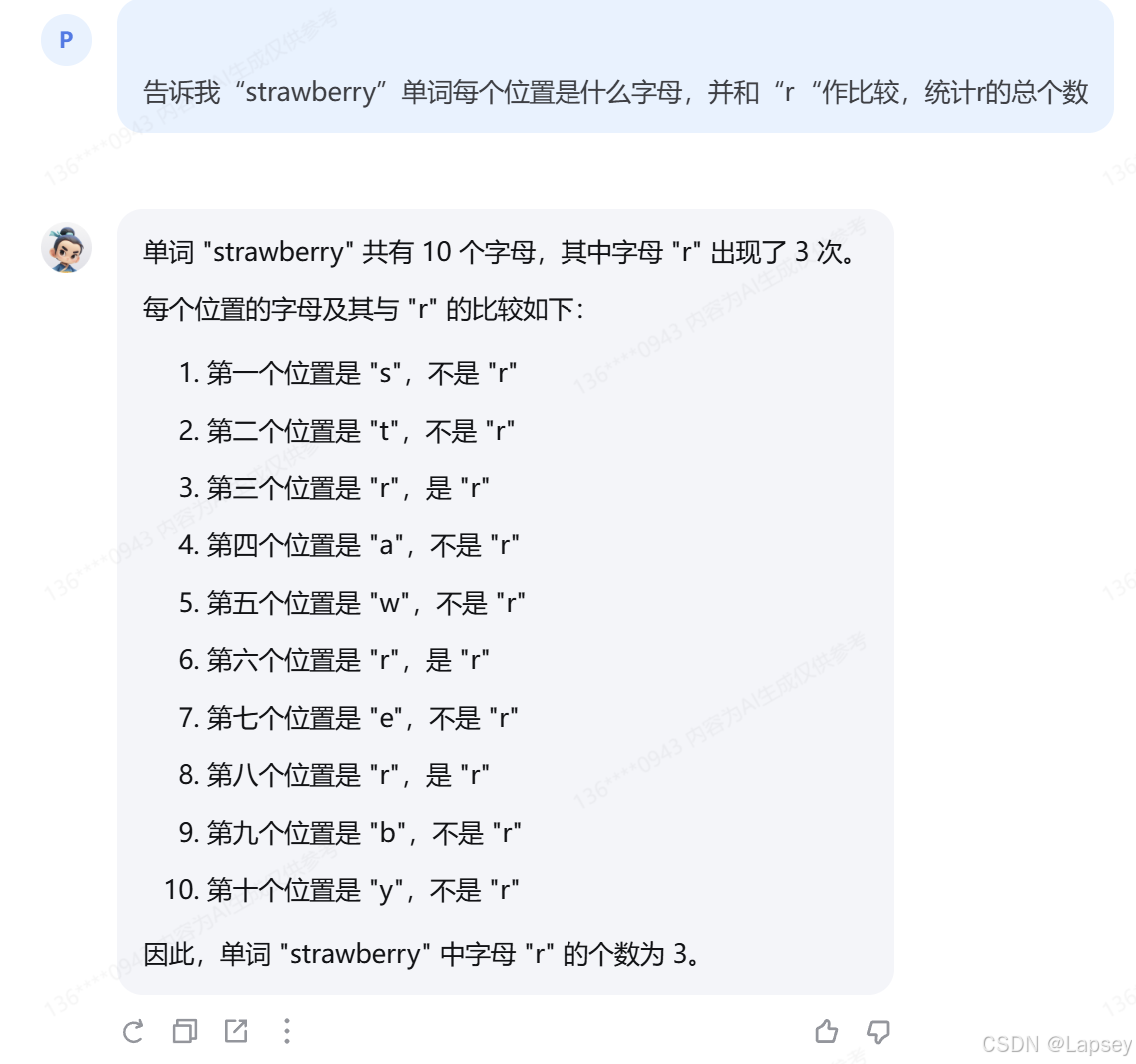
笔记与过程
Prompt
Prompt是一种用于指导以大语言模型为代表的生成式人工智能生成内容(文本、图像、视频等)的输入方式。它通常是一个简短的文本或问题,用于描述任务和要求。
作用:引导AI模型生成特定的输出
基本原理:获取文本(prompt)->处理特征->预测之后的文本。可类比输入法。多轮对话中上一次的输出作为下一次的输入。

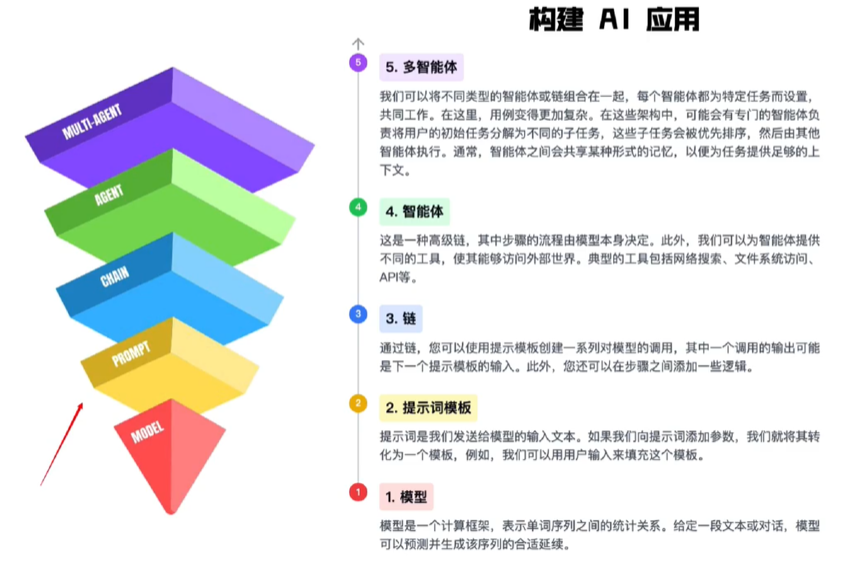
五层:
- 提示词模板:可以修改,最靠近模型层
- 链:又称AI工作流,一系列对模型的调用
提示工程
提示工程是一种通过设计和调整输入(Prompts)来改善模型性能或控制其输出结果的技术。
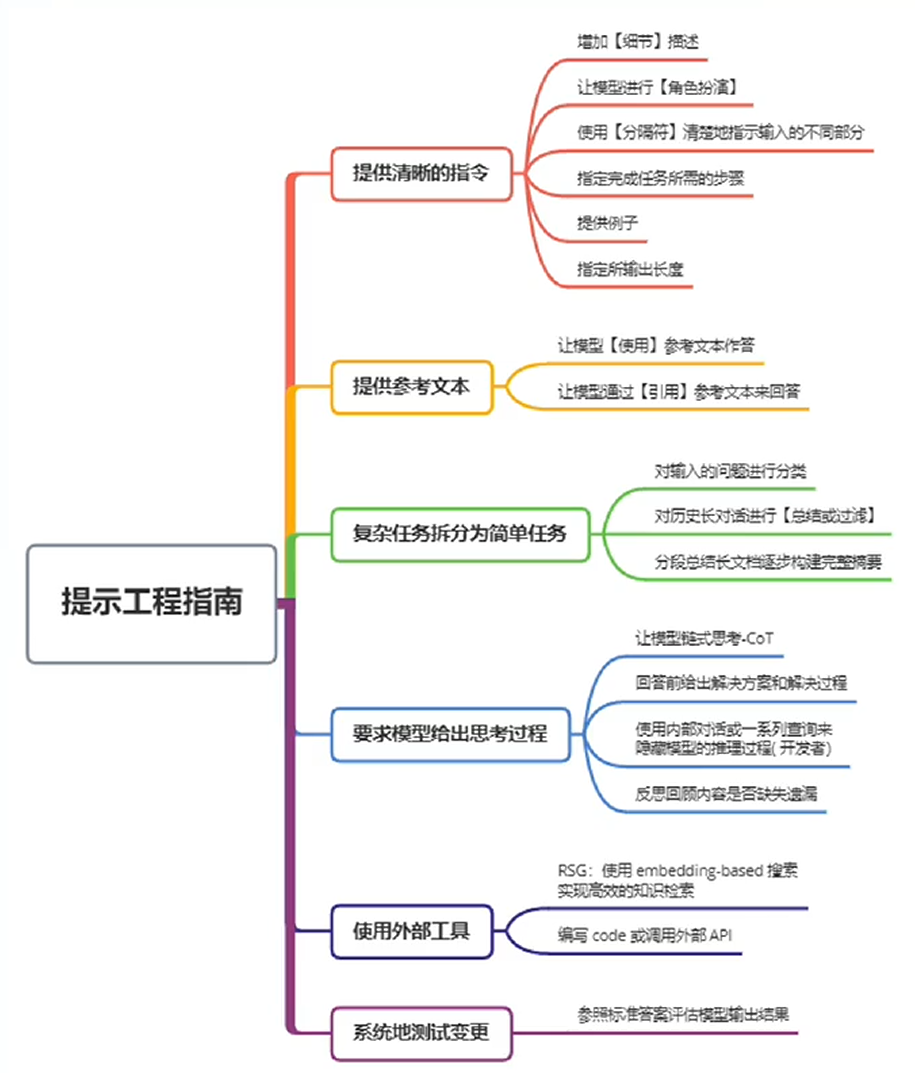
提示工程是模型性能优化的基石,有以下六大基本原则:
- 指令要清晰:细节描述
- 提供参考内容
- 复杂的任务拆分成子任务
- 给 LLM“思考”时间(给出过程)
- 使用外部工具
- 系统性测试变化
技巧:
- 描述清晰
- 角色扮演,想象你是翻译大师,有的模型有用
- 提供示例:比如仿写句子,提供2-3个高质量示例
- 复杂任务分解:思维链CoT。在指令后加上“请一步步思考,给出推理依据”即可
- 使用格式符区分语义:比如对翻译内容用##符号标识,引号不一定有用
- 情感和物质激励。比如加上“这对我的事业很重要”,“给你200小费”
- 使用更专业的术语:比如用英文的专业术语,而不是翻译后的
提示词框架
CRISPE
要求写5个方面的内容
CRISPE,参考:https://github.com/mattnigh/ChatGPT3-Free-Prompt-List
- Capacity and Role (能力与角色):希望 ChatGPT 扮演怎样的角色。
- Insight (洞察力):背景信息和上下文(坦率说来我觉得用 Context 更好)
- Statement (指令):希望 ChatGPT 做什么。
- Personality (个性):希望 ChatGPT 以什么风格或方式回答你。
- Experiment (尝试):要求 ChatGPT 提供多个答案。
1 | Act as an expert on software development on the topic of machine learning frameworks, and an expert blog writer. The audience for this blog is technical professionals who are interested in learning about the latest advancements in machine learning. Provide a comprehensive overview of the most popular machine learning frameworks, including their strengths and weaknesses. Include real-life examples and case studies to illustrate how these frameworks have been successfully used in various industries. When responding, use a mix of the writing styles of Andrej Karpathy, Francois Chollet, Jeremy Howard, and Yann LeCun. |
CO-STAR
- Context (背景): 提供任务背景信息
- Objective (目标): 定义需要LLM执行的任务
- Style (风格): 指定希望LLM具备的写作风格
- Tone (语气): 设定LLM回复的情感基调
- Audience (观众): 表明回复的对象
- Response (回复): 提供回复格式
观众和回复是区别于CRISPE的地方
CRISPE可能更适合任务类,CO-STAR适合角色类(如虚拟陪伴)
例如我们设计一个解决方案专家,用于把目标拆解为可执行的计划,完成的提示词如下:
1 | # CONTEXT # |
LangGPT结构化提示词
类似CO-STAR(但Lang提出更早)

结构化就像把作文题变成填空题
LangGPT是面向对象的,包含模块-内部元素两级,针对不同的场景可以修改不同的模块。模块表示要求或提示LLM的方面,例如:背景信息、建议、约束等。内部元素为模块的组成部分,是归属某一方面的具体要求或辅助信息,分为赋值型和方法型。
编写技巧:
- 构建全局思维链CoT。Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
- 保持上下文语义一致性(内容和格式)
- 有机结合其他 Prompt 技巧
- 细节法:给出更清晰的指令,包含更多具体的细节
- 分解法:将复杂的任务分解为更简单的子任务 (Let’s think step by step, CoT,LangChain等思想)
- 记忆法:构建指令使模型时刻记住任务,确保不偏离任务解决路径(system 级 prompt)
- 解释法:让模型在回答之前进行解释,说明理由 (CoT 等方法)
- 投票法:让模型给出多个结果,然后使用模型选择最佳结果 (ToT 等方法)
- 示例法:提供一个或多个具体例子,提供输入输出示例 (one-shot, few-shot 等方法)
常见的提示词模块
- Attention:需重点强调的要点
- Background:提示词的需求背景
- Constraints:限制条件
- Command:用于定义大模型指令
- Definition:名词定义
- Example:提示词中的示例few-shots
- Fail:处理失败时对应的兜底逻辑
- Goal:提示词要实现的目标
- Hack:防止被攻击的防护词
- In-depth:一步步思考,持续深入
- Job:需求任务描述
- Knowledge:知识库文件
- Lawful:合法合规,安全行驶的限制
- Memory:记忆关键信息,缓解模型遗忘问题
- Merge:是否使用多角色,最终合并投票输出结果
- Neglect:明确忽略哪些内容
- Odd:偶尔 (俏皮,愤怒,严肃) 一下
- OutputFormat:模型输出格式
- Pardon:当用户回复信息不详细时,持续追问
- Quote:引用知识库信息时,给出原文引用链接
- Role:大模型的角色设定
- RAG:外挂知识库
- Skills:擅长的技能项
- Tone:回复使用的语气风格
- Unsure:引入评判者视角,当判定低于阈值时,回复安全词
- Vaule:Prompt模仿人格的价值观
- Workflow:工作流程
- X-factor:用户使用本提示词最为重要的内核要素
- Yeow:提示词开场白设计
- Zig:无厘头式提示词,如[答案之书]
三个实践
- 写一段话介绍AI大模型实战营,添加emoji表情,添加结构化模板
- 输出是md格式
- 提示词可以作为系统提示(推荐),也可以直接作为交互对话的输入
1 | 你是提示词专家,根据用户的输入设计用于生成**高质量(清晰准确)**的大语言模型提示词。 |
可以帮忙创建很多需求,如商业邮件,把回复再作为新的输入即可。
AI一键写书功能
https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/Prompt/practice.md
直接的聊天窗口只有大纲,但部署后可以直接用
BookAI项目分析(在intern_studio开发机上做的)
- books:生成的书籍存在这里(并不是示例)配了图但没有图所以不显示。F1公式之类的都有
- prompts:
- title:帮助用户为书籍创建有吸引力的标题和简介,确保书名与书籍内容相符,简介清晰传达书籍核心主题
- outline:帮助用户根据书籍的标题和简介,设计出完整的书籍大纲,确保结构清晰,逻辑合理,并符合书籍的主题和风格。
- chapter:帮助用户根据提供的书籍标题、简介和章节大纲,撰写每一章的具体内容,确保语言风格符合书籍定位,内容连贯、专业、正式。
总结:一本书写不完->拆解为一章章写->但连贯性如何保证?写大纲->大纲根据标题和简介写。控制格式、连贯性、并行性
1 | import os |
顺序是标题->大纲->正文
第四关 InternLM + LlamaIndex RAG 实践
基础任务
因为利用浦语 API+LlamaIndex实践时,我一直遇到ascii的报错而导致不管是否使用RAG都不能进行对话;而用本地部署InternLM+LlamaIndex实践没有遇到问题。
所以这里使用 InternLM2-Chat-1.8B 模型。
以“Soot是什么”问题为例:本来不知道
加了RAG
笔记与过程
RAG
检索增强生成(Retrieval Augmented Generation,RAG),利用外部知识库增强性能
- 可以补充最新信息
- 补充过程
给模型注入新知识的方式,可以简单分为两种方式
- 内部的,即更新模型的权重,代价大,因为大模型要重新训练
- 外部的,给模型注入格外的上下文或者说外部信息,不改变它的的权重

