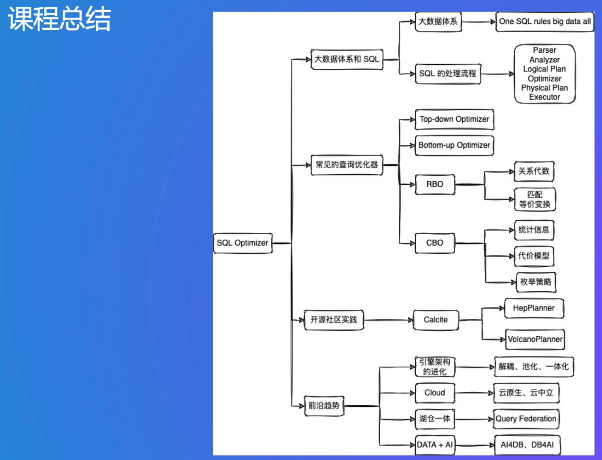
1. SQL Optimizer解析
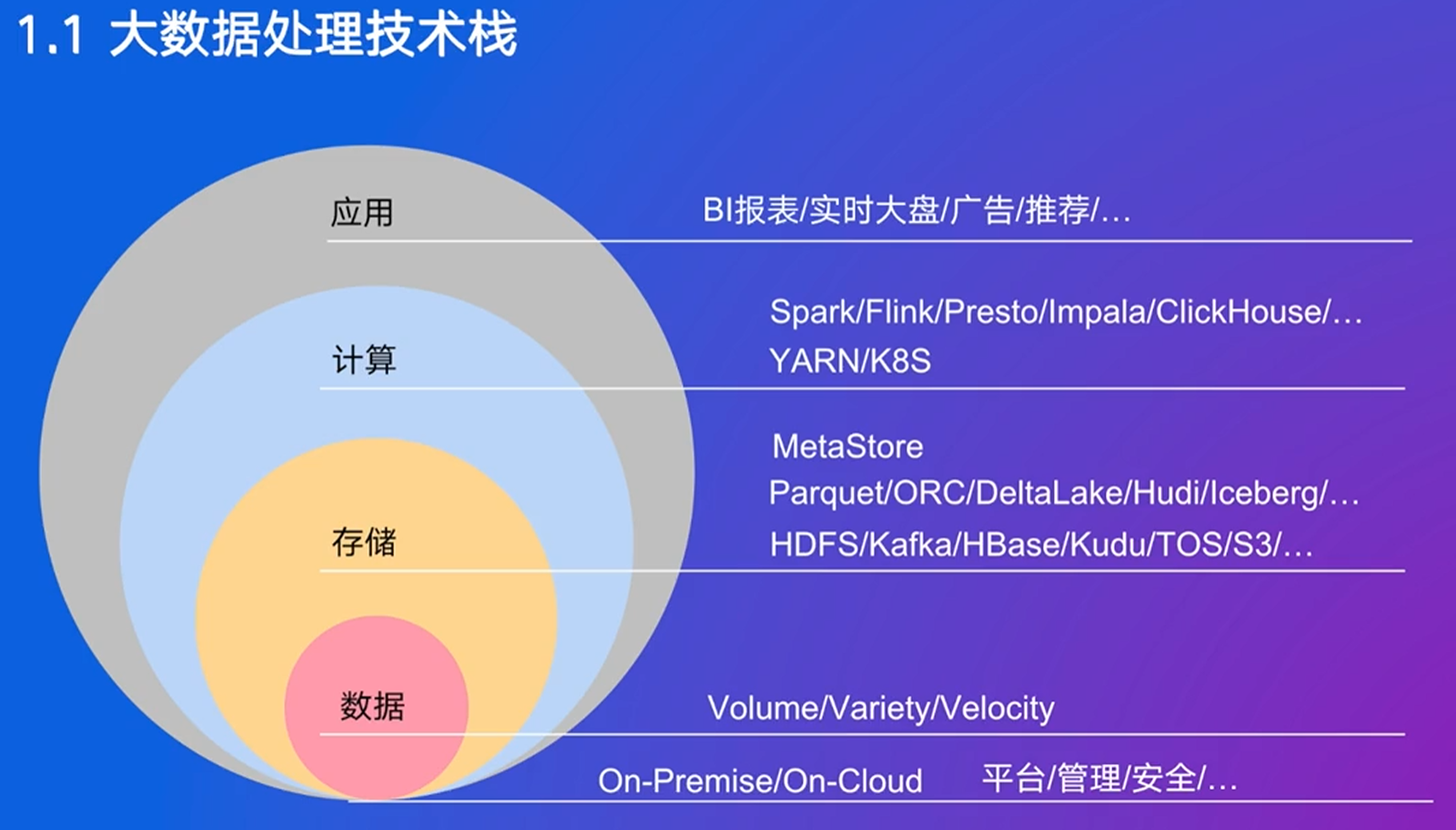
1. 大数据体系介绍与SQL处理流程

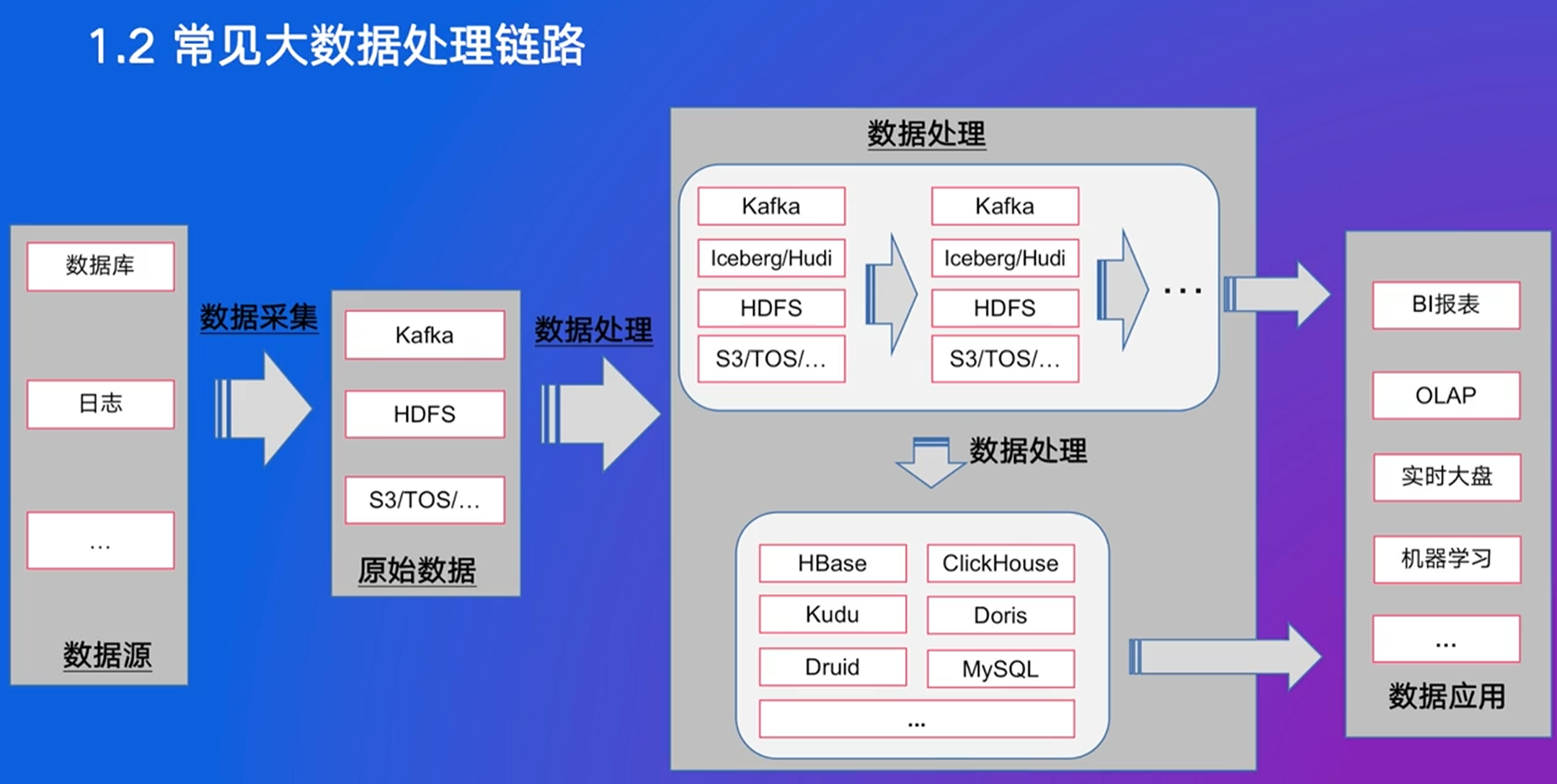
消息队列用来解耦存储和计算
分析引擎都支持SQL,如Spark,MapReduce逐渐开始支持
最终目标是通过SQL处理所有大数据