工作原理:用户输入对话或者推荐问题,首先在数据库进行检索,然后把检索的内容(这里就是RAG优化的部分)和问题作为prompt输入给大模型,生成答案
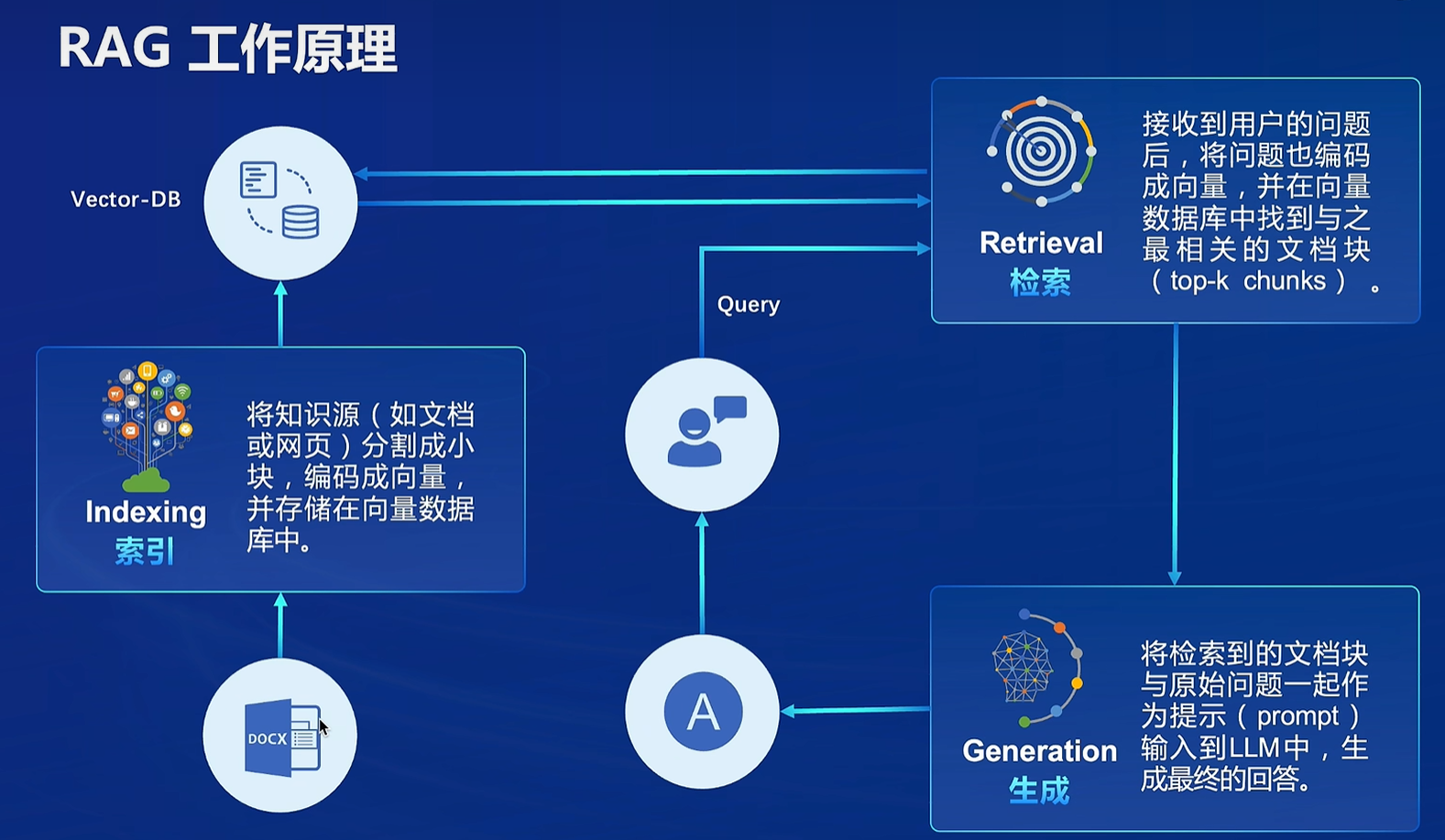
向量数据库:承担所有数据存储

发展进程:最早就是文档-索引-检索
Advanced:多了两次检索。对问题有一次检索,拿到结果后重排或压缩
多模态:模块化工程化

常见优化:相关论文有很多最新方法

RAG vs 微调
RAG:不改变模型,使用外部信息,用于需要最新信息和实时数据的任务
- 长尾知识:训练集中的少数类别 (head class) 含有训练集中的多数标注数据,而大量其余类别 (tail class) 仅有少数标注数据(有些只有一份,微调会有bias)
- 提升不会打破大模型,根本性能还是基于大模型,RAG只是提升

微调:重新训练参数集,适应特定任务。需要大量标注数据。
- 可能会过拟合,可能有长尾问题
- 对实时数据要求不高,专业度要求高,点对点,很适合微调


微调:模型适配度高、实时性低
评估框架和基准测试

安全性也有
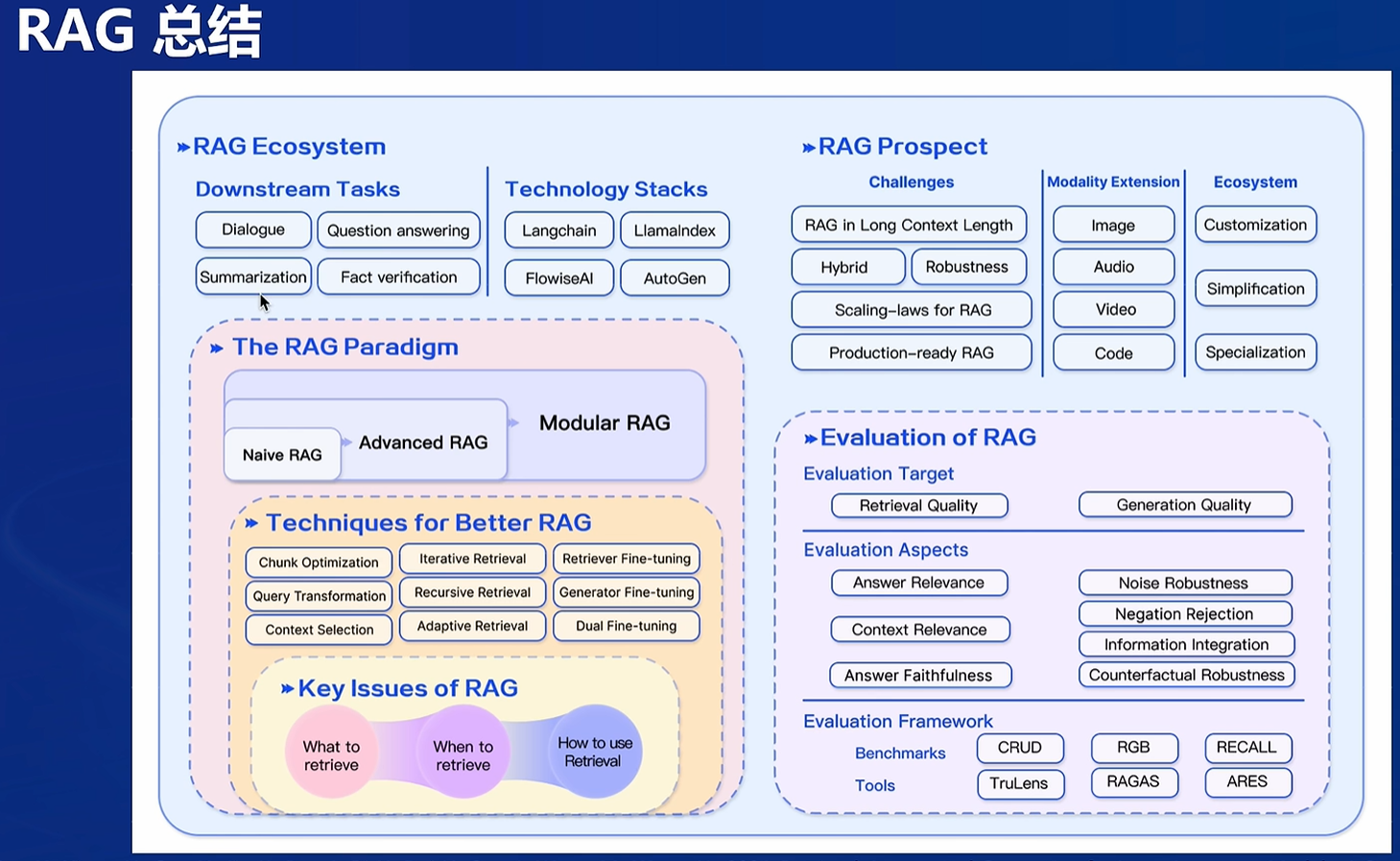
技术栈:Langchain、LlamaIndex
挑战:长文本数据(基于大模型)、多模态
LlamaIndex
开源的索引和搜索库

特点:
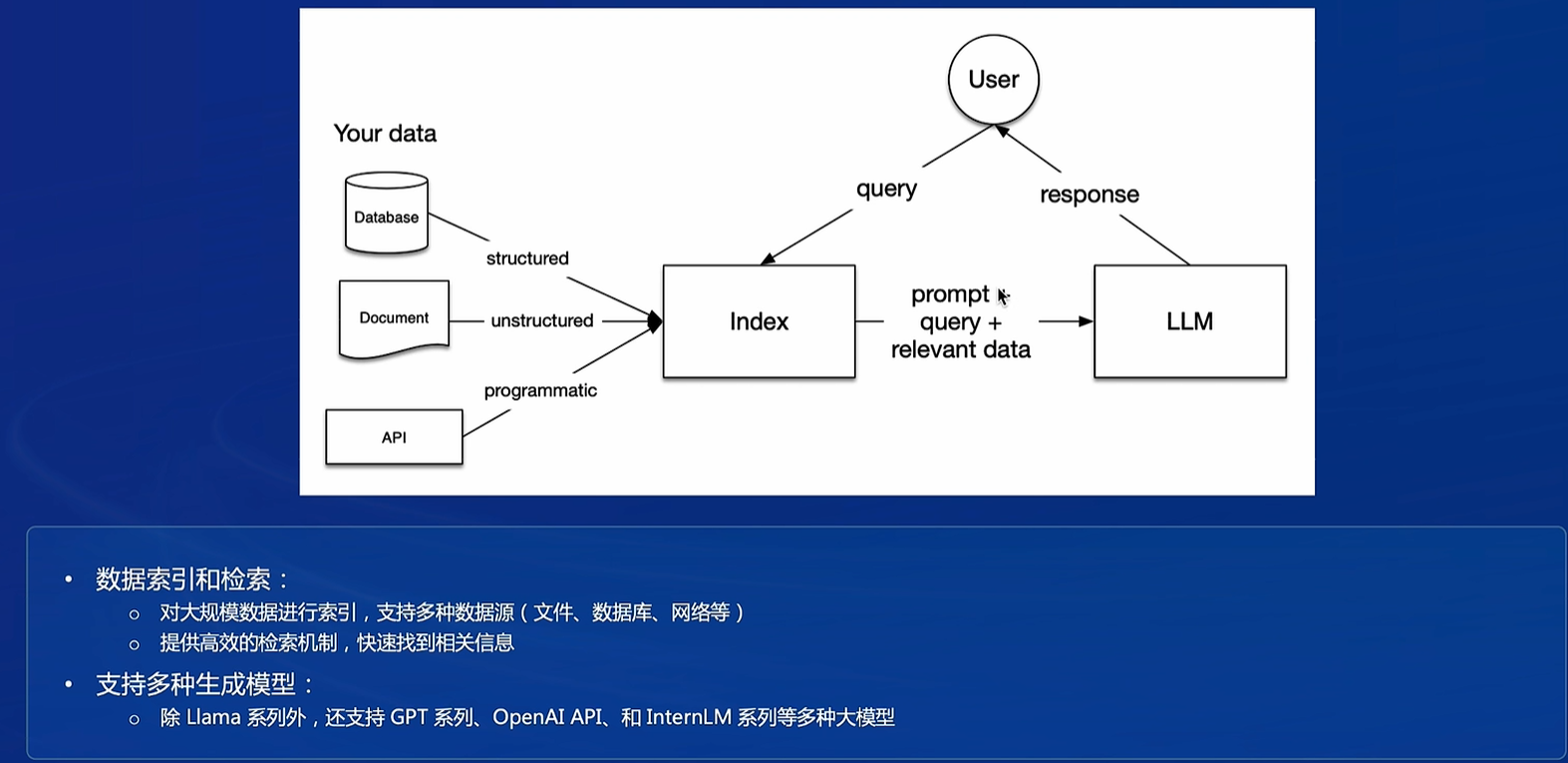
应用:Hub提供很多数据,调API即可,自己搭建的部分很少

实践
问xtuner是什么

浦语 API+LlamaIndex 实践(助教反而用的是本地部署InternLM+LlamaIndex实践):https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/LlamaIndex/readme_api.md
- 配置python环境、Llamaindex环境
- 下载 Sentence Transformer 模型(开源词向量模型,轻量,支持中文且效果较好)
- 下载NLTK库
- 是否使用 LlamaIndex 前后对比
- 不使用 LlamaIndex RAG(仅API):浦语官网和硅基流动都提供了InternLM的类OpenAI接口格式的免费的 API。这一步我有报错,试了些设置utf8也未解决(明天再试试)

- 使用 API+LlamaIndex:读取md,作为向量数据库
- 不使用 LlamaIndex RAG(仅API):浦语官网和硅基流动都提供了InternLM的类OpenAI接口格式的免费的 API。这一步我有报错,试了些设置utf8也未解决(明天再试试)
- 命令行格式变成页面格式:使用streamlit
所以用本地部署InternLM+LlamaIndex实践:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/LlamaIndex/readme_local.md
LlamaIndex HuggingFaceLLM:
1 | from llama_index.llms.huggingface import HuggingFaceLLM |

LlamaIndex RAG:
1 | from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings |
streamlit可视化网页的代码:
1 | import streamlit as st |
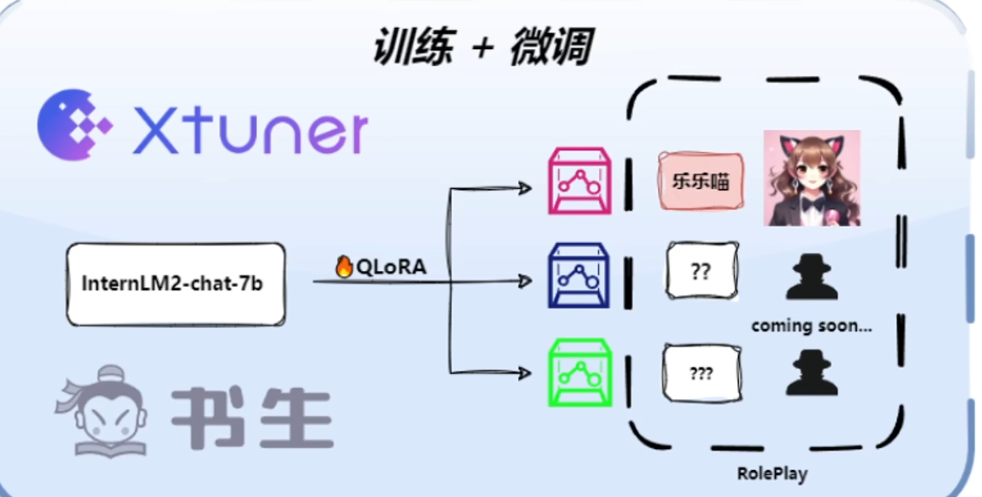
第五关 XTuner 微调个人小助手认知
基础任务
使用 XTuner 微调 InternLM2-Chat-7B 实现自己的小助手认知,如下图所示(图中的尖米需替换成自己的昵称),记录复现过程并截图。(即微调一个adapter然后合并到模型中)
环境配置和数据准备
- 使用 conda 先构建一个 Python-3.10 的虚拟环境
- 安装 XTuner
- 验证安装
修改提供的数据
创建一个新的文件夹用于存储微调数据
创建修改脚本:批量处理 JSON 数据、替换成自己的名字(本任务是修改的已有数据,如果想要新数据可以使用LLM获得)
执行脚本