Parser:词法分析和语法分析已经很成熟了,有很多API,得到AST
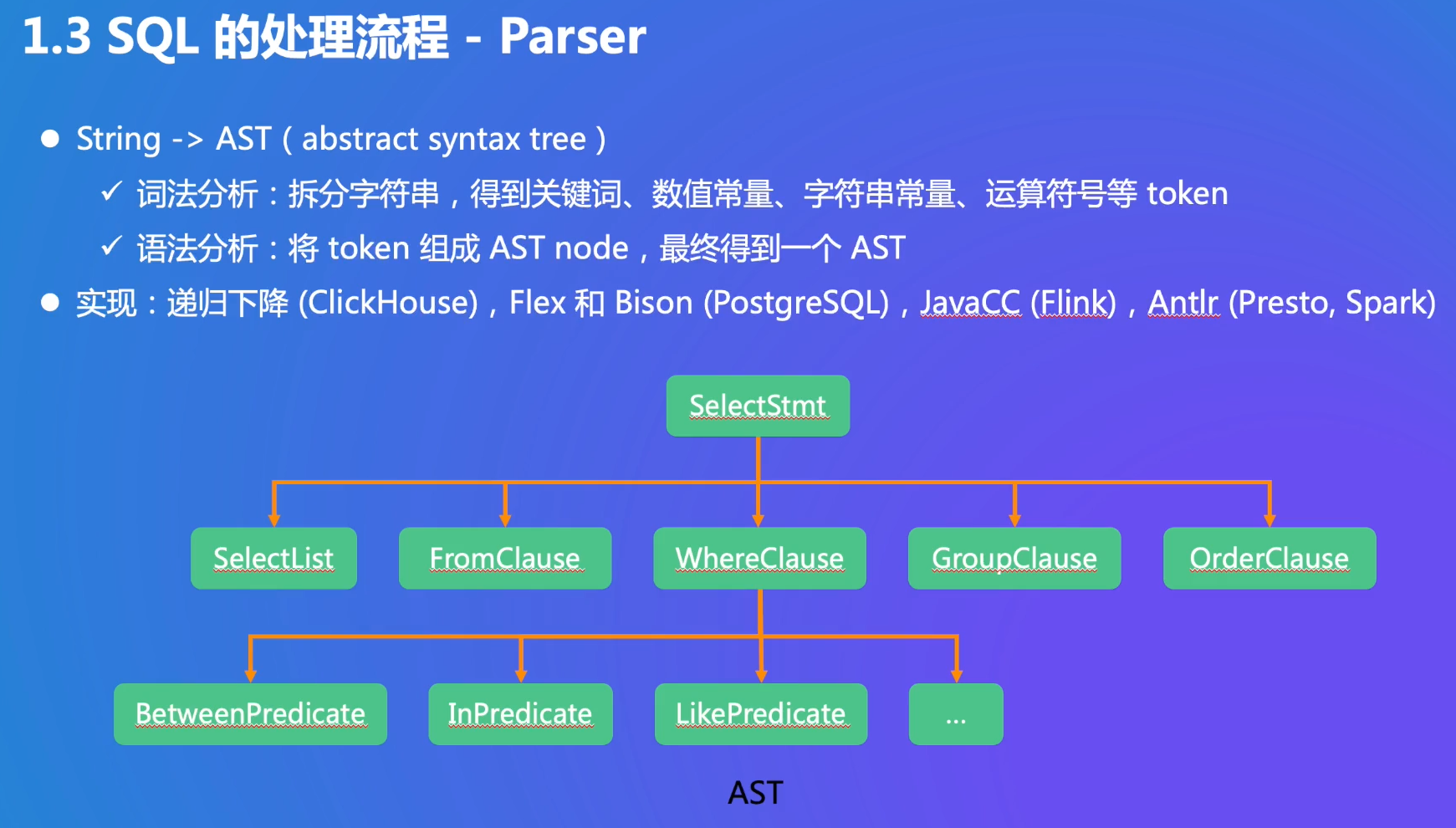
Analyzer:检查合法性,把AST变成Logical Plan
逻辑:只是逻辑,没有指定一定要用哪一种算法
- 三张表连接,一些过滤条件和选择,group by是聚合,top n用堆排序(limit 10)
- left-deep tree:
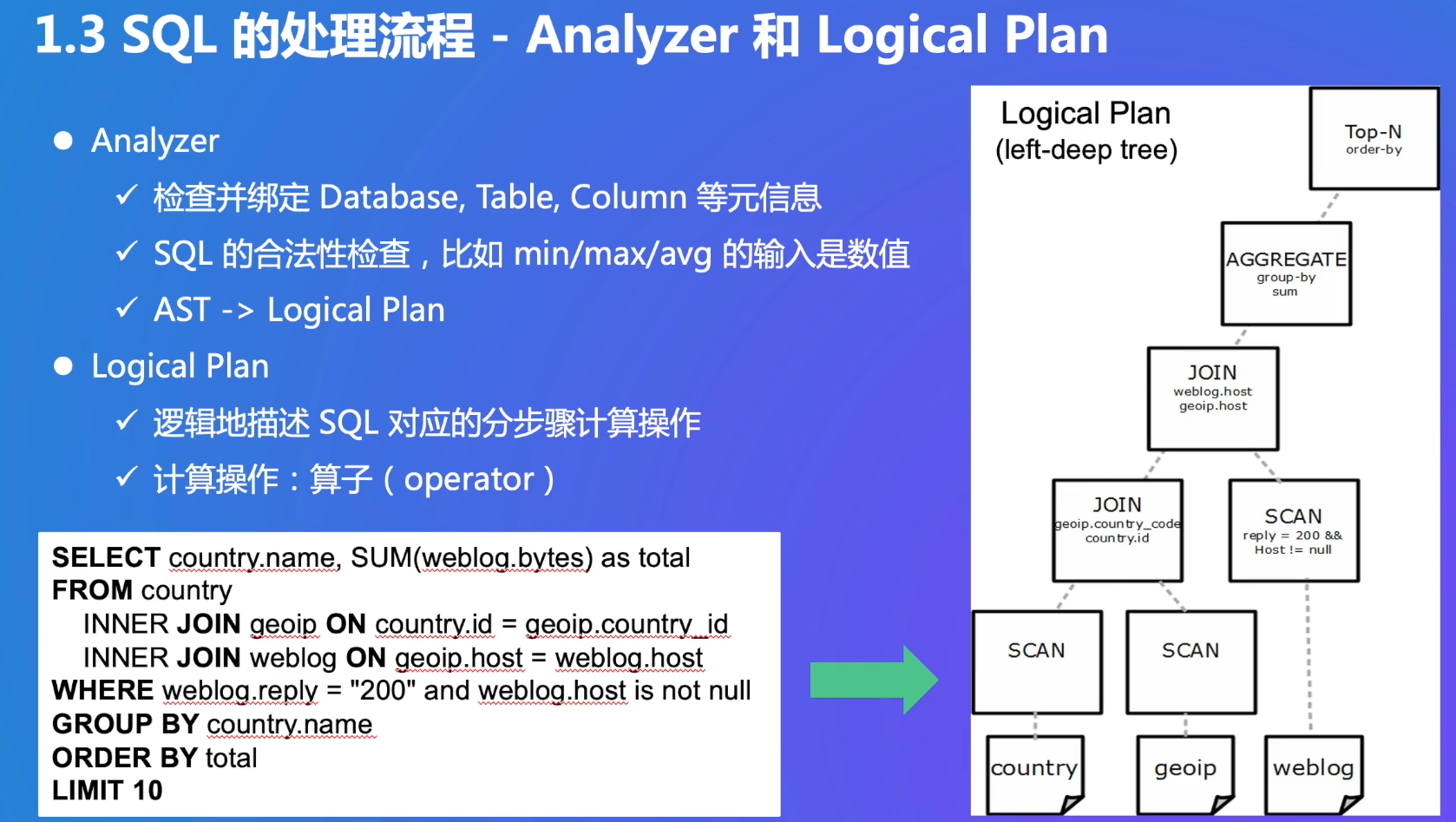
查询优化:找到正确和执行代价最小的计划,对效率的帮助很大,有些是NP的。单机可能优化比较简单,大数据:多机、多张表,执行性能相差很大,需要优化

拆分执行计划(F#1->F#7),发送给节点,充分利用并行机制。子树拆分也是一个优化问题
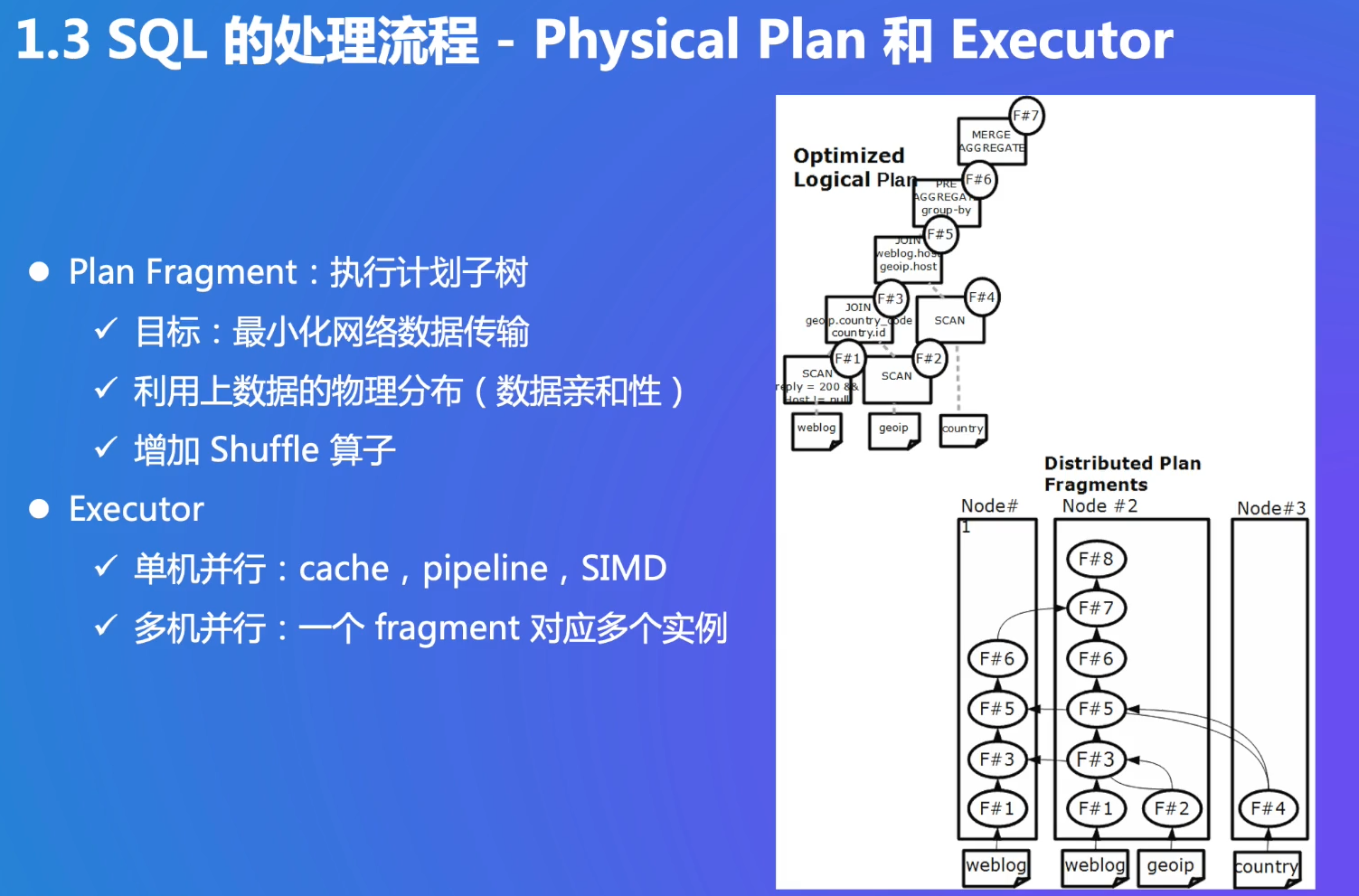
总结:

2. 常见查询优化

RBO
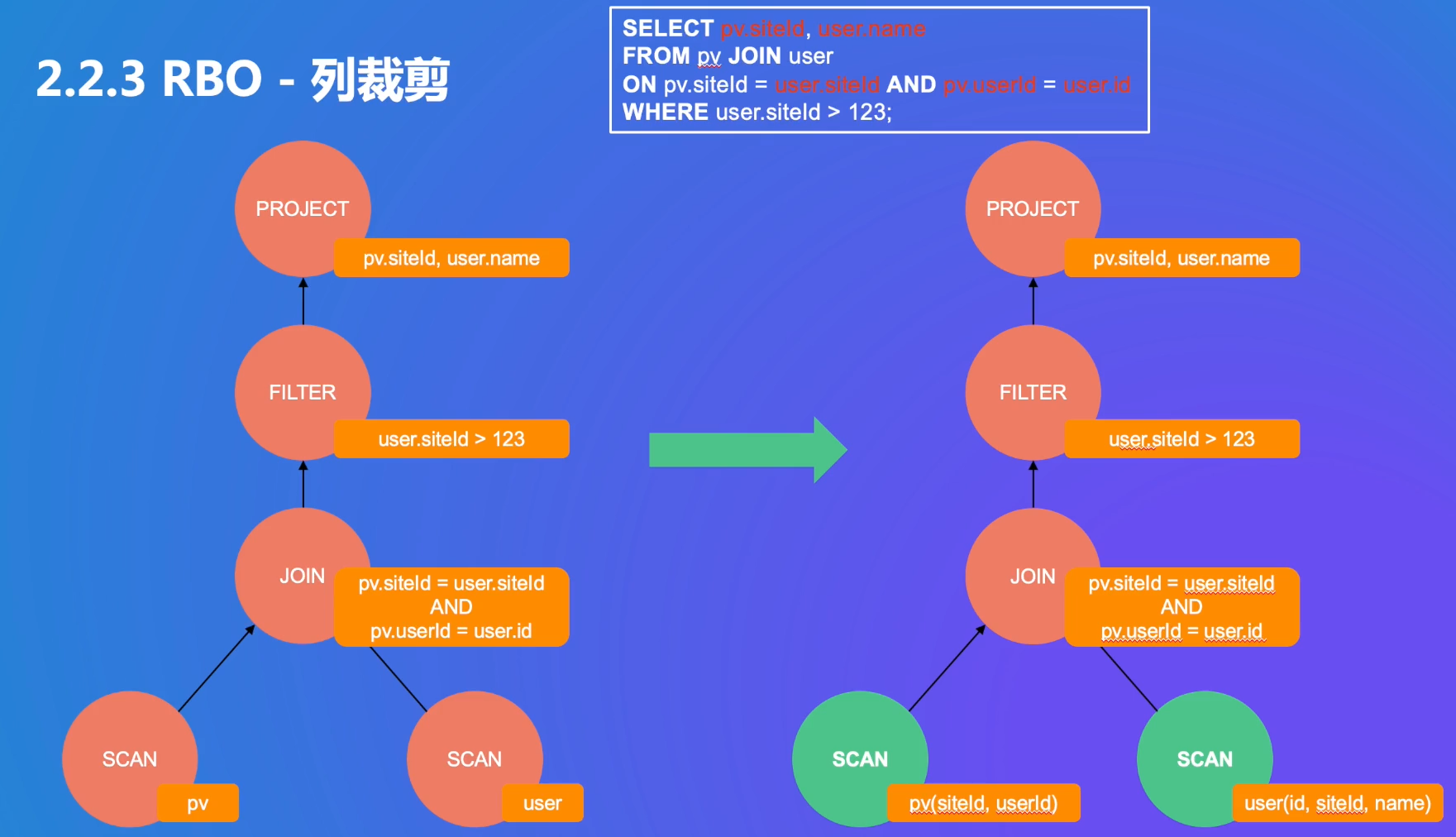
运算符可以拆分(结合律),表连接时顺序可以变(交换律)