模型启动复制模型
修改Config:设置预训练模型路径、数据路径、数据集加载路径


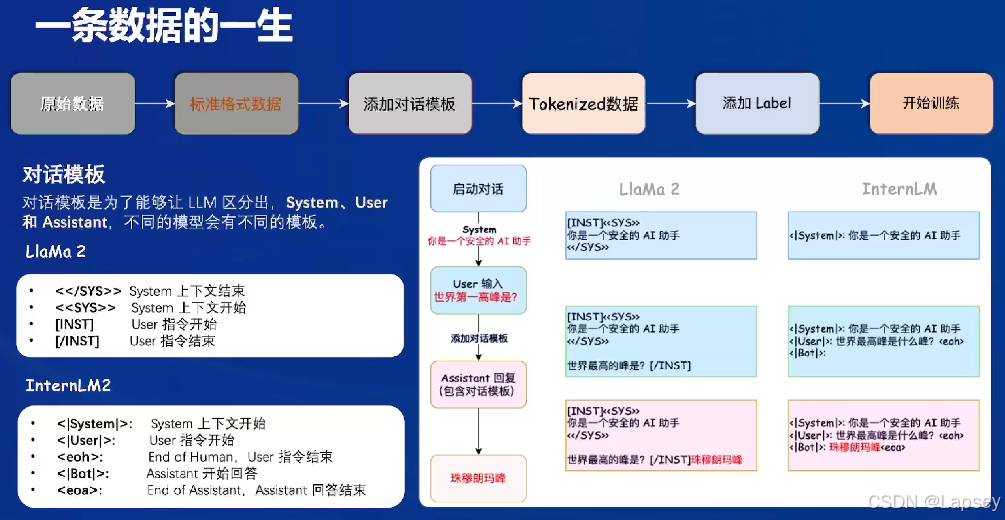
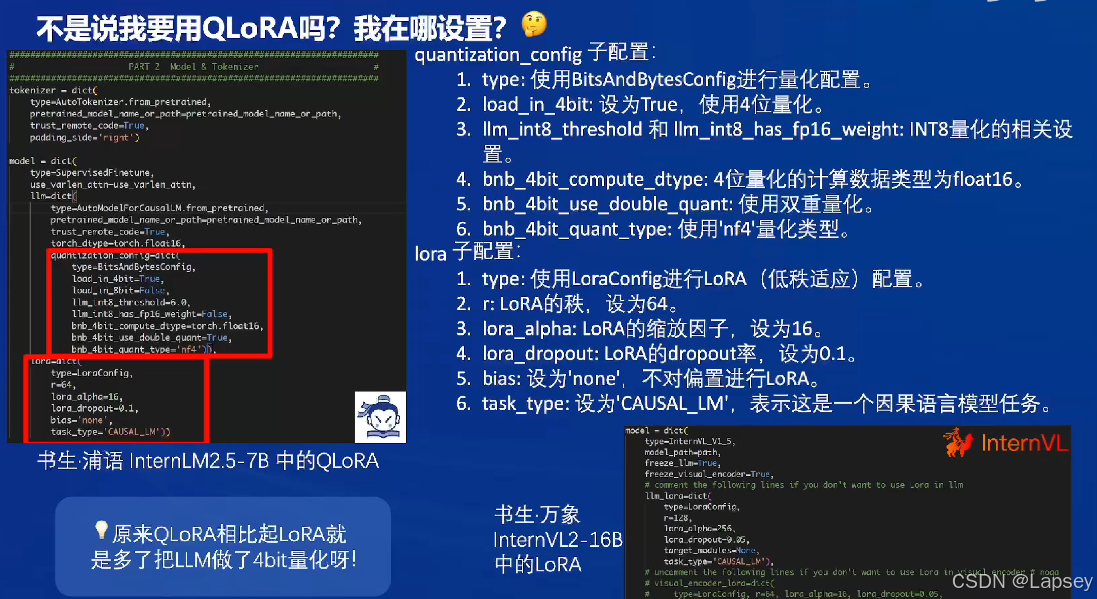
数据从哪里来:找LLM要,用常见问题得到的回答作为训练数据
启动微调
xtuner train 命令用于启动模型微调进程。该命令需要一个参数:CONFIG 用于指定微调配置文件。这里我们使用修改好的配置文件 internlm2_5_chat_7b_qlora_alpaca_e3_copy.py。
训练过程中产生的所有文件,包括日志、配置文件、检查点文件、微调后的模型等,默认保存在 work_dirs 目录下,我们也可以通过添加 –work-dir 指定特定的文件保存位置。–deepspeed 则为使用 deepspeed, deepspeed 可以节约显存。

- 权重转换:模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件。转换完成后,可以看到模型被转换为 HuggingFace 中常用的 .bin 格式文件,这就代表着文件成功被转化为 HuggingFace 格式了。此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”。可以简单理解:LoRA 模型文件 = Adapter
- 模型合并:对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 Adapter ,因此是不需要进行模型整合的。
在 XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
最后使用streamlit实现模型 WebUI 对话,此时使用的权重是微调之后的权重,模型是合并后的模型。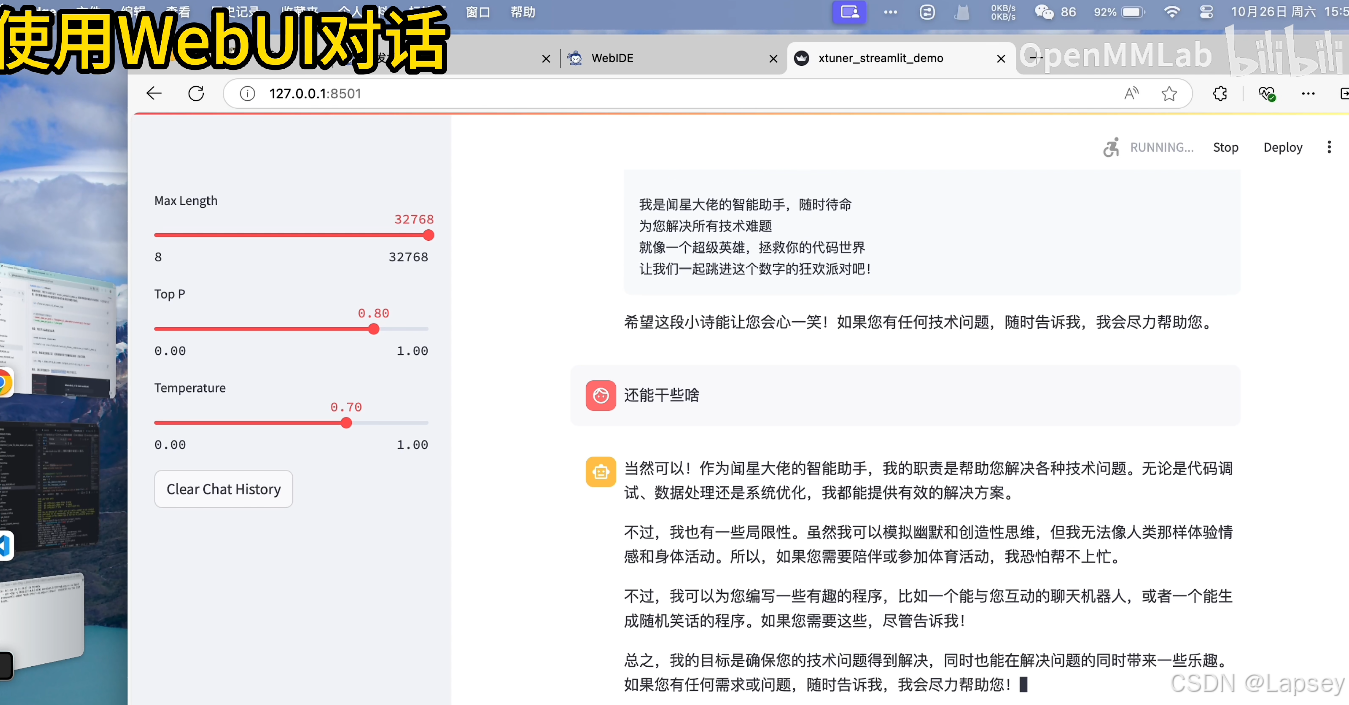
笔记与过程
微调:在预训练的LLM上,使用特定任务的数据训练模型
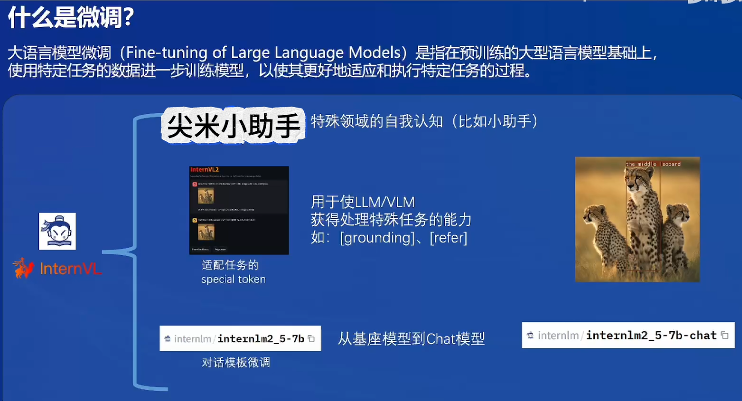
显卡数据有限,在其他大模型上做微调:

增量预训练微调:学习新知识,先做这个,使用的数据比较多,每类数据不一样
指令跟随微调:对话模板,再做这个

LoRA
在linear旁新增支路
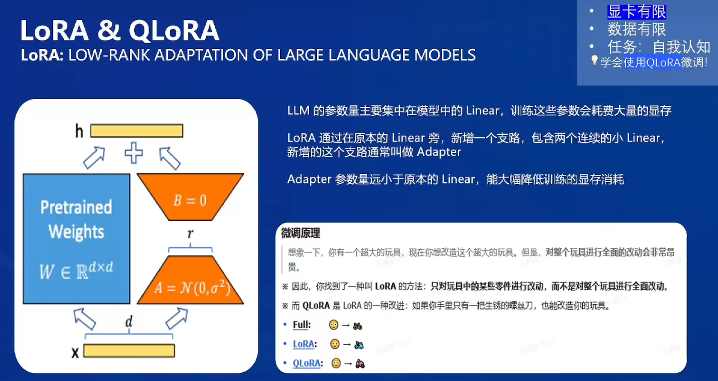
- 全量微调:优化器状态是什么?
- aLoRA:adapter训练
- QLoRA:QLoRA对adapter进一步优化

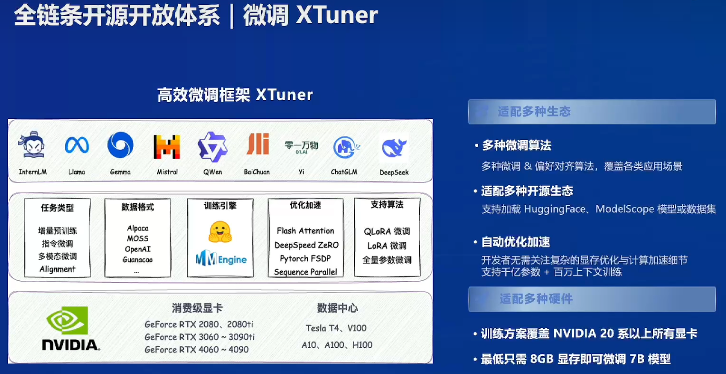
书生的微调工具XTuner:包括多种微调方法

第六关 OpenCompass 评测书生大模型实践
基础任务
OpenCompass 提供了 API 模式评测和本地直接评测两种方式。其中 API 模式评测针对那些以 API 服务形式部署的模型,而本地直接评测则面向那些可以获取到模型权重文件的情况。
比如GPT闭源,用API;Meta的Llama/openMMlab的iternlm模型开源,可以本地运行
- API评测:配置模型和数据集,在 –debug 模式下,任务将按顺序执行,并实时打印输出(并不是很懂最后一列的数字的性能含义)
- 评测本地模型:首先需要获取到完整的模型权重文件。以开源模型为例,你可以从 Hugging Face 等平台下载模型文件。接下来,你需要准备足够的计算资源,比如至少一张显存够大的 GPU,因为模型文件通常都比较大。有了模型和硬件后,你需要在评测配置文件中指定模型路径和相关参数,然后评测框架就会自动加载模型并开始评测。这种评测方式虽然前期准备工作相对繁琐,需要考虑硬件资源,但好处是评测过程完全在本地完成,不依赖网络状态,而且你可以更灵活地调整模型参数,深入了解模型的性能表现。这种方式特别适合需要深入研究模型性能或进行模型改进的研发人员。
笔记与过程
评测可以知道大模型的性能;对于医疗、金融等垂直领域也需要评测
挑战:从对话到智能体,评测体系变化
根据模型类型的不同进行不同的评测设计

评测也可以分为客观和主观,更多考虑摸模型评测
- 也有长文本评测:在长文本中插入一句话(主题可能不相关),如果能记住这句话,说明长文本效果好

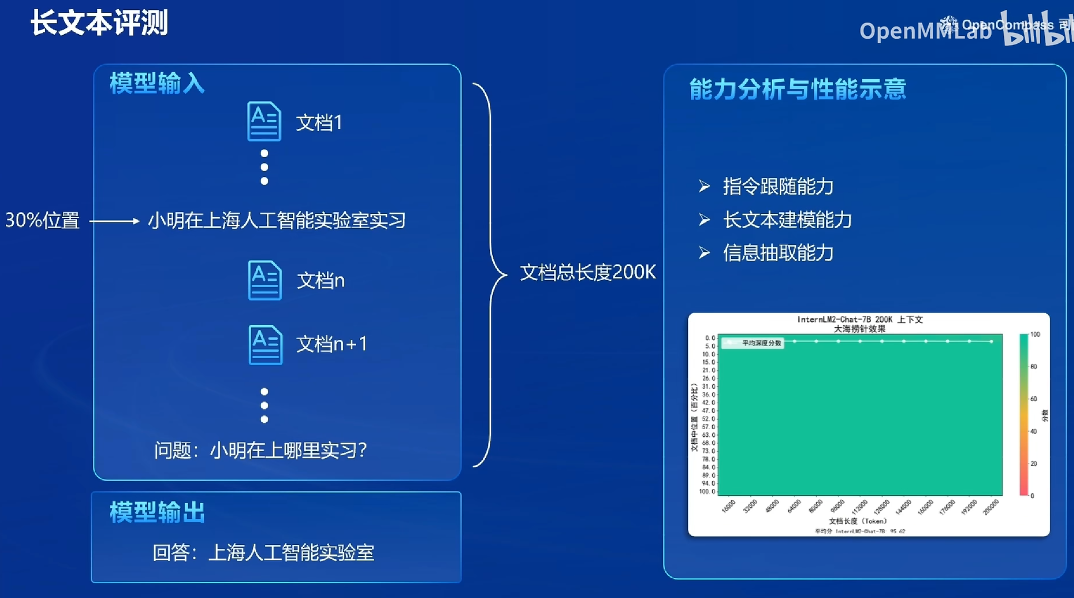


司南生态
根据社区需求实时更新榜单

榜单除了大模型,还包括多模态
正在替换推理模型进行提速
CompassBench闭源评测集
主观:对战胜率:包括创造、语言、数学、推理

客观:选择和填空

用直方图进行直观排名
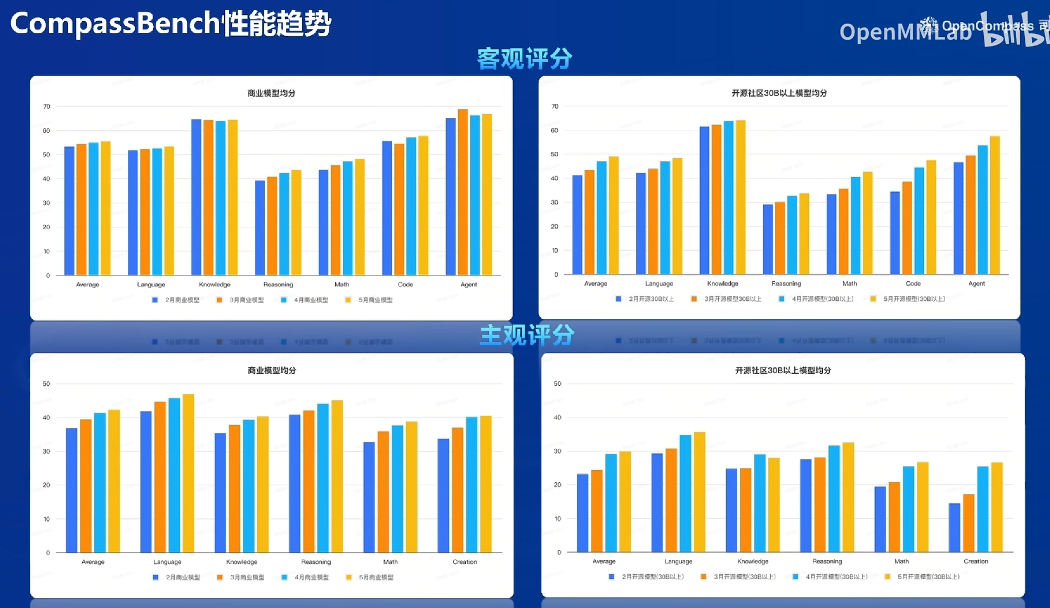
结果:


司南榜单矩阵

反映模型能力的差距:
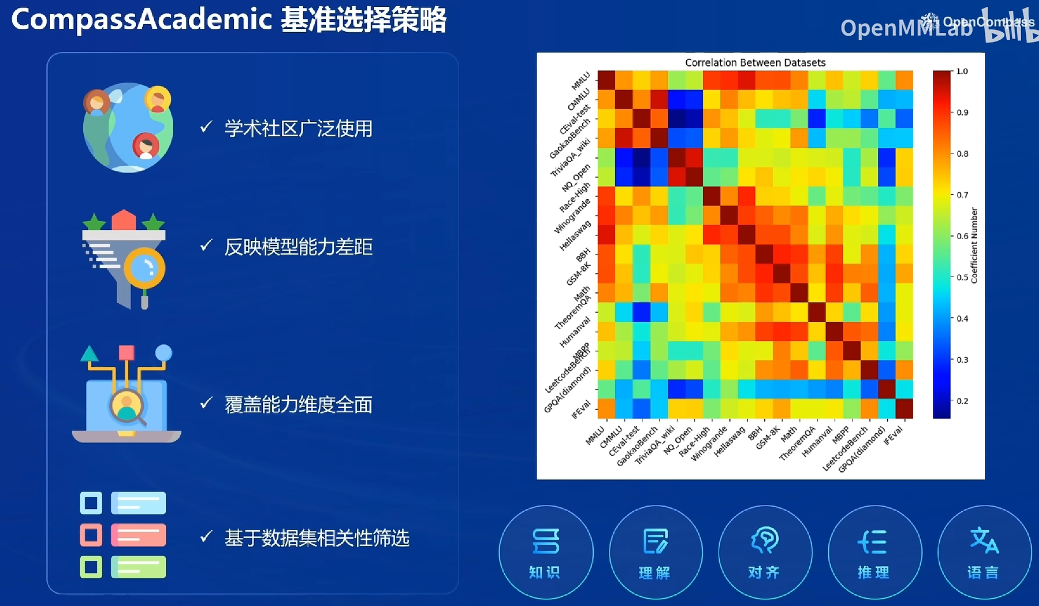
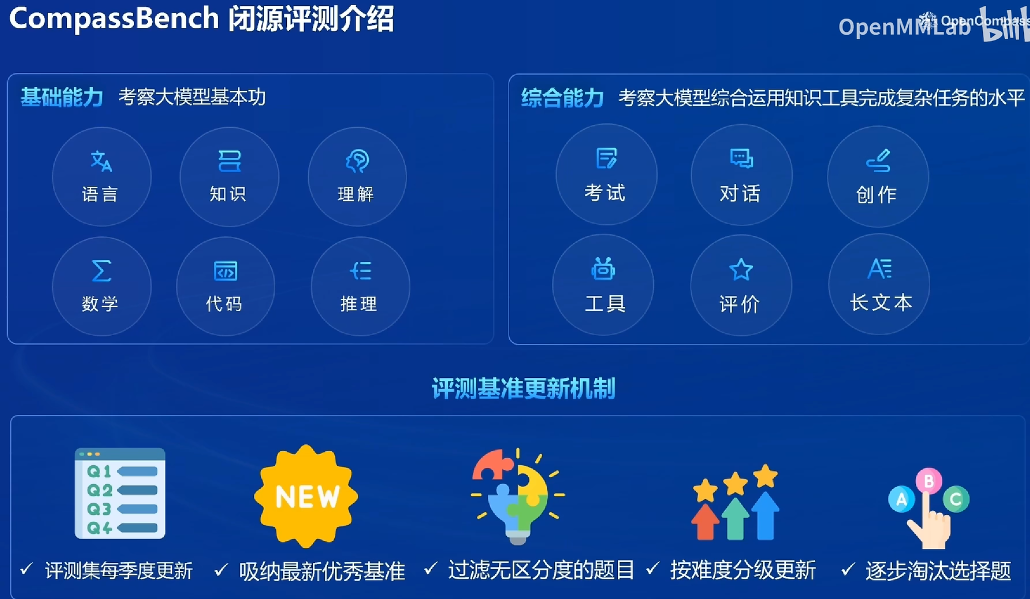
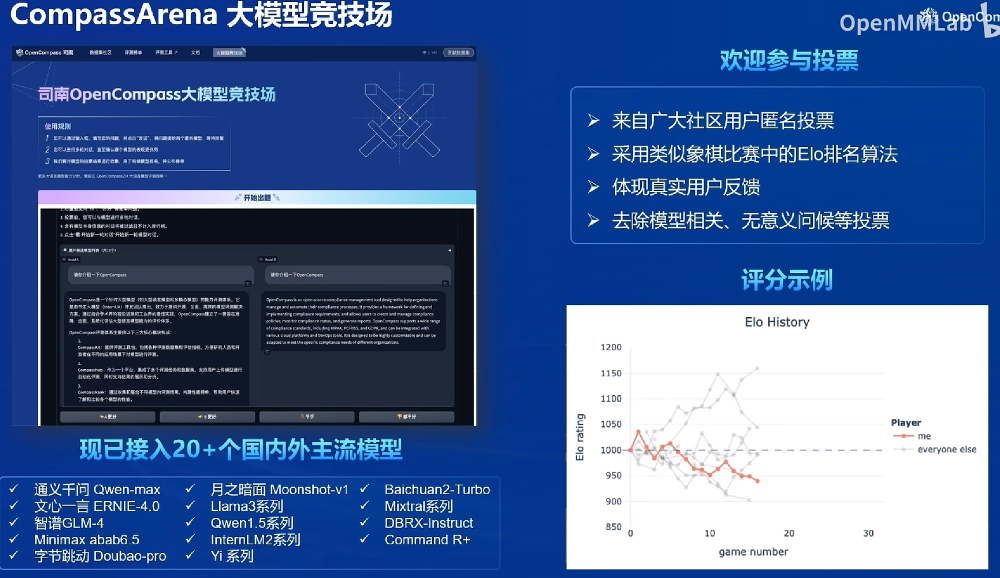
司南评测研究成果



未来计划:

进阶岛
第一关 探索书生大模型能力边界
笔记与过程
InternThinker: https://internlm-chat.intern-ai.org.cn/internthinker
InternThinker 是一个强推理模型,具备长思维能力,并能在推理过程中进行自我反思和纠正,从而在数学、代码、推理谜题等多种复杂推理任务上取得更优结果。在解力扣时往往表现得比InternLM好。
第二关 Lagent 自定义你的 Agent 智能体
基础任务
Lagent框架中Agent的使用:Action,也称为工具,Lagent中集成了很多好用的工具,提供了一套LLM驱动的智能体用来与真实世界交互并执行复杂任务的函数,包括谷歌文献检索、Arxiv文献检索、Python编译器等。具体可以查看文档
- 可以理解为集成了普通LLM没有的更丰富/复杂的函数,如文献检索
- 集成的方式是调用已有的接口,总之就是可以利用现成的API,没必要自己通过微调/RAG实现某功能
在agent_api_web_demo.py中写入下面的代码,这里利用 GPTAPI 类,该类继承自 BaseAPILLM,封装了对 API 的调用逻辑,然后利用Streamlit启动Web服务:
1 | def initialize_chatbot(self, model_name, api_base, plugin_action): |
记得在本地进行端口映射。
将ArxivSearch插件选择上,再次输入指令“帮我搜索一下最新版本的MindSearch论文”,可以看到,通过调用外部工具,大模型成功理解了我们的任务,得到了我们需要的文献:
制作一个属于自己的Agent
使用 Lagent 自定义工具主要分为以下3步:
(1)继承 BaseAction 类
(2)实现简单工具的 run 方法;或者实现工具包内每个子工具的功能
(3)简单工具的 run 方法可选被 tool_api 装饰;工具包内每个子工具的功能都需要被 tool_api 装饰
1 | import os |
其中,WeatherQuery 类继承自 BaseAction,这是 Lagent 的基础工具类,提供了工具的框架逻辑。tool_api 是一个装饰器,用于标记工具中具体执行逻辑的函数,使得 Lagent 智能体能够调用该方法执行任务。run 方法是工具的主要逻辑入口,通常会根据输入参数完成一项任务并返回结果。
在具体函数实现上,利用GeoAPI 获取 LocationID,当用户输入的 location 不是经纬度坐标格式(如 116.41,39.92),则使用和风天气的 GeoAPI 将位置名转换为 LocationID,并通过 Weather API 获取目标位置的实时天气数据。最后,解析返回的 JSON 数据,并格式化为结构化字典。
注意在lagent的init方法和web demo脚本都要将该新增的工具注册进大模型的插件列表中。
将2个插件同时勾选上,用以说明模型具备识别调用不同工具的能力,什么任务对应什么工具来解决。
Multi-Agents博客写作系统的搭建
使用 Lagent 来构建一个多智能体系统 (Multi-Agent System),展示如何协调不同的智能代理完成内容生成和优化的任务。我们的多智能体系统由两个主要代理组成:
(1)内容生成代理:负责根据用户的主题提示生成一篇结构化、专业的文章或报告。
(2)批评优化代理:负责审阅生成的内容,指出不足,推荐合适的文献,使文章更加完善。
Multi-Agents博客写作系统的流程图如下: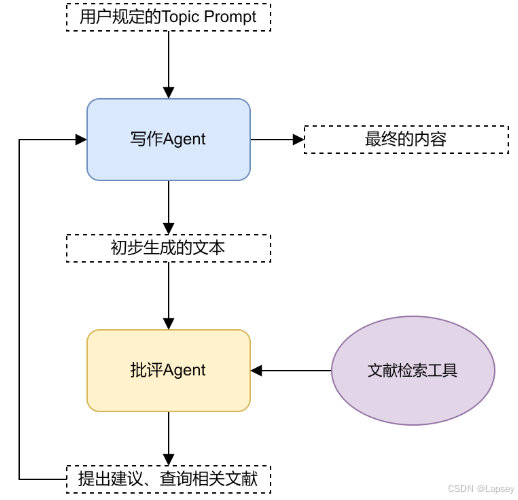
可以看到,Multi-Agents博客写作系统正在按照下面的3步骤,生成、批评和完善内容。
Step 1:写作者根据用户输入生成初稿。
Step 2:批评者对初稿进行评估,提供改进建议和文献推荐(通过关键词触发 Arxiv 文献搜索)。
Step 3:写作者根据批评意见对内容进行改进。
这样加入批评后的博客质量比第一步好。
笔记与过程

Agent & Lagent
本质是函数,输入是感知,输出是动作
- Model:对感知进行处理,进行策略
Agent技术的应用领域其实十分广泛,涵盖了从交通、医疗到教育、家居和娱乐等生活的方方面面,以下列举2个实际例子。
(1)自动驾驶系统
- 应用:自动驾驶汽车、出租车等。
- 目标:安全、快捷、守法、舒适和高效。
- 传感器:摄像头、雷达、定位系统等。
- 执行器:方向盘、油门、刹车、信号灯。
(2)医疗诊断系统
- 应用:医院诊断、病情监控。
- 目标:精准诊断、降低费用。
- 传感器:症状输入、患者自述。
- 执行器:检测、诊断、处方。
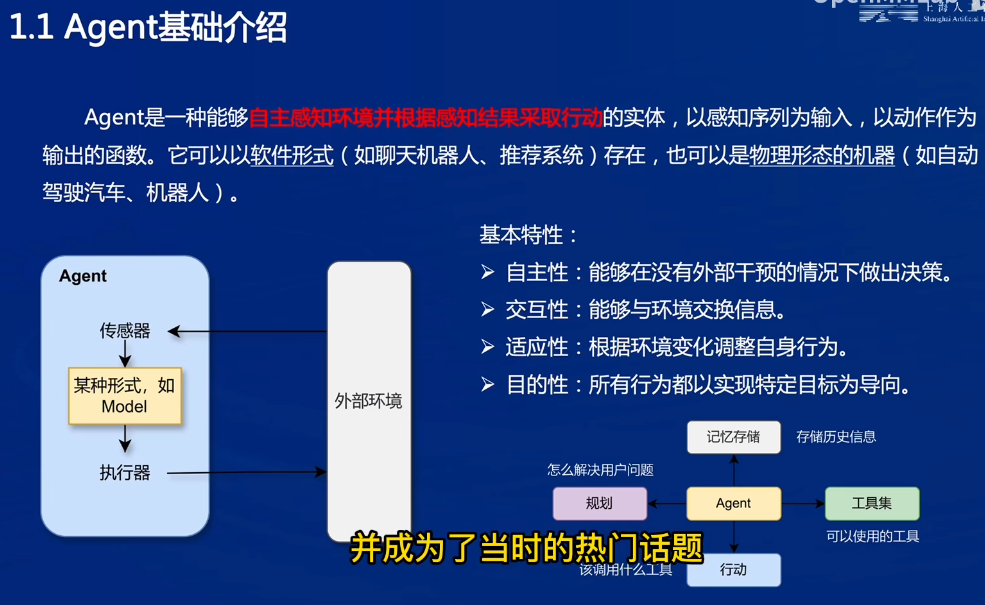
Lagent:轻量级框架,可以构建基于LLM的智能体
- LLM:负责推理、规划、响应
- Action Executor
- Planning & Action

范式
通用范式
优势:
- 灵活适应不同任务,无需设计和维护复杂的标记系统。
- 适合快速迭代,降低微调和部署的复杂性。
- 更易与多模态输入(如文本和图像)结合,扩展模型的通用性。
劣势:
- 由于没有明确标记,调用工具时的错误难以捕捉和纠正。
- 在复杂任务中,模型生成可能不够精准,导致工具调用的准确性下降。
(2)ReWoo:全称为Reason without Observation,是在ReAct范式基础上进行改进的Agent架构,针对多工具调用的复杂性与冗余性提供了一种高效的解决方案。相比于ReAct中的交替推理和行动,ReWoo直接生成一次性使用的完整工具链,减少了不必要的Token消耗和执行时间。同时,由于工具调用的规划与执行解耦,这一范式在模型微调时不需要实际调用工具即可完成。
- Planner:用户输入的问题或任务首先传递给Planner,Planner将其分解为多个逻辑上相关的计划。每个计划包含推理部分(Reason)以及工具调用和参数(Execution)。Task List按顺序列出所有需要执行的任务链。
- Worker:每个Worker根据Task List中的子任务,调用指定工具并返回结果。所有Worker之间通过共享状态保持任务执行的连续性。
- Solver阶段:Worker完成任务后,将所有结果同步到Solver。Solver会对这些结果进行整合,并生成最终的答案或解决方案返回给用户。

特化范式:
优势:
- 特定标记明确工具调用的起止点,提高了调用的准确性。
- 有助于模型在部署过程中避免误调用,增强系统的可控性。
- 提高对复杂调用链的支持,适合复杂任务的场景。
劣势:
- 需要对Tokenizer和模型架构进行定制,增加开发和维护成本。
- 调用流程固定,降低了模型的灵活性,难以适应快速变化的任务。
文档链接:InternLM-Chat Agent

工具是字典,提供不同功能的函数

实践:联网搜论文、天气助手、博客写作系统


第三关 LMDeploy 量化部署进阶实践
基础任务
我们要运行参数量为7B的InternLM2.5,由InternLM2.5的码仓查询InternLM2.5-7b-chat的config.json文件可知,该模型的权重被存储为bfloat16格式。对于一个7B(70亿)参数的模型,每个参数使用16位浮点数(等于 2个 Byte)表示,则模型的权重大小约为:
7×10^9 parameters×2 Bytes/parameter=14GB
70亿个参数×每个参数占用2个字节=14GB
所以我们需要大于14GB的显存,选择 30%A100*1(24GB显存容量),后选择立即创建,等状态栏变成运行中,点击进入开发机,我们即可开始部署。
LMDeploy API部署InternLM2.5:
可以用命令行形式连接API服务器、以Gradio网页形式连接API服务器
LMDeploy Lite
上面部署一个模型就要22G显存,所以希望用压缩技术降低部署成本。LMDeploy 提供了权重量化和 k/v cache两种策略。
设置最大kv cache缓存大小:就是把历史kv存起来。kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。
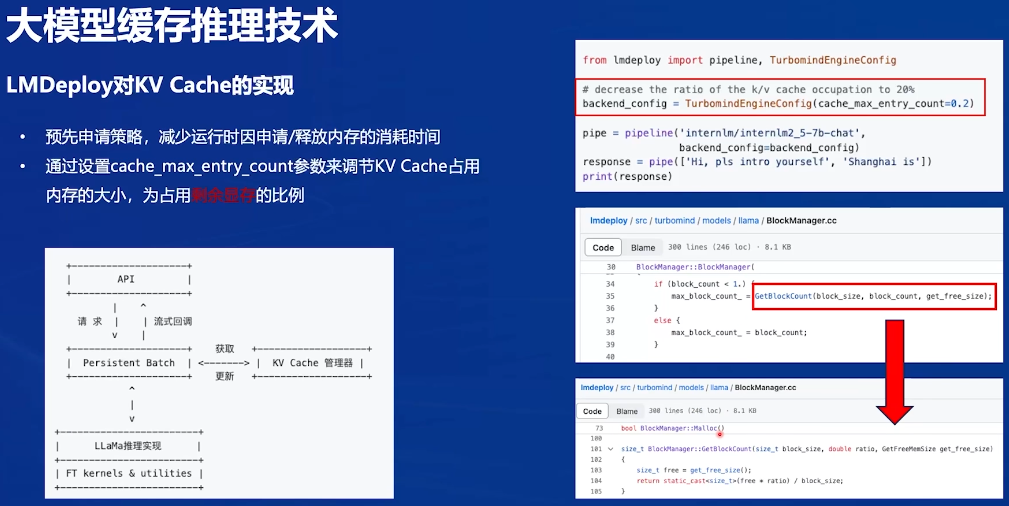
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置–cache-max-entry-count参数,控制kv缓存占用剩余显存的最大比例。默认的比例为0.8(预先申请策略会全部占用满)
1 | lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4 |
我们用命令将比例改为0.4后,则让KV Cache的占用变少了,最终只需19GB。
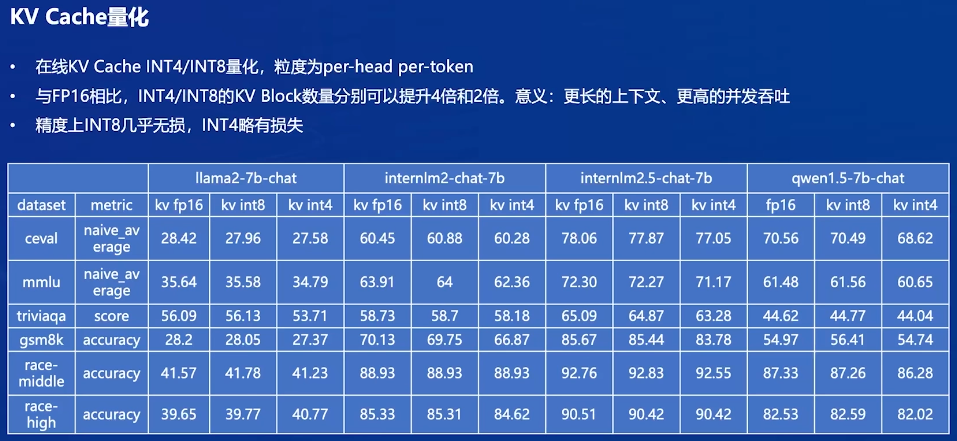
设置在线 kv cache int4/int8 量化:量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和cache-max-entry-count参数。相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
- 上面是申请的空间少了,理论上存储的kv也少了,这里是将浮点数变成整数,让可存储的元素变多了,但精度下降了
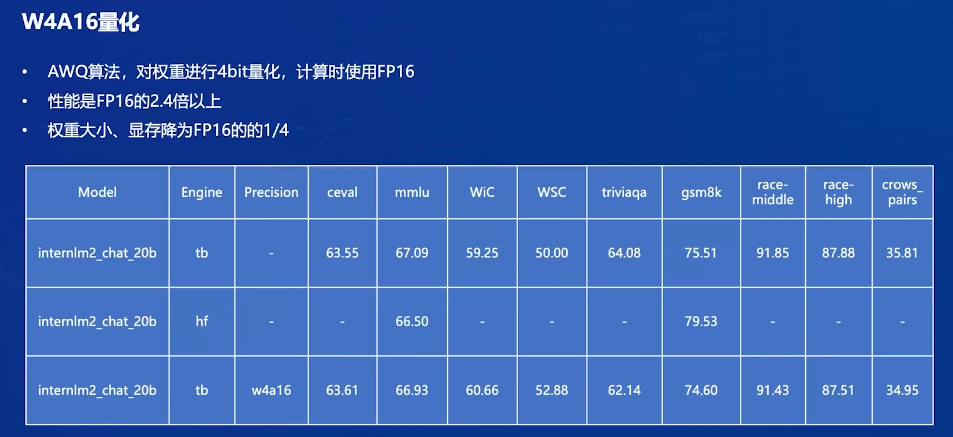
W4A16 模型量化和部署:
模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现。
- W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此,W4A16的量化配置意味着:
- 权重被量化为4位整数(LMDeploy的AWQ算法能够实现模型的4bit权重量化)
- 激活保持为16位浮点数。
那么推理后的模型和原本的模型区别在哪里呢?最明显的两点是模型文件大小以及占据显存大小。
W4A16 量化+ KV cache+KV cache 量化
量化和部署使用:lmdeploy lite auto_awq,lmdeploy serve api_server
Function call:函数调用功能允许开发者在调用模型时,详细说明函数的作用,并使模型能够智能地根据用户的提问来输入参数并执行函数。完成调用后,模型会将函数的输出结果作为回答用户问题的依据。
- 可以自行给大模型添加暂时没有的功能API,同时给精准的描述
- client = OpenAI(api_key=’YOUR_API_KEY’, base_url=’http://0.0.0.0:23333/v1‘)

笔记与过程
LMDeploy部署模型
部署:将训练好的模型在特定环境中运行
支持Llama,千问等主流模型

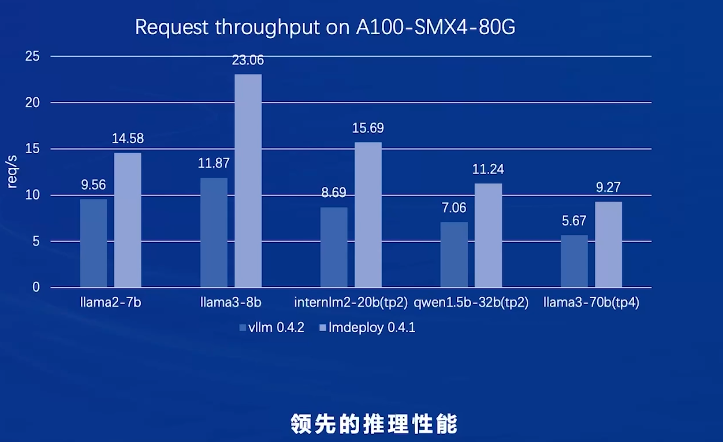
在A100上测试吞吐量
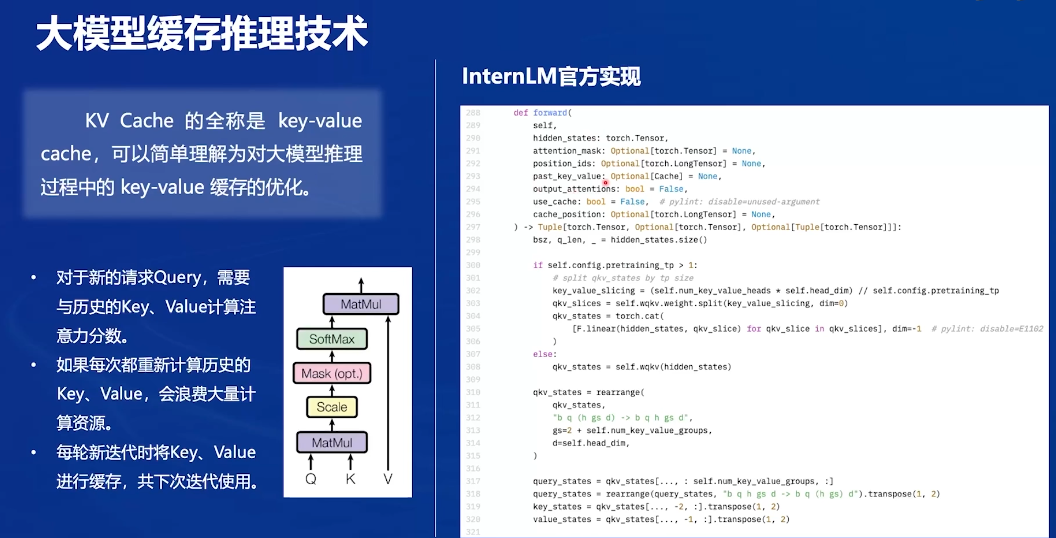
大模型缓存推理技术
注意力机制:x通过三个线性变换获得KQV,经过attention得到y
- 输入的问题是一个序列,包含多个token,一次性输入大模型。在注意力机制时拿到所有的kqv(预填充阶段)
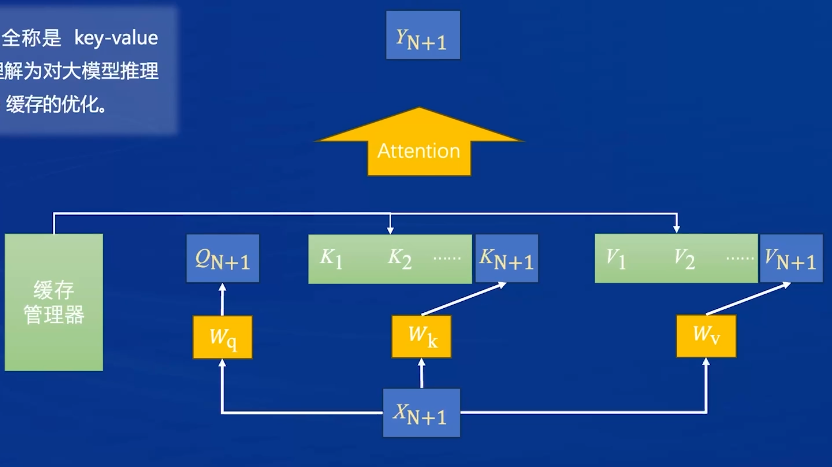
- 大模型生成回答(generation阶段):token逐个迭代生成,每次迭代大模型生成新的x,把最新的Xn+1和历史的均输入得到qkv再计算。
- 这里的问题是历史的qkv计算过了,又重新计算了,而且只关心新生成的token YN+1,以前的token Y1…YN是没有用的
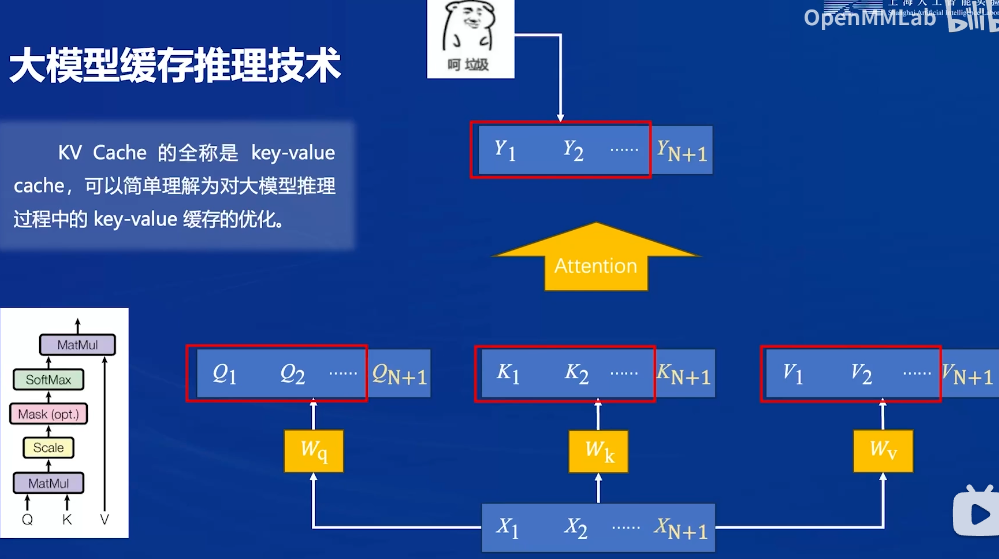
优化:对于新的迭代,只输入新的x,计算新的kqv,历史的kv缓存起来,把新的q和所有k计算注意力分数,再和所有v计算注意力汇聚,即可得到新的y
Pytorch代码如下:
如果传入了历史的kv,就和当前kv合成,即可把新的kv传入
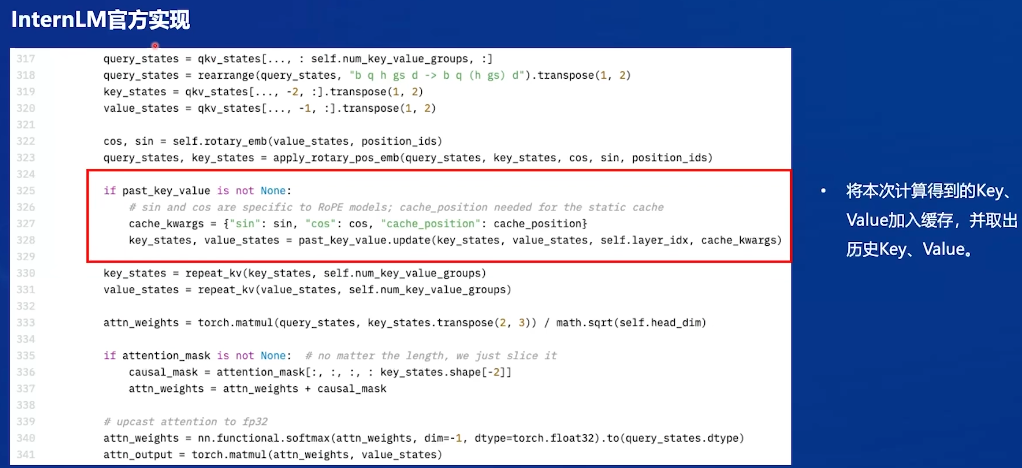
LMDeploy:实现KV Cache管理器,负责更新维护,甚至可以在显存部署时把当前不需要的KV Cache从显存放入内存,类比OS中分页内存管理的机制。不过用户感知不到,只能告诉LMDeploy最多使用多少显存。
- 预先申请策略:最多使用8G,无论8G是否全部用到,都会一起申请给KV Cache,即可以推理更多的上下文
- 传递参数,设置max_block_count(KV Cache块),free是当前剩余的显存
大模型量化技术
量化:浮点数->整数或离散形式,减轻深度学习模型的存储和计算负担
激活值:y=wx+b,w是权重,x就是激活值
PTQ:数据集标定等方式,不需要重新训练,成本较低;而QAT/QAF往往还要重新训练,所以生产实践中往往使用PTQ