优化网络:project选出两列出来

优化规则1列裁剪:用不到的列去掉,可以减少IO和内存占用,只使用需要的列
优化规则2微词下推:filter是谓词,尽早地过滤数据,减少传输和计算开销。下推是有条件的,这里的join不影响
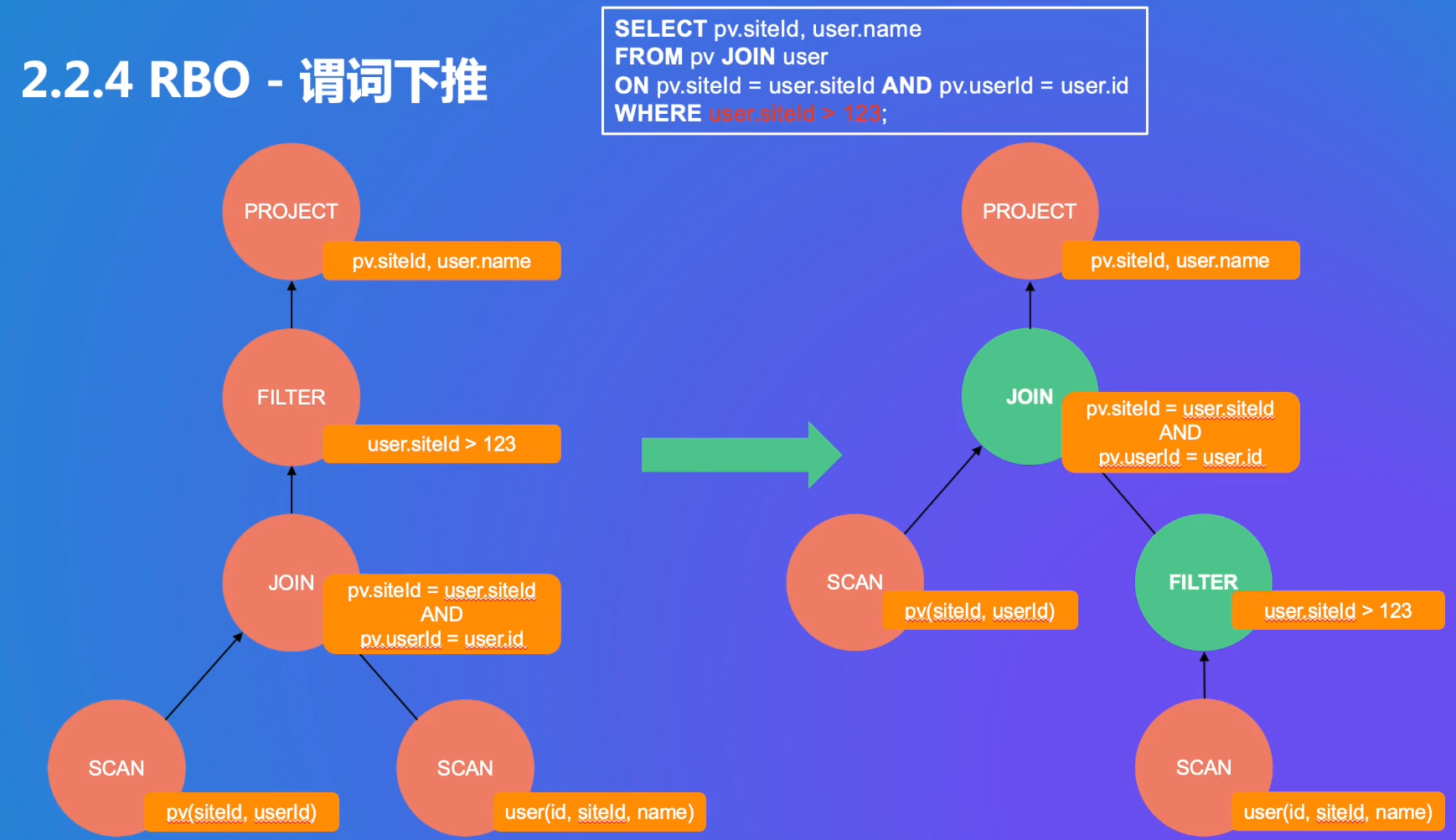
优化规则3传递闭包:没有filter创造filter
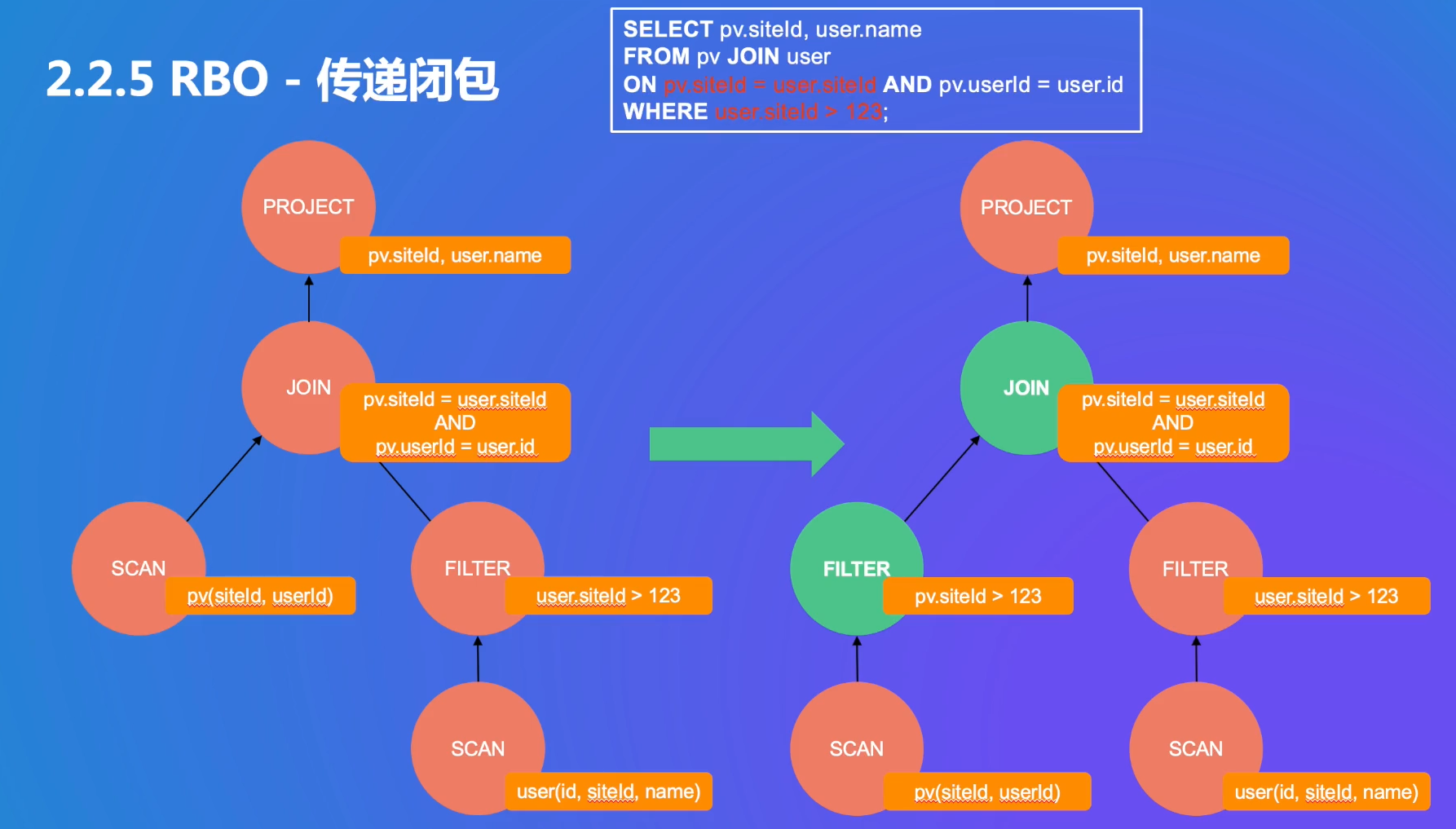
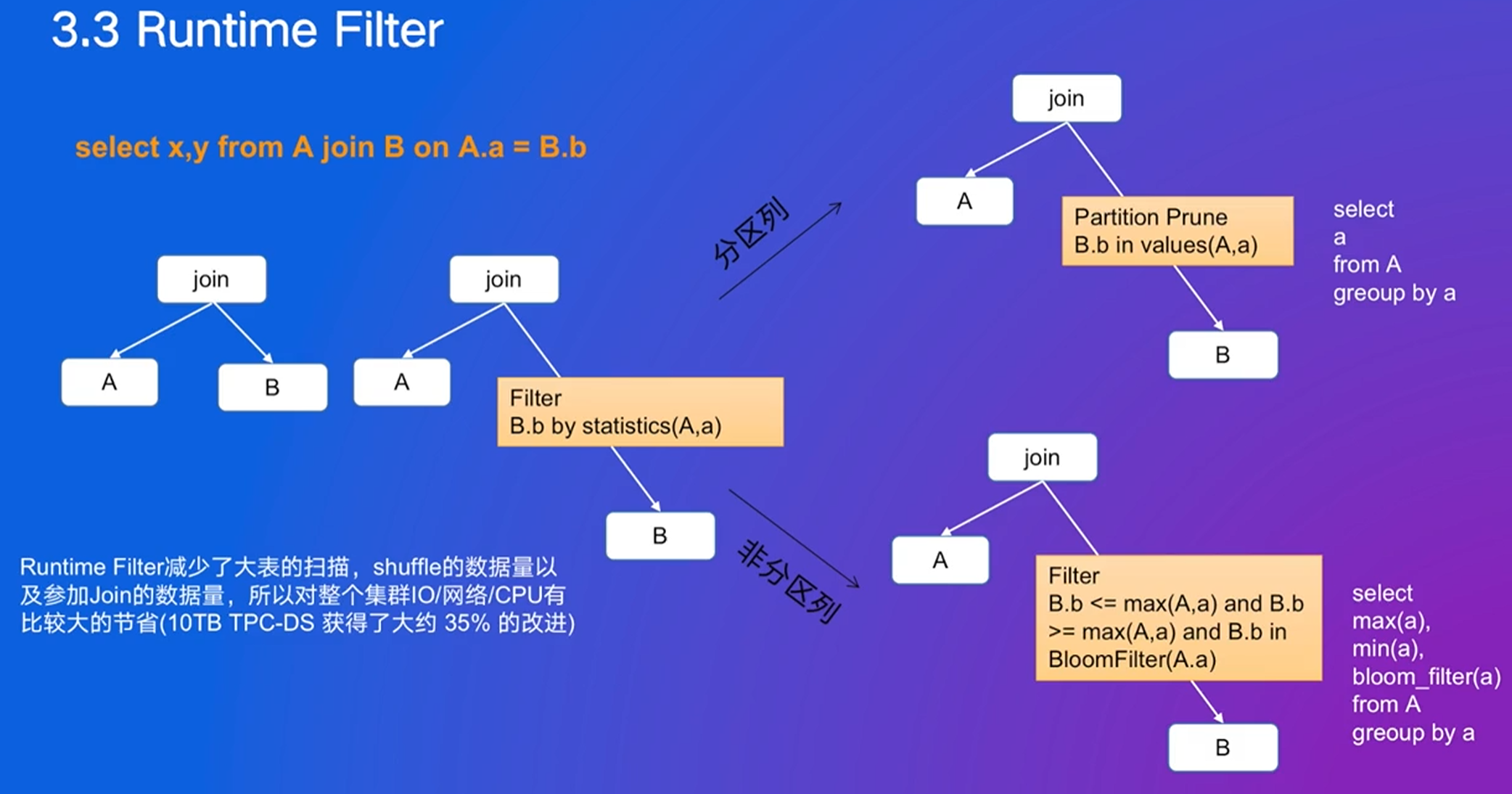
优化规则4 Runtime Filter Builder构建哈希表:min-max:右边的数据的最大值和最小值;in-list:0-100的101个数,和100万的1个数,用集合排列;bloom filter:固定大小,不随集合大小改变
- 传递给左边,减少左边的扫描量
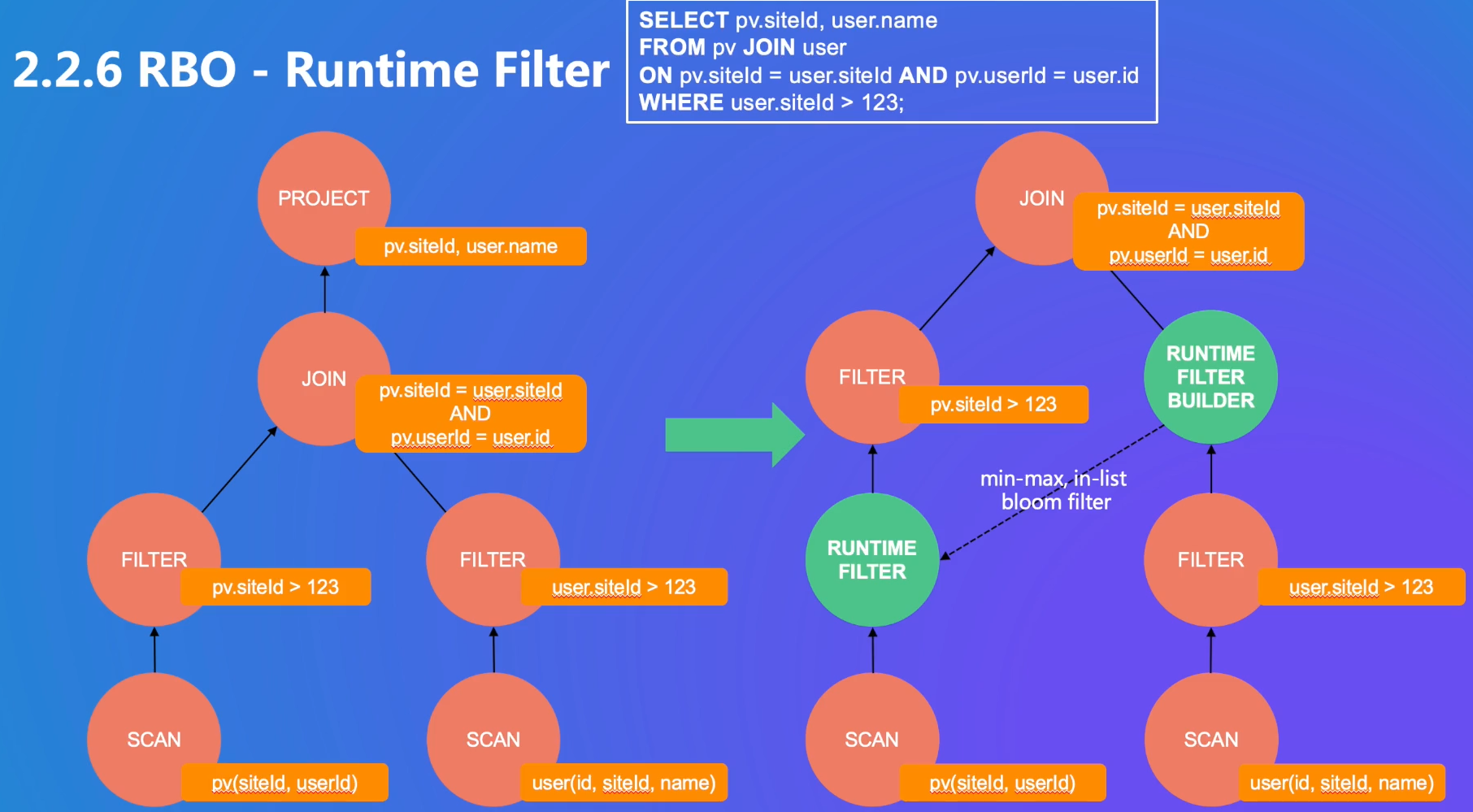
缺点是不保证得到最优的执行计划