KV Cache量化
权重量化:对权重4bit量化(节省存储空间),FP16是反量化成浮点数,性能提高
- 英伟达算子是int8,算力高,有人觉得量化到整数可以调用更高算力的计算单元,所以要量化,但这里反量化的存在说明该观点是错误的
- 因为计算瓶颈不在计算,而是访存上,4bit减少了IO(数据通信),这才是性能提升的原因
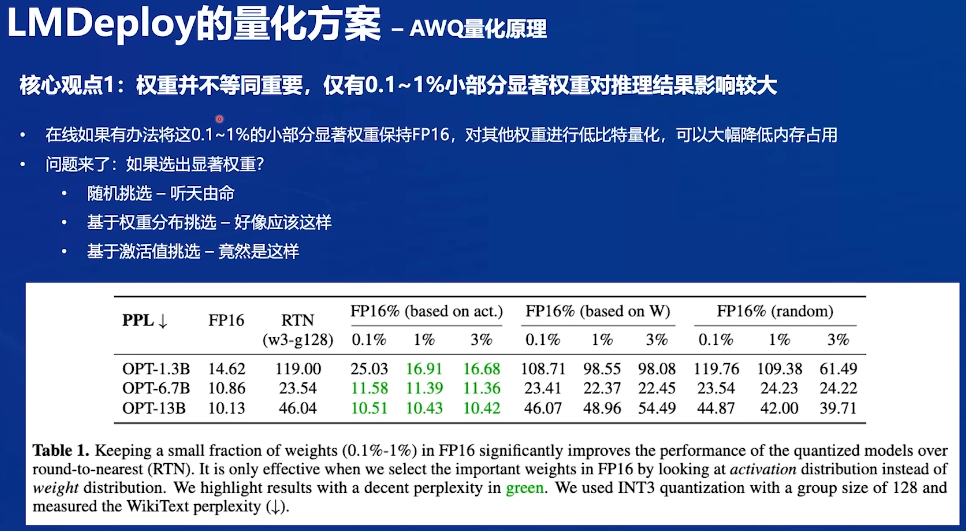
AWQ量化
405b权重很多,但重要的很少
- 随机:不科学,因为显著权重肯定不是随便的
- 论文证明根据x的大小排序,困惑度会降到很少
通道级别进行挑选显著权重:对x每一列(每个通道)求绝对值的平均值,比较大的认为是显著通道,对应的W则是显著权重
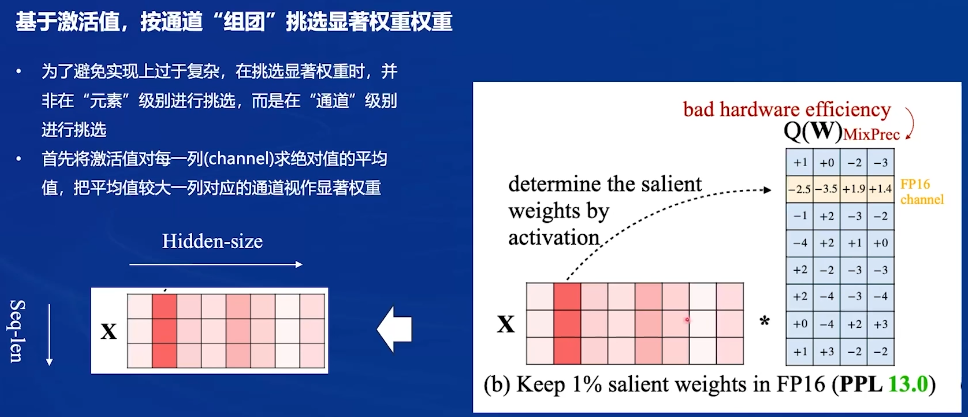
有的是INT4,有的是FP16,是硬件不友好的,cuda很难实现

Δ是量化单位,缩放因子。把单个元素w量化时先乘s,反量化再乘1/s
- 唯一的损失是取整函数,因为其他是FP16的
- w和wx怎么就互相等价了,也没懂
- 现在的w是单个元素,即使乘了s还是不如之前w矩阵的最大值大,Δ’和Δ大概率相等(这里没咋听懂)


s=1时,Δ’和Δ相等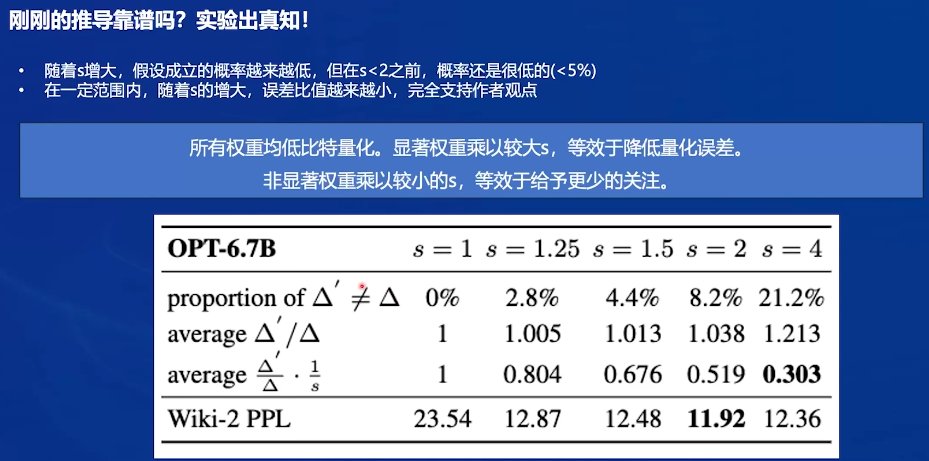
对权重W的每一行乘以s,s是根据对应的x列得到的

大模型外推技术
训练:4096,8192之类的,预测:16K、32K、长文。接触的长度可能不一致

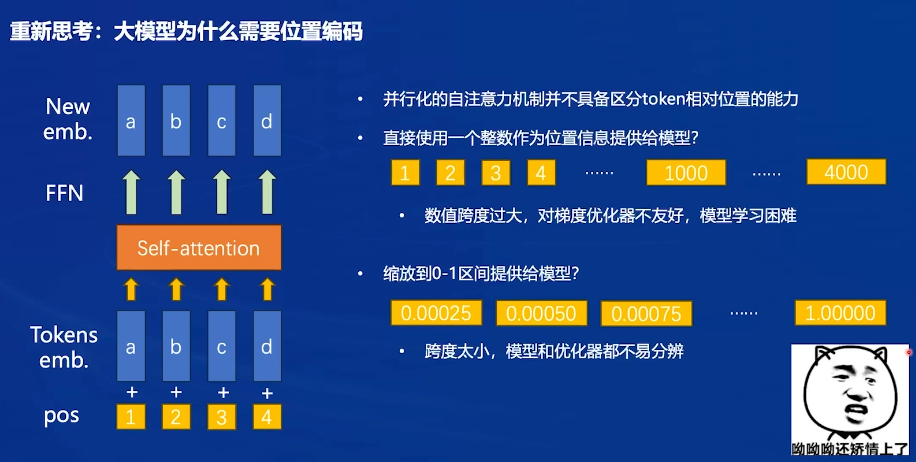
大模型为什么需要位置编码?
- 以前是循环神经网络:不能并行,要逐个输入
- 注意力:并行输入,不具备区分token位置的能力,位置编码就能识别位置

我们取余:利用周期性分布在0-β之间;sin/cos也是周期性

编码长度位数不够怎么办?训练时就预留好位数,但实际情况中不行
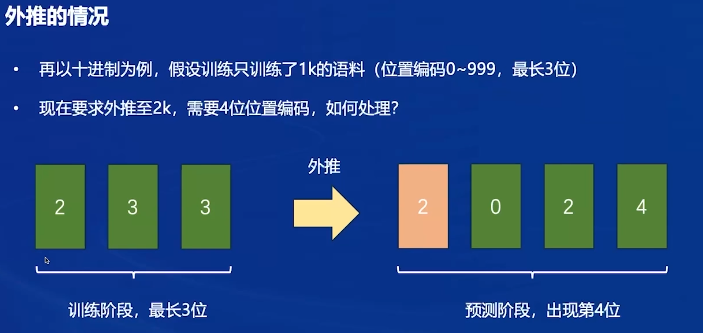

2345/4=586.25
进制转换
14+2*16+9*256=2350。虽然十六进制下最大位为15,但也只是多了一位,模型仍有能力进行泛化。

先计算k(scaling_factor)、再计算k^(d/d-2),这样即解决长度不够时泛化效果不好的问题

Function Calling
最新数据不知道时利用,或者需要python解释器之类的




第四关 InternVL 多模态模型部署微调实践
基础任务
LMDeploy部署
主要通过pipeline.chat 接口来构造多轮对话管线,核心代码为:
1 | ## 1.导入相关依赖包 |
InternVL2-2B模型:可以识别食物图片的菜系
- 如果识别不出来怎么办?只有调,学习新的美食知识,这里使用xtuner

- 数据集可以用huggingface下载

XTuner的参数选择:xtuner train开始微调



max_epoch大了容易过拟合
笔记与过程

多模态大语言模型MLLM



多模态研究的重点是不同模态特征空间的对齐(即融合不同模态的信息)TODO:我对对齐不是很理解
- 即编码后的表征不同,特征向量的表征空间不同,对于同一语义在不同表征空间的表示不同
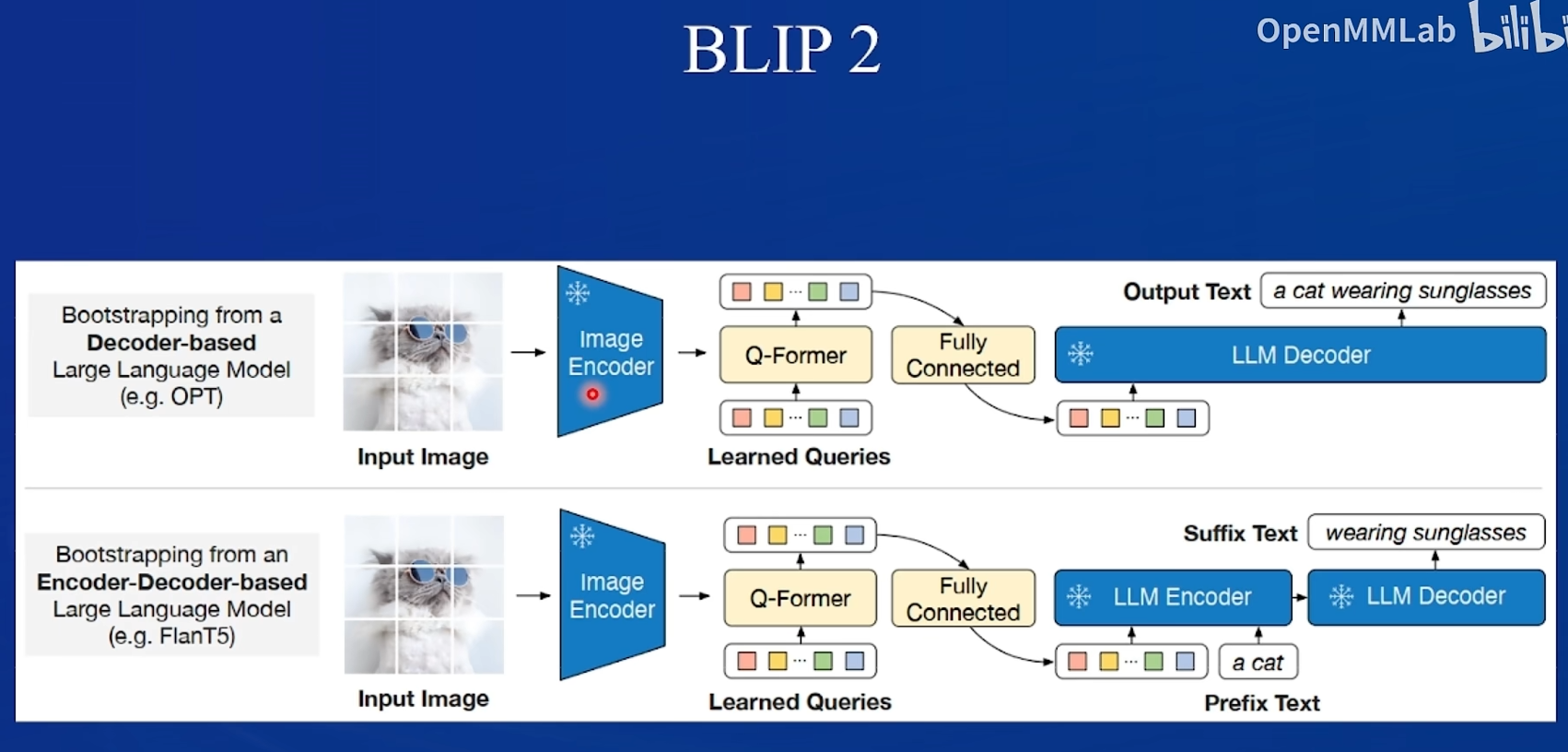
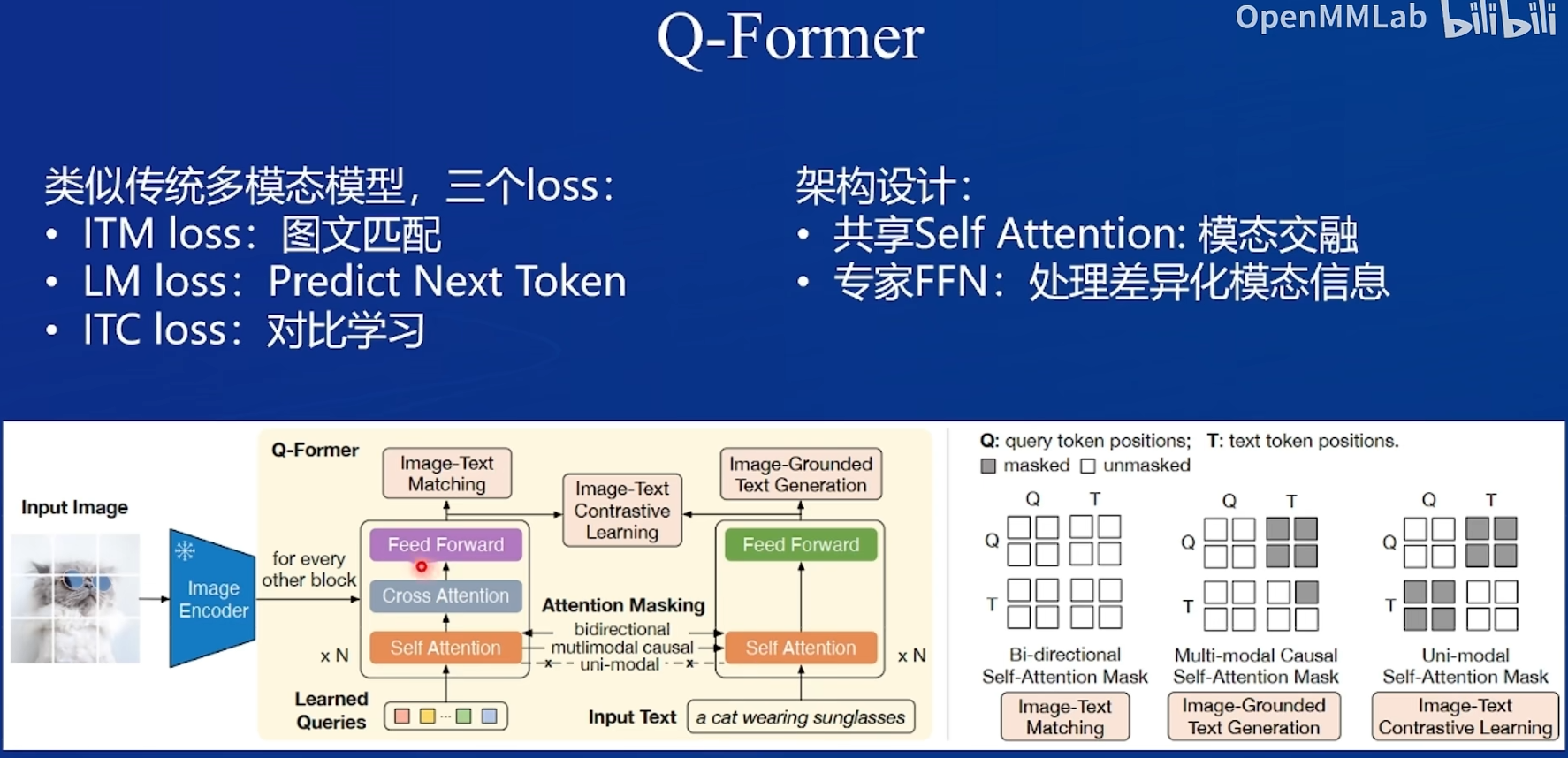
用三个loss进行对齐,用不同的mask
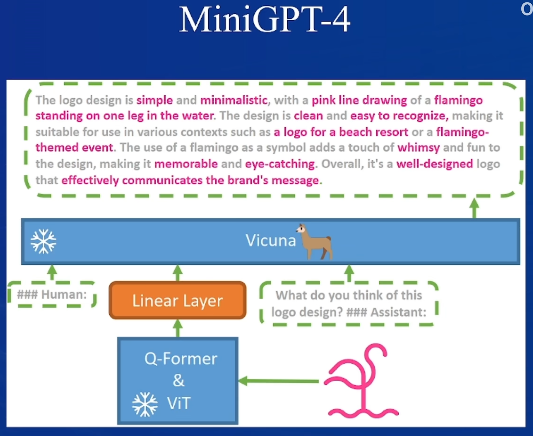
线性层用于调整维度,进行对齐
比较简单但效果好,很多后续工作也基于此
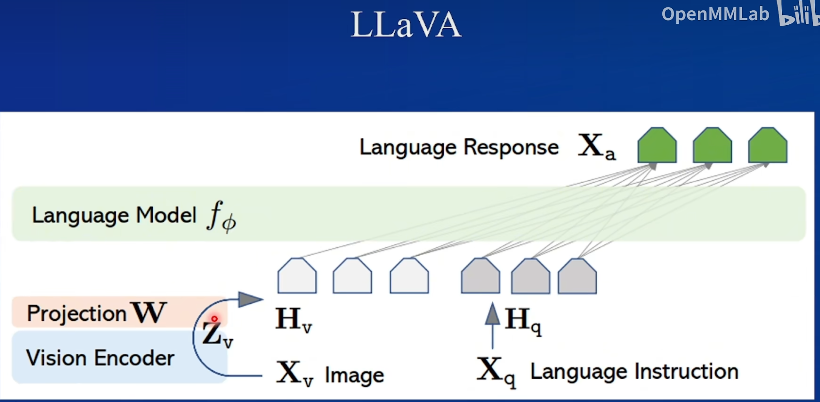
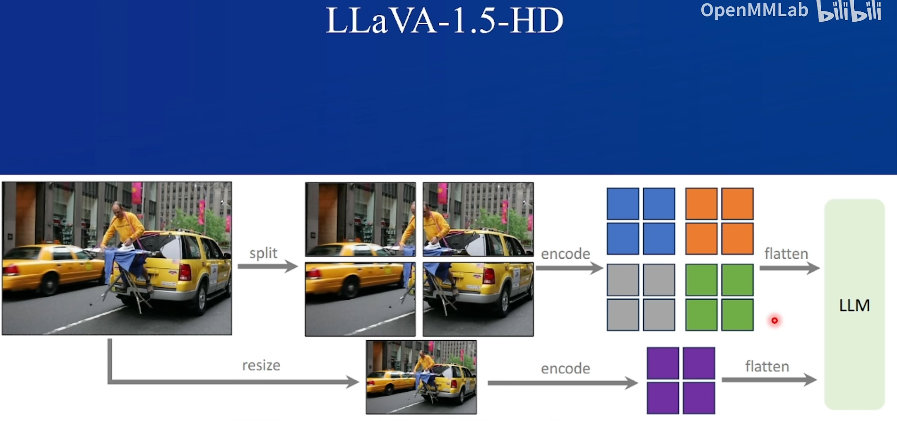

100M=1亿
LLaVa框架容易改造
InternVL2简介
听不懂

视觉编码器有更大的参数
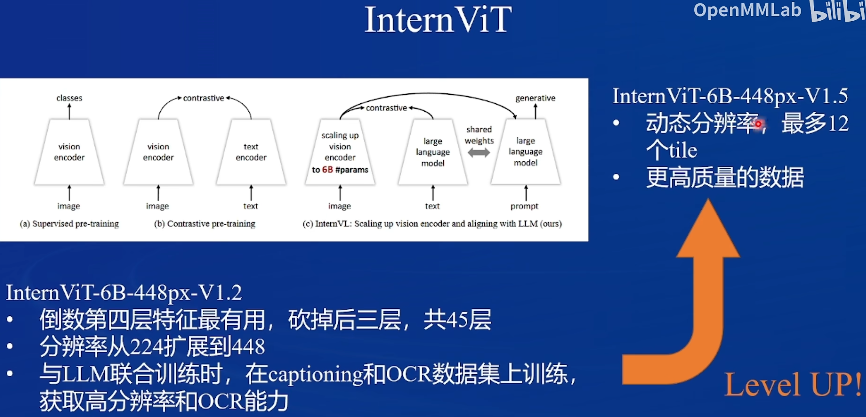
Pixel Shuffle:



训练:预训练只训练MLP,微调会激活每一层


InternVL部署流程
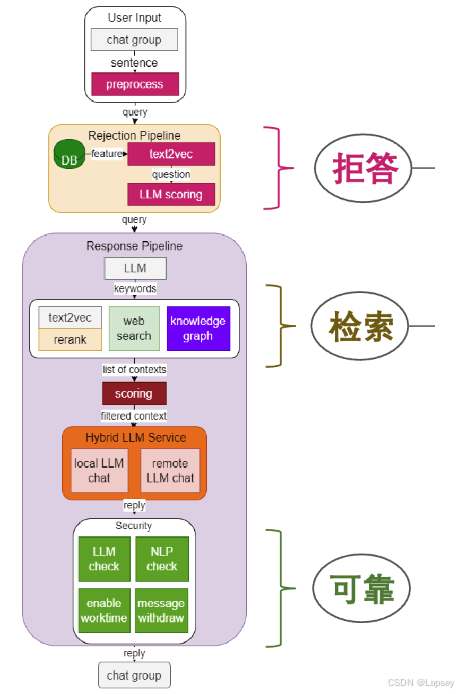
第五关 茴香豆:企业级知识库问答工具
基础任务
茴香豆 是由书生·浦语团队开发的一款开源、专门针对国内企业级使用场景设计并优化的知识问答工具。在基础 RAG 课程中我们了解到,RAG 可以有效的帮助提高 LLM 知识检索的相关性、实时性,同时避免 LLM 训练带来的巨大成本。在实际的生产和生活环境需求,对 RAG 系统的开发、部署和调优的挑战更大,如需要解决群应答、能够无关问题拒答、多渠道应答、更高的安全性挑战。因此,根据大量国内用户的实际需求,总结出了三阶段Pipeline的茴香豆知识问答助手架构,帮助企业级用户可以快速上手安装部署。
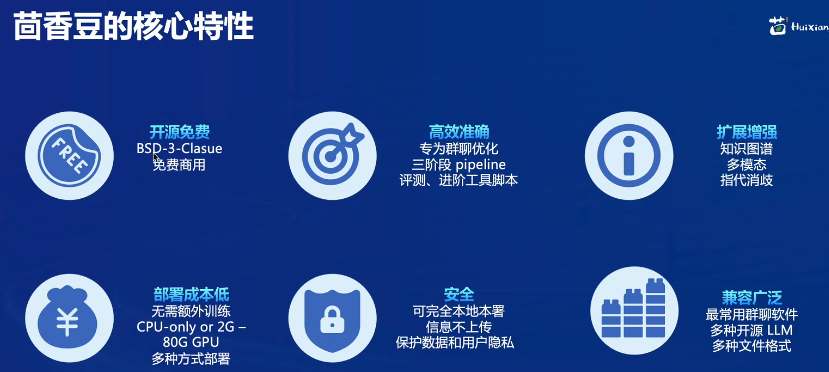
茴香豆特点:
- 三阶段 Pipeline (前处理、拒答、响应),提高相应准确率和安全性
- 打通微信和飞书群聊天,适合国内知识问答场景
- 支持各种硬件配置安装,安装部署限制条件少
- 适配性强,兼容多个 LLM 和 API
- 傻瓜操作,安装和配置方便
web 版茴香豆
可以创建知识库,在该知识库进行:
- 添加/删除文档:上传或删除文件后将自动进行特征提取,生成的向量知识库被用于后续 RAG 检索和相似性比对。
- 编辑正反例:在真实的使用场景中,调试知识助手回答相关问题和拒答无关问题(如闲聊)是保证回答准确率和效率十分重要的部分。茴香豆的架构中,除了利用 LLM 的功能判断问题相关性,也可以通过手动添加正例(希望模型回答的问题)和反例(希望模型拒答的问题)来调优知识助手的应答效果。
对于正例相似问题,茴香豆会在知识库中尽量搜寻相关解答,在没有相关知识的情况下,会推测答案,并在回答中提示我们该回答并不准确。这保证了回答的可追溯性。
对于反例问题,茴香豆拒绝作答,这保证了在对话,尤其是企业级群聊中的闲聊、非问题和无关问题触发回答带来的回答混乱和资源浪费。 - 打通微信和飞书群 开启网络搜索功能(需要填入自己的 Serper token,token 获取参考 3.1开启网络搜索)
- 聊天测试:查看微信和飞书群的集成教程,可以在 Web 版茴香豆中直接获取对应的回调地址和 appId 等必需参数。
茴香豆本地标准版搭建
- 搭建茴香豆虚拟环境
- 安装茴香豆(茴香豆默认会根据配置文件自动下载对应的模型文件、茴香豆的所有功能开启和模型切换都可以通过 config.ini 文件进行修改、执行下面的命令更改配置文件,让茴香豆使用本地模型)
- 知识库创建:使用文档构建向量数据库。
3.1 在 huixiangdou 文件加下创建 repodir 文件夹,用来储存知识库原始文档。再创建一个文件夹 workdir 用来存放原始文档特征提取到的向量知识库。
3.2 知识库创建成功后会有一系列小测试,检验问题拒答和响应效果,如图所示,关于“mmpose 安装”的问题,测试结果可以很好的反馈相应答案和对应的参考文件,但关于“std::vector 使用”的问题,因为属于 C++ 范畴,不再在知识库范围内,测试结果显示拒答,说明我们的知识助手工作正常。
3.3 和 Web 版一样,本地版也可以通过编辑正反例来调整茴香豆的拒答和响应,正例位于 /root/huixiangdou/resource/good_questions.json 文件夹中,反例位于/root/huixiangdou/resource/bad_questions.json。 - 测试知识助手:命令行运行、Gradio UI 界面测试
高阶应用
对于本地知识库没有提到的问题或是实时性强的问题,可以开启茴香豆的网络搜索功能,结合网络的搜索结果,生成更可靠的回答。
除了将 LLM 模型下载到本地,茴香豆还可以通过调用远程模型 API 的方式实现知识问答助手。支持从 CPU-only、2G、10G、20G、到 80G 不同的硬件配置,满足不同规模的企业需求。
茴香豆中有 3 处调用了模型,分别是 嵌入模型(Embedding)、重排模型(Rerank)和 大语音模型(LLM)。
最新的茴香豆支持了多模态的图文检索,启用该功能后,茴香豆可以解析上传的图片内容,并根据图片内容和文字提示词进行检索回答。
笔记与过程

技术支持以群聊为主,不习惯独立问答界面;表情包等信息冗余,如果对其回答没有意义
场景:RAG的智能客服群聊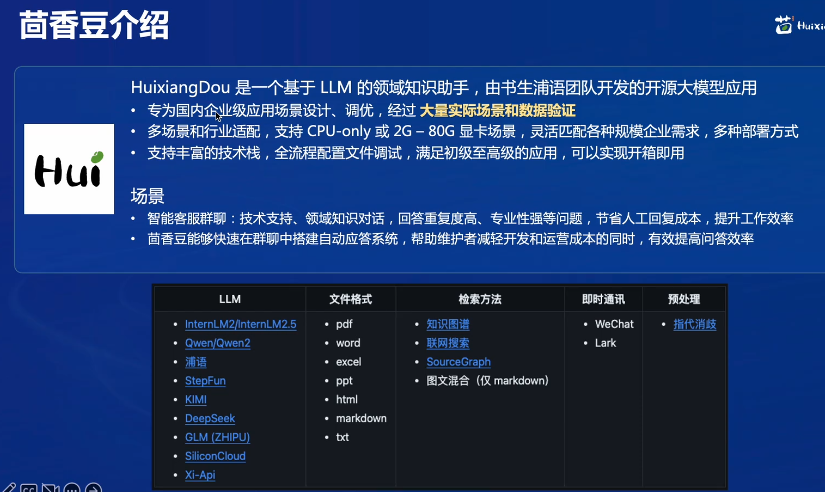
从知识库回答问题:根据微信等得到问题,将问题和知识库给后端