CBO
用模型来估算执行代价->拆解成所有算子,得到所有可能得执行计划
公式比较多,每个系统不一样

选择率:对于过滤条件,会返回多少比例得数据
基数:算子需要处理得行数

三种方式在实际中都会用到,用于统计信息便于推导代价最小的计划

fs是filter selectivity 选择率

有些列是有关联性的,比如车型和制造商,不能按照独立性相乘,需要特殊处理此类统计信息

得到统计信息后,如何找到代价最小的执行计划?枚举:贪心或动态规划,全局最优->局部最优

计算子问题的代价:如三表连接先用两表连接(两种连接方式),选最好的
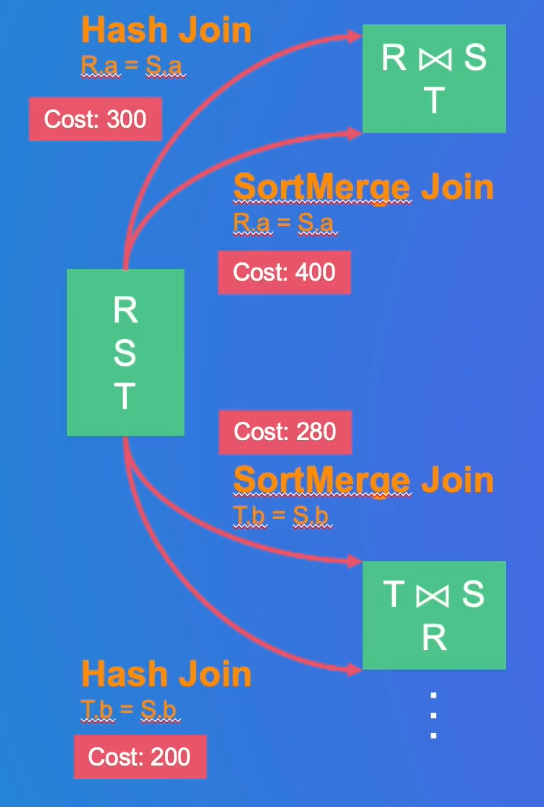

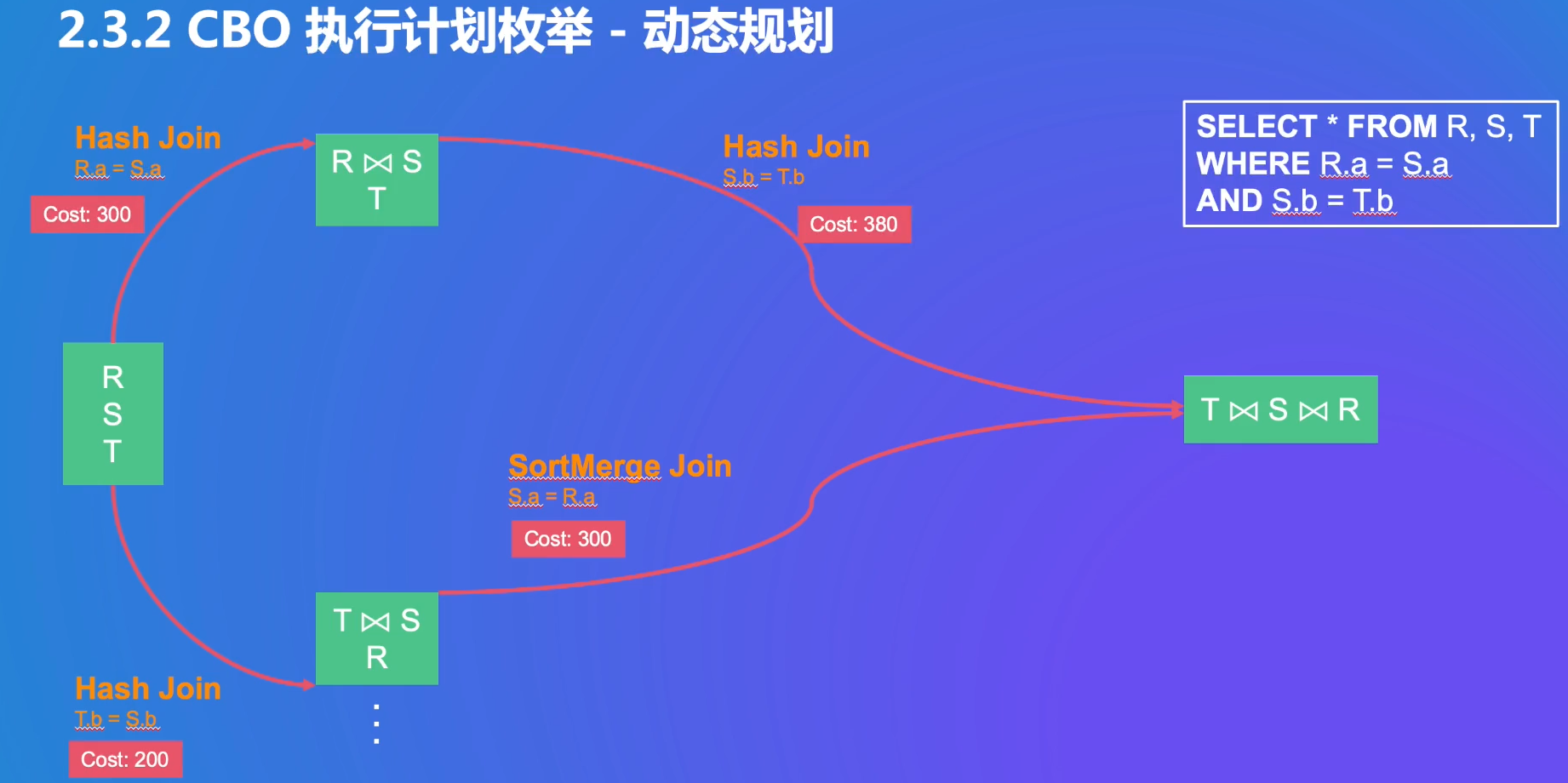
大表和小表连接开销会很大:
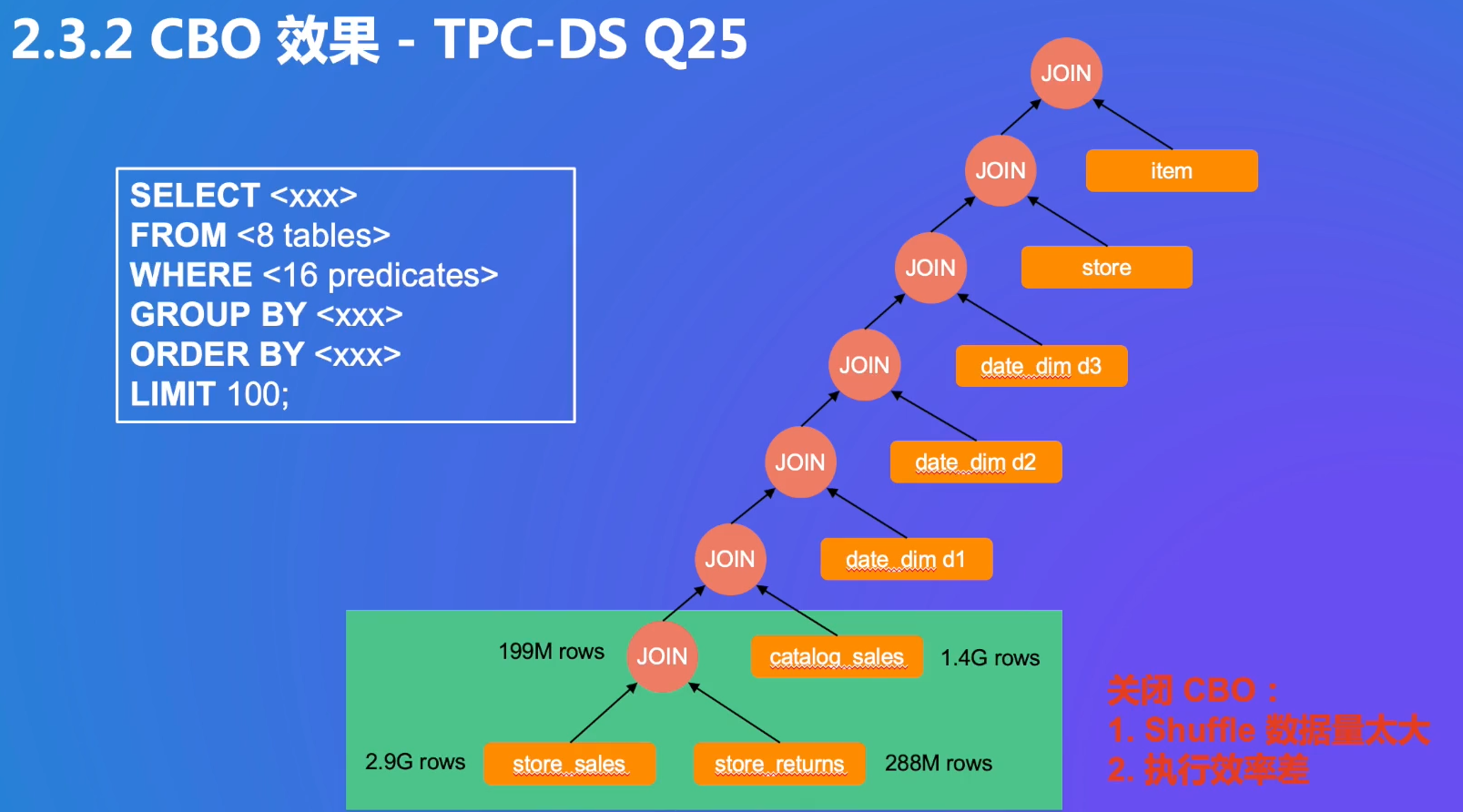
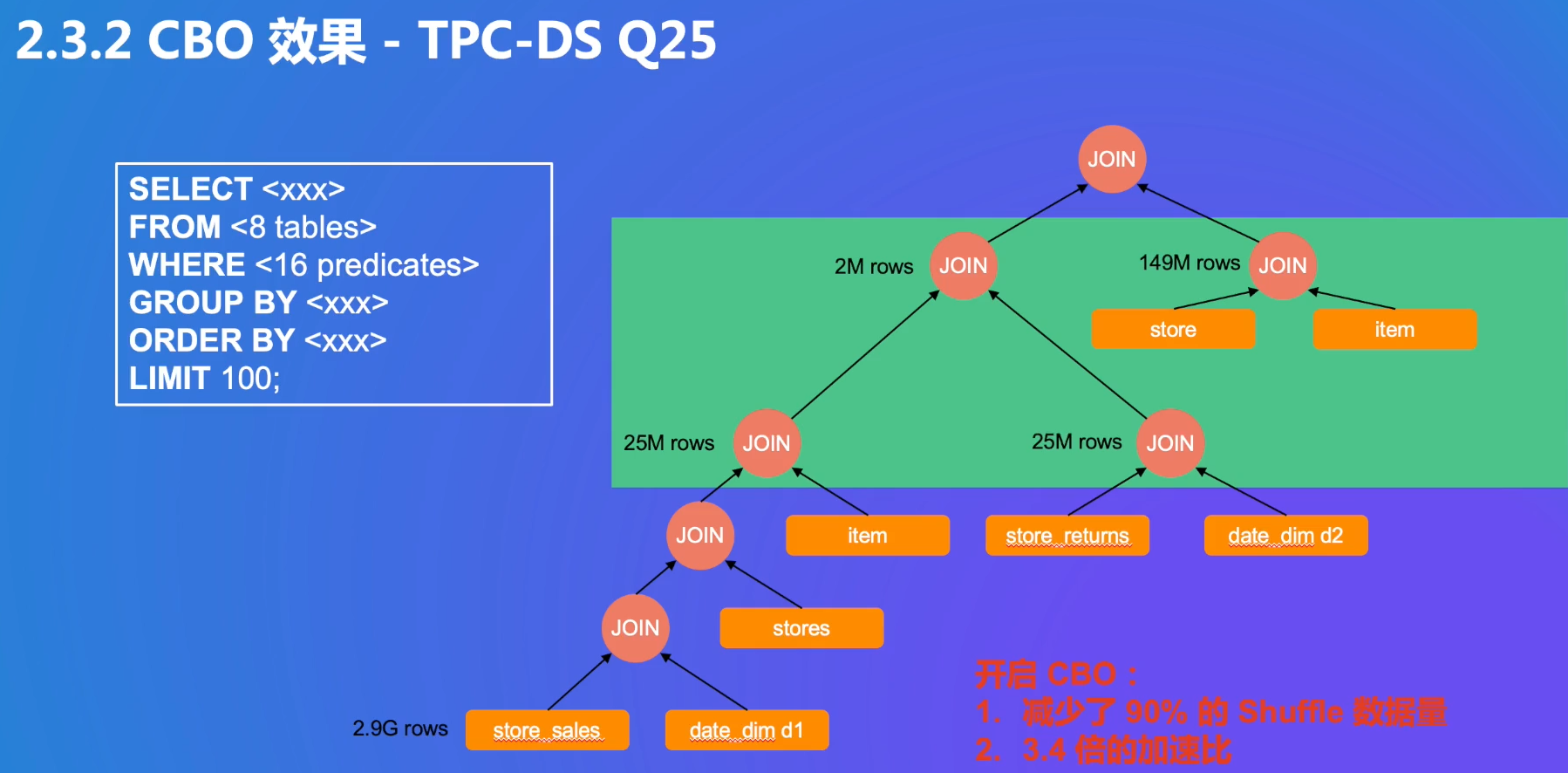
CBO可以减少数据量(这个例子是spark的)
有一些query在CBO下有很好的提升
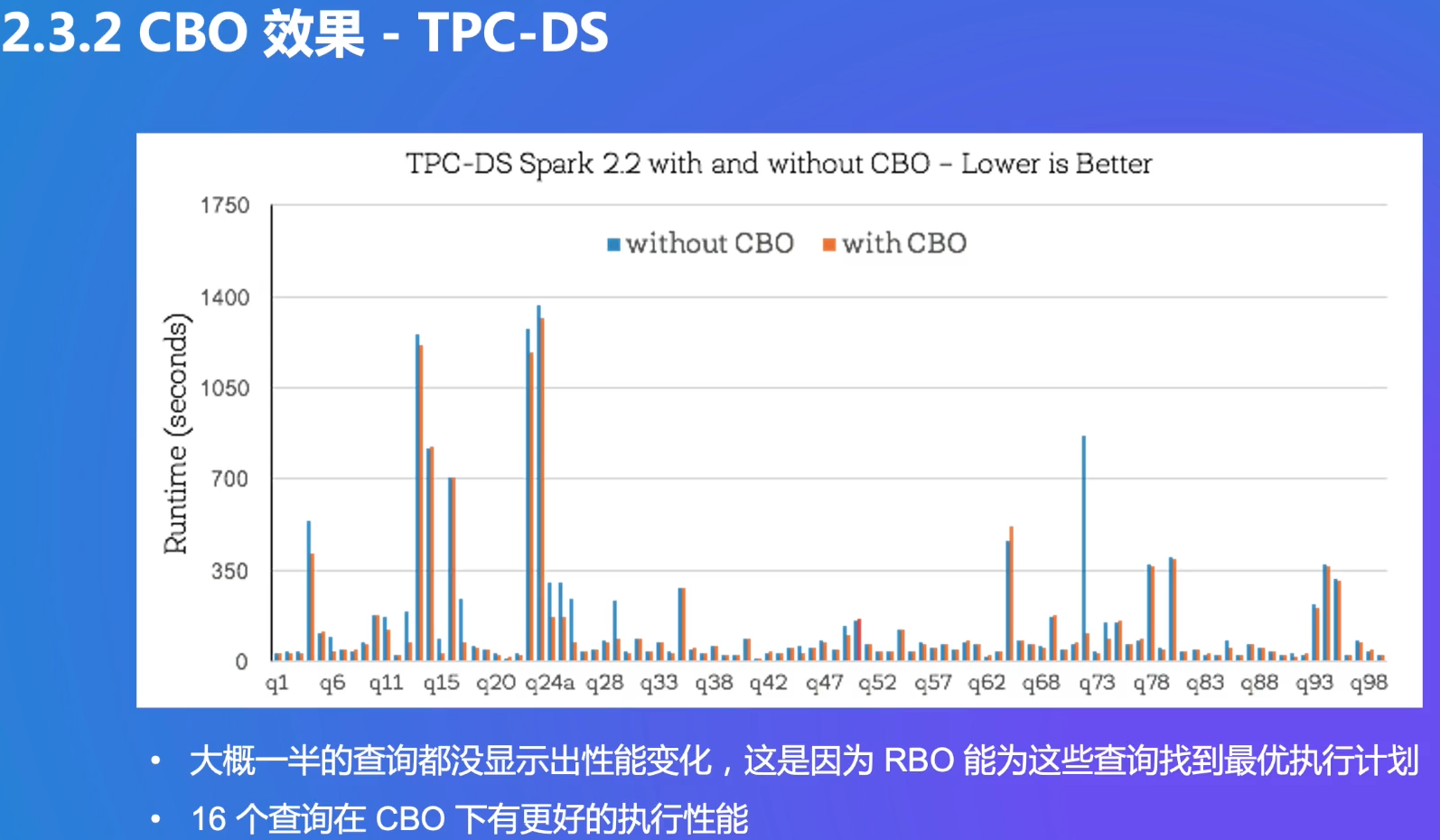
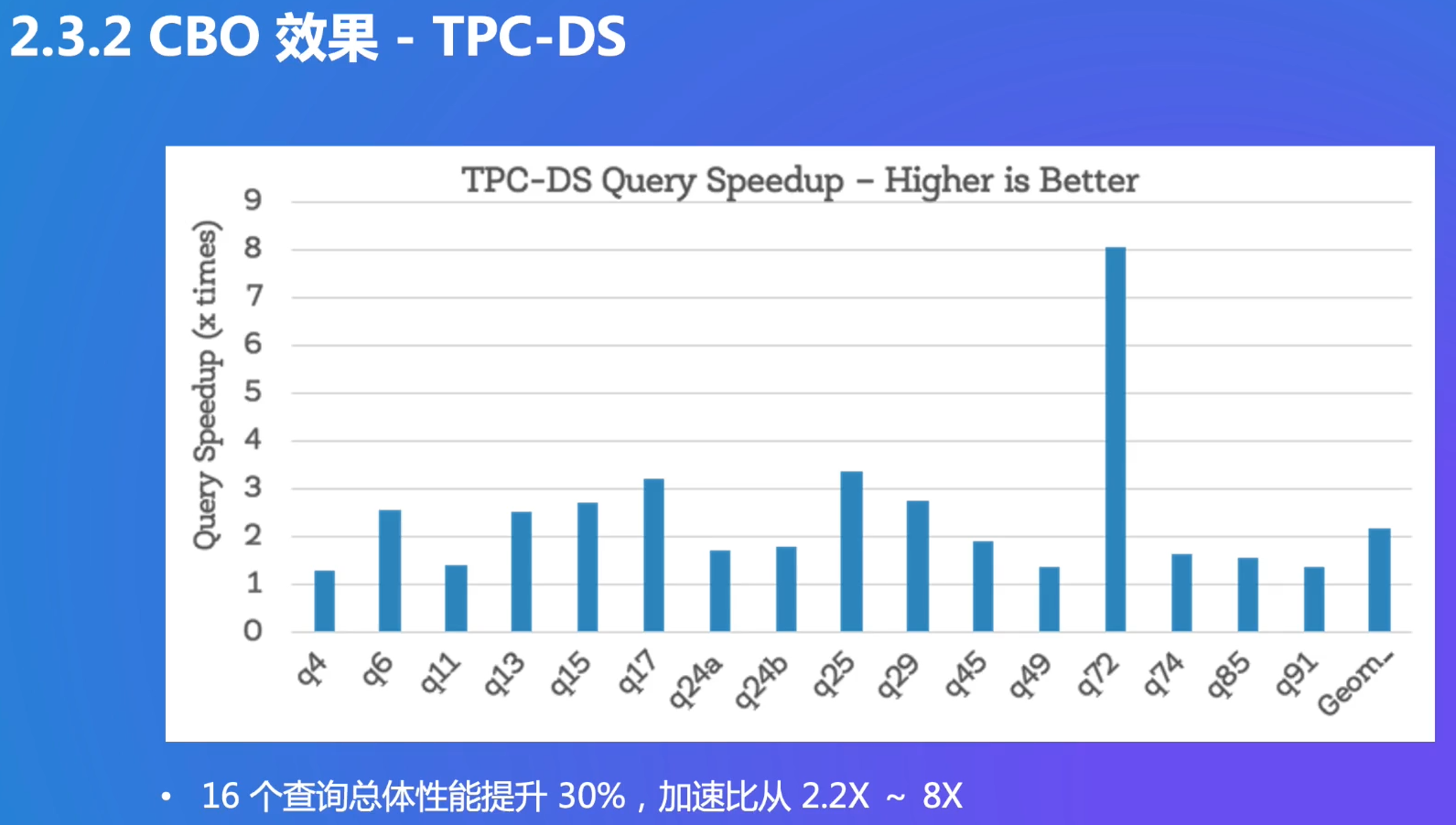
大数据下CBO重要