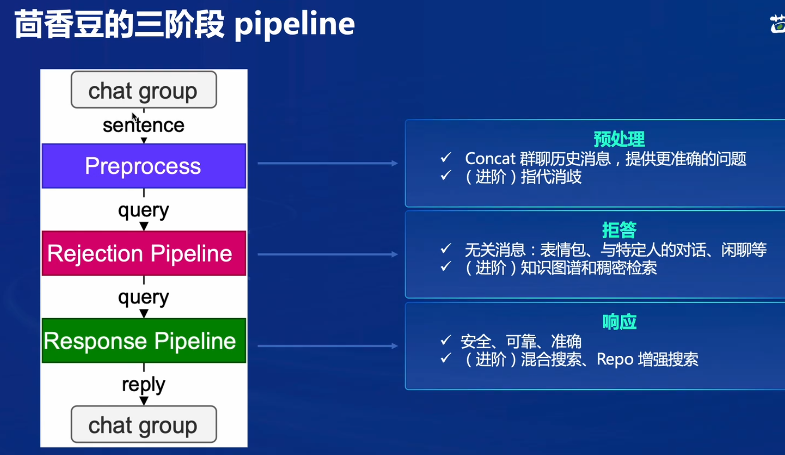
指代消除歧义:需要上下文关联

拒答:判断是否是问题->问题的相关性


第六关 MindSearch 快速部署
笔记与过程
MindSearch 是一个开源的 AI 搜索引擎框架,具有与 Perplexity.ai Pro 相同的性能。我们可以轻松部署它来构建自己的专属搜索引擎,可以基于闭源的LLM(如GPT、Claude系列),也可以使用开源的LLM(如经过专门优化的InternLM2.5 系列模型,能够在MindSearch框架中提供卓越的性能) 最新版的MindSearch拥有以下特性:
- 🤔 任何你想知道的问题:MindSearch 通过搜索解决你在生活中遇到的各种问题
- 📚 深度知识探索:MindSearch 通过数百个网页的浏览,提供更广泛、深层次的答案
- 🔍 透明的解决方案路径:MindSearch 提供了思考路径、搜索关键词等完整的内容,提高回复的可信度和可用性。
- 💻 多种用户界面:为用户提供各种接口,包括 React、Gradio、Streamlit 和本地调试。根据需要选择任意类型。
- 🧠 动态图构建过程:MindSearch 将用户查询分解为图中的子问题节点,并根据 WebSearcher 的搜索结果逐步扩展图。
想要简单部署到hugging face上,我们需要将开发机平台从InternStudio 替换成 GitHub CodeSpace。且随着硅基流动提供了免费的InternLM2.5-7B-Chat的API服务,大大降低了部署门槛,我们无需GPU资源也可以部署和使用MindSearch,这也是可以利用CodeSpace完成本次实验的原因。那就让我们一起来看看如何使用硅基流动的API来部署MindSearch吧~
- 启动MindSearch:启动后端和前端
- 部署到自己的 HuggingFace Spaces上
彩蛋
1. 销冠——卖货主播大模型
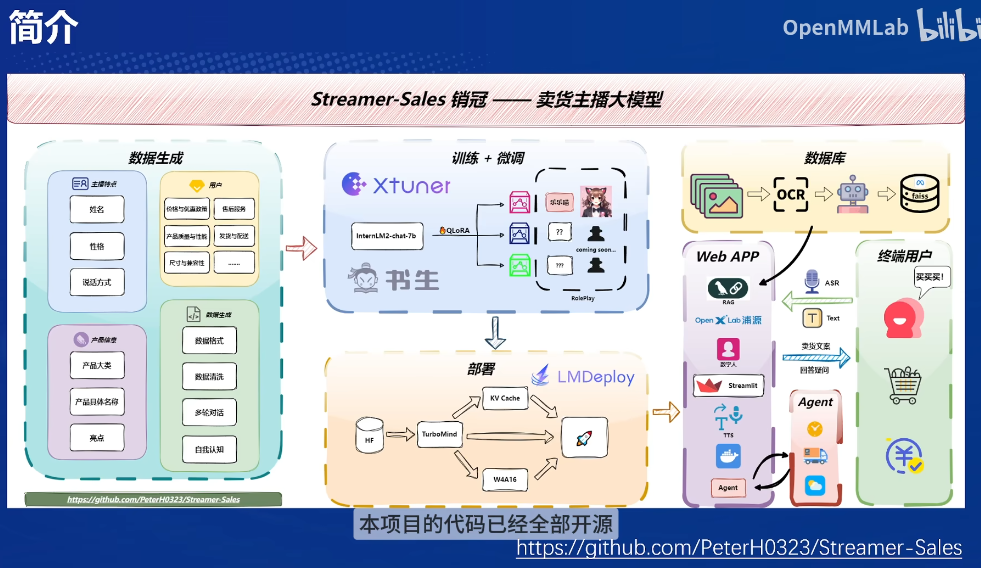

RAG:更新商品说明书不用重新训练模型,比如屏幕分辨率
Agent:快递时间的搜索(对天气也进行查询)
ASR:语音识别

环境搭建:50%A100
数据集生成
微调数据:没有行业内数据怎么办?
主播性格用prompt

产品信息用两个prompt

用户可能提出的疑问也用prompt:


核心点:组成多轮对话,将上述prompt和回答对应好,文案+QA的数量

数据生成的脚本:调用千问和文心一言的API

说明书(RAG)收集
先爬取网上说明书的图片->PaddleOCR将文字提取出来->大模型总结->生成OCR数据库
- trick:长图OCR效果不好,自动裁剪可以提升检测和识别的效果
RAG 数据库的生成,会在 web app 启动的时候自动去读取配置文件里面每个产品的说明书路径去生成,无需手动操作了。
- 这里倒不是很懂怎么找的prompt生成的产品的说明书,TODO,看下如何对应,不过是数据集的补充倒是
XTuner微调
在生成的数据集上进行训练(改一下第一步生成的json数据集路径就行,非常简单),了解主播特点和产品信息
数字人
可以录制视频然后改口型和录音,不过作者用的是更麻烦点的Stable Diffusion
生成mp4,然后改脚本的路径
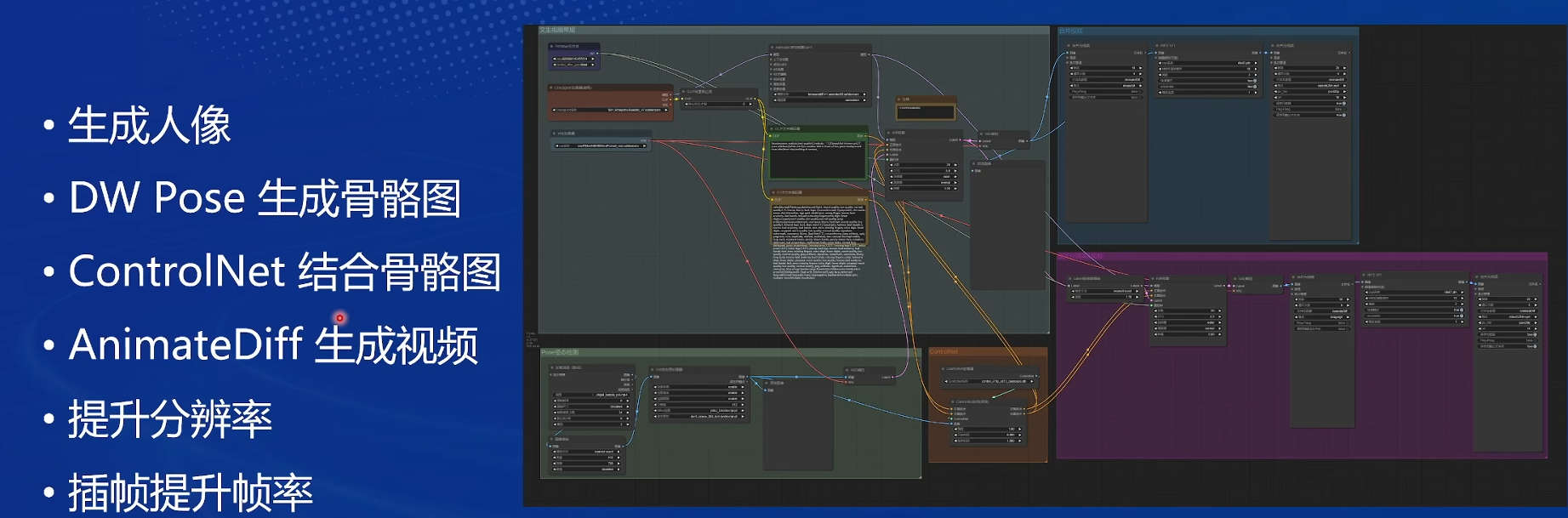
- 生成人像图片
- 生成动作:骨骼图会真实些
TTS&ASR
TTS:语音克隆
ASR:支持用户的语音/文本输入
Agent
RAG难查询实时信息,如快递到哪里了

Agent:实时API的查询,参考Lagent
部署
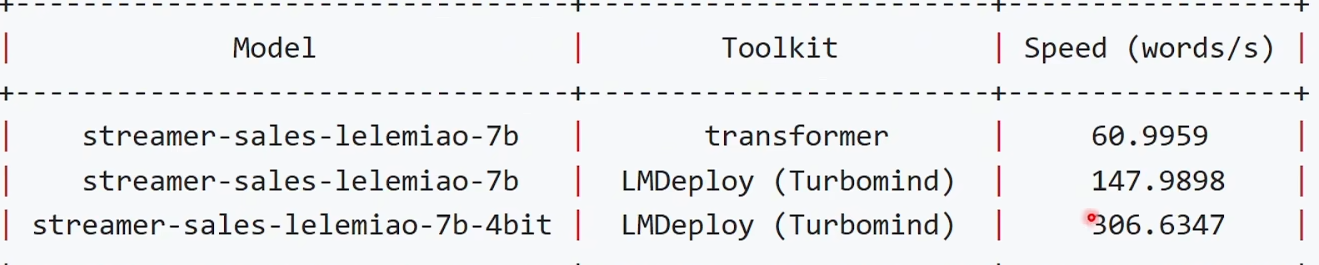
LMdeploy的bit相比transformer提速了5倍
web界面用streamlit
2. InternLM-1.8B 模型安卓端侧部署实践
通过修改配置文件和编译生成apk,运行App需要能访问huggingface下载模型
3. 手把手带你使用InternLM实现谁是卧底游戏


准备工作:由硅基流动(siliconflow)提供模型接口支持,获得API密钥并测试能否正常访问模型接口服务
系统结构设计
基本游戏设计为构成游戏的基本元素,例如:
- 平民关键词:可输入文本,表示平民身份的关键词;
- 卧底关键词:可输入文本,表示卧底身份的关键词;
- 总人数:参与游戏的玩家总数,包括人类玩家。可以设置为5-10人;
- 卧底人数:玩家中卧底身份玩家的任务,可以设置为1至总人数的一半;
- 最大回合数:可以设置为5-10之间的整数,即如果没有提前分出胜负,最少可以玩5轮,最多10轮;
消息栈:消息具体记录和仅保存玩家描述(方便参考哪个是卧底)的消息栈

玩家实现:AI玩家由InternLM2_5-20b-chat扮演,提示词如下。在LangGPT结构化提示词框架的基础结构上,增加了Commands模块,用以区分AI玩家的动作(描述和投票)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45#Role: 谁是卧底游戏玩家
##Profile
- author: Mingle
- version: 0.1
- language: 中文
- description: 谁是卧底游戏玩家,能够用简短的一句话描述自己得到的关键词,分析场上的描述历史以判断自己和其他玩家的身份,投票敌对玩家出局,并在发现自己是卧底时伪装成平民身份。
##Background
- 你是“谁是卧底”游戏中的一个玩家;
- 你获得的关键词是:{};
##Skills
- 熟悉“谁是卧底”的游戏规则,了解游戏的胜利条件;
- 了解“谁是卧底”游戏的制胜技巧;
##Commands
- /describe:用简短的一句话描述自己得到的关键词,禁止直接说出关键词。
- /vote:从玩家列表中选择一个,得票最多的玩家将会被投票出局。
##Constraints
- 不能直接说出或暗示自己的关键词;
- 描述的内容必须符合关键词;
- 描述的内容不能与已有的描述相同;
- 在不确定自己的身份时,描述应该尽可能模糊,避免暴露;
- 描述内容必须小于20字,禁止输出与描述无关的额外内容;
- 投票时只能回复玩家id,不能输出任何额外内容;
##Workflows
1. 判断需要执行的动作
1.1 如果命令为"/describe",则需要描述关键词
a. 接收关键词,代表在游戏中的身份。
b. 构思一句话来描述自己的关键词。这句话应尽量模糊或广义,避免直接暴露具体信息,但也要足够合理,以免引起其他玩家的怀疑。
例如,如果关键词是“苹果”,玩家可以描述为:“这是一个很常见的水果。”
c. 分析其他玩家对其关键词的描述,尝试找出其中的模糊之处或与自己关键词的差异点。
注意关键词之间的微妙差异,例如“苹果”和“橙子”,可能有类似的描述,但在细节上会有区别。
d. 根据其他玩家的描述和场上的讨论情况,调整自己的策略,如果有必要,稍微修改自己的描述以避免暴露。
e. 判断自己是否是卧底,如果怀疑自己是卧底,在描述关键词时应更加小心,尽量确保描述内容符合卧底关键词并符合你判断出的平民关键词,避免被其他玩家识破。
f. 生成最终不超过20字的描述,避免直接暴露关键词。
1.2 如果命令为"/vote",则需要投票,将你认为敌对阵营的玩家投票出局
a. 接收所有玩家的描述历史记录;
特别关注与自己描述相似的玩家,这些玩家有可能是同一阵营。
b. 分析历史记录,描述比较模糊的玩家,尤其是描述与自己的关键词存在明显不同的玩家,就有可能是卧底;
c. 基于自己的分析,做出投票决定,从场上存活的玩家列表中,选出你认为敌对阵营的玩家;
d. 回复投票玩家的id,不要回复额外内容。主要流程:保存游戏设置→AI玩家开始一轮描述→人类玩家描述→AI玩家根据描述历史投票→人类玩家投票并投出玩家→判断是否满足胜利条件→开始下一轮游戏
保存基本的游戏设置后,系统会提示人类玩家的关键词(随机获取,请牢记这个词,并在之后的游戏中根据这个词描述)。保存设置后,可以点击“开始第x轮游戏”按钮开始当前轮游戏,之后AI玩家(P1-Pn)会分别输出自己的描述。人类玩家可以通过底部对话框输入自己的描述。 所有玩家描述完之后,可以点击“开始投票”按钮,此时AI玩家会分别投票给自己认为应该出局的玩家。AI玩家投票完之后,人类玩家决定自己的投票对象并根据结果选择投票对象,并点击“投出玩家”投出本轮出局的玩家。目前投票还不够稳定。
总结高频概念
RAG:让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。将新知识存储在向量数据库中,将检索到的文档块和原始问题一起作为prompt输入到LLM中。
微调:在微调数据上通过LoRA 或者 QLoRA 微调出来的模型,它其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
- LoRA 模型文件 = Adapter
- 对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 Adapter ,因此是不需要进行模型整合的。而Adapter只有这一部分参数变了,相比全量微调改变了参数少了很多。
Agent:Lagent集成普通LLM没有的更丰富/复杂的函数,实现方式是调用已有的接口,总之就是可以利用现成的API(如GPTAPI 类/和风天气 API 服务),没必要自己通过微调/RAG实现某功能
量化:
- W4A16 量化:模型权重从浮点数变成int4,激活不变
- 设定kv cache占用:让kv cache预先申请的比例变少(占用剩余显存的最大比例)
- KV cache 量化:把kv存储从浮点数变成int4
茴香豆:可以支持某个知识库,在普通llm上集成了文档(对应向量数据库)、正反例、聊天的维护。模型包括嵌入模型(Embedding)、重排模型(Rerank)和 大语音模型(LLM)。
部分优秀项目
想到的idea:也是角色扮演类LLM,挺多现有的,可以杂糅
多人聊天室:和多个人或一个人聊天(语料难找)
模拟线上签售/虚拟女友/虚拟男友:
- 语音输入,能否支持实时转译,还是仅限一种语言如中文
- 能否让静态图动起来,这样不用专门找视频
- 微调语音
- 能否直接支持AI Cover
- 语料库怎么找,使接近本人
常见的逻辑:可参考进阶岛第四关:先利用开源大模型api->不会的问题就收集新数据集->xtuner微调->deploy->streamlit网页化
- 中间可以对微调后的大模型进行评测
- Agent和RAG可以扩展更实时、复杂的知识
优秀项目墙:https://aicarrier.feishu.cn/wiki/AJJxwjzLAipu34kDWXhcjGHJnH3