3. 社区开源实践
Calcite是Java,Orca是C++
Clickhouse只有简单的RBO
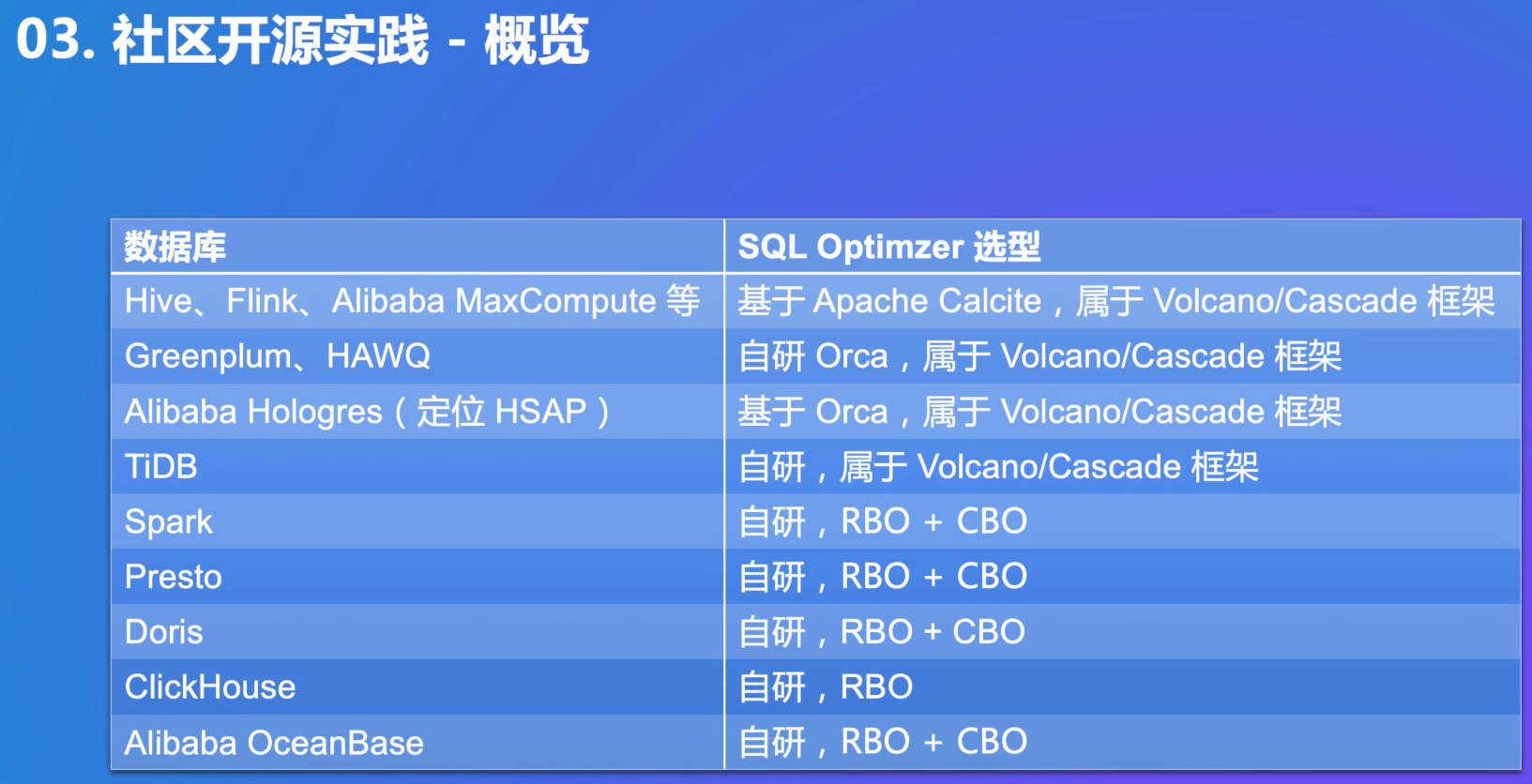
作为通用的SQL查询引擎
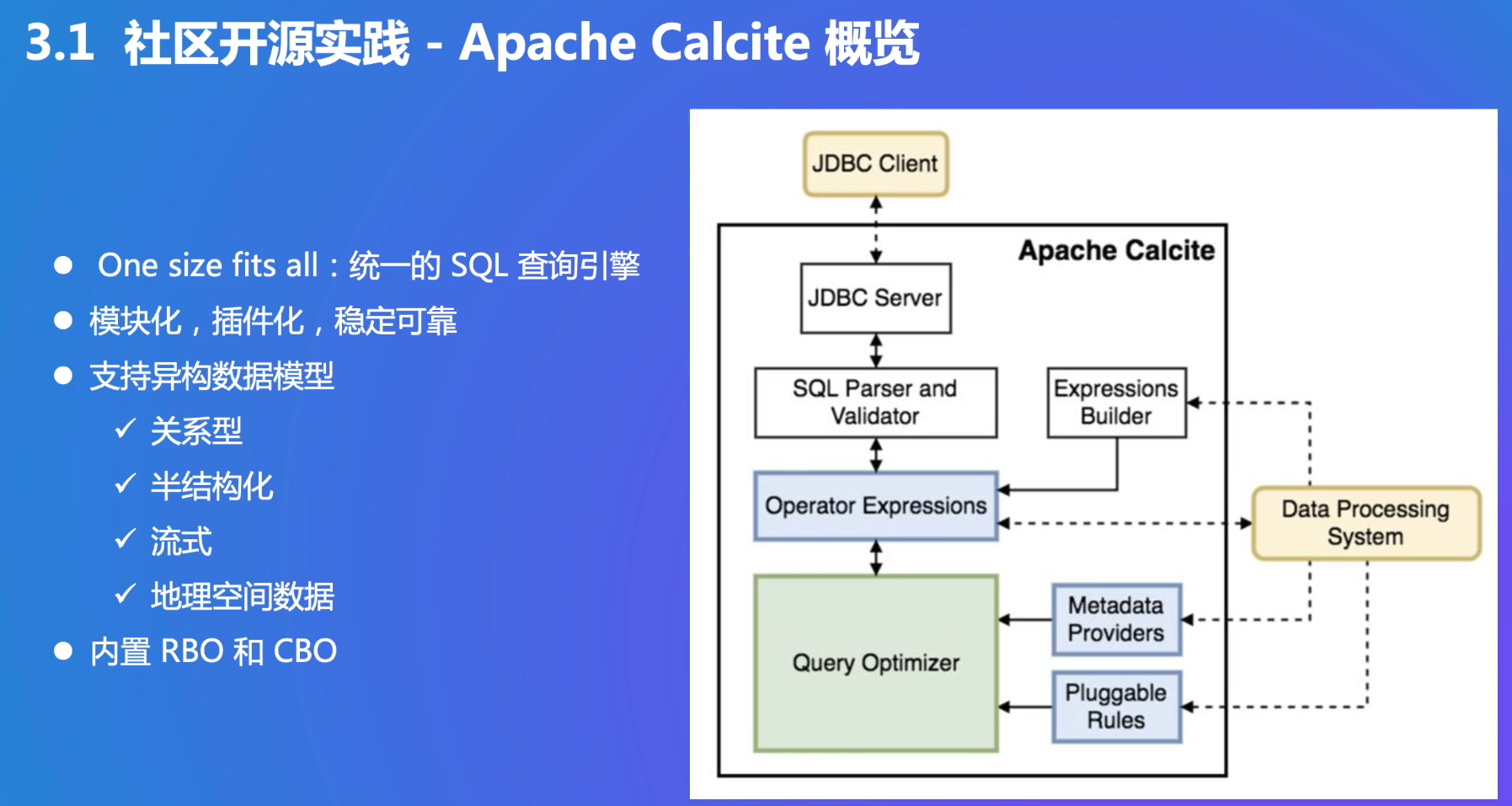
核心是Query Optimizer
- Metadata是统计信息
- Pluggable Rules是插件,可以不同系统定义不同的规则
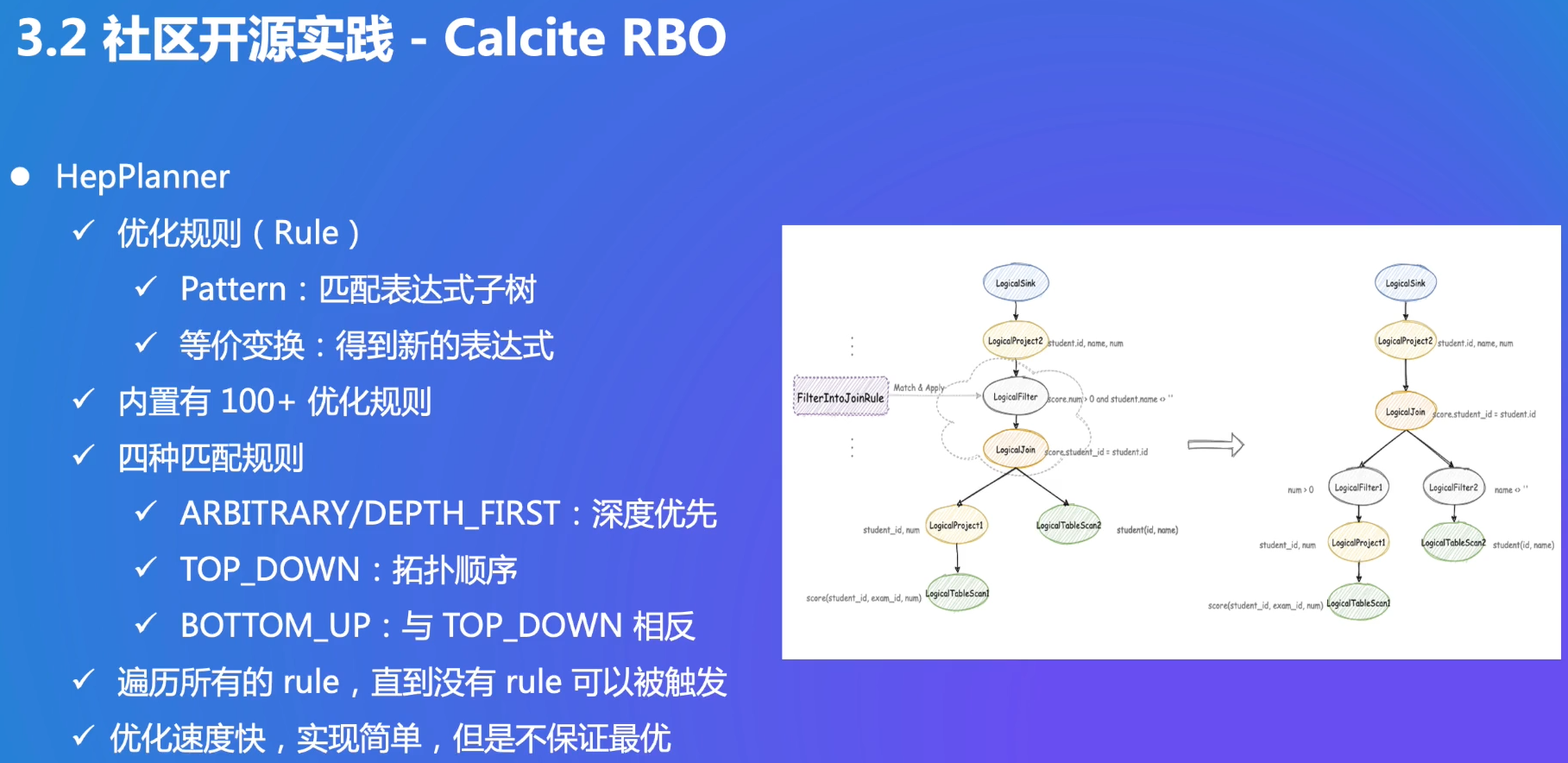
RBO:遍历树,等价替换成新的规则
把Logical Filter拆成两个Filter
CBO:求每个子问题的最优,用memo记录,初始每个算子放在一个group里

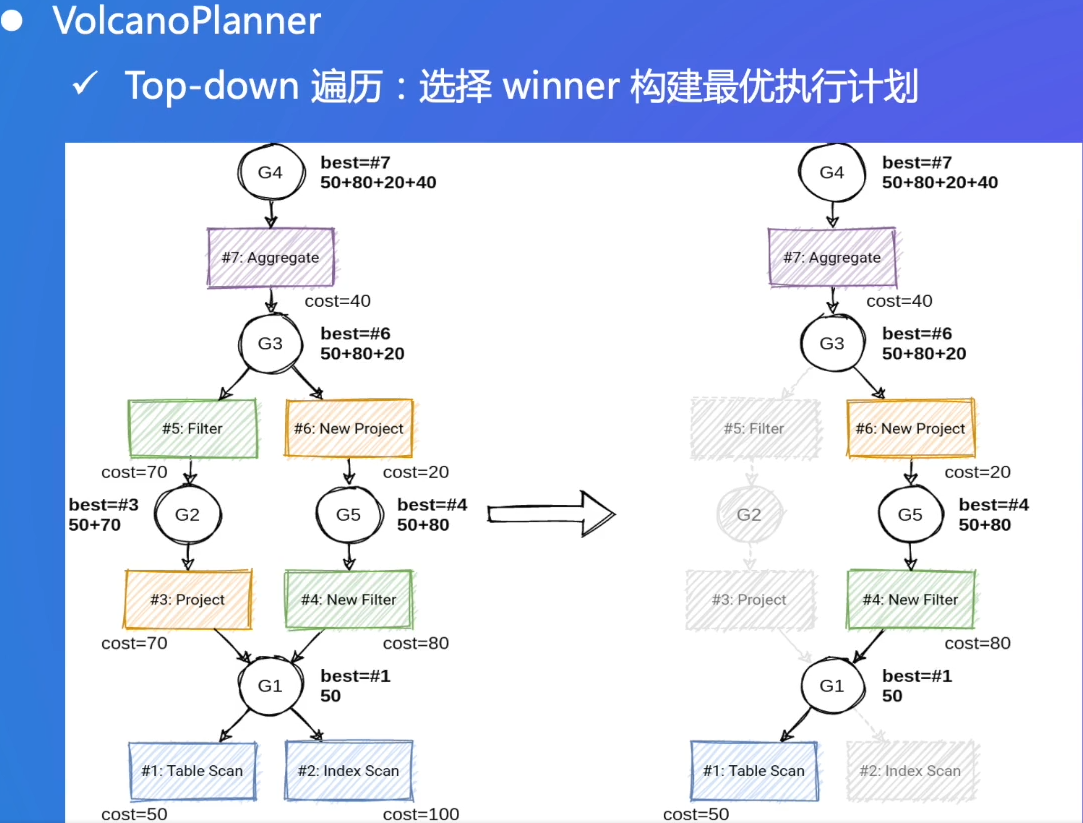
从上往下遍历,才能得到完整的执行计划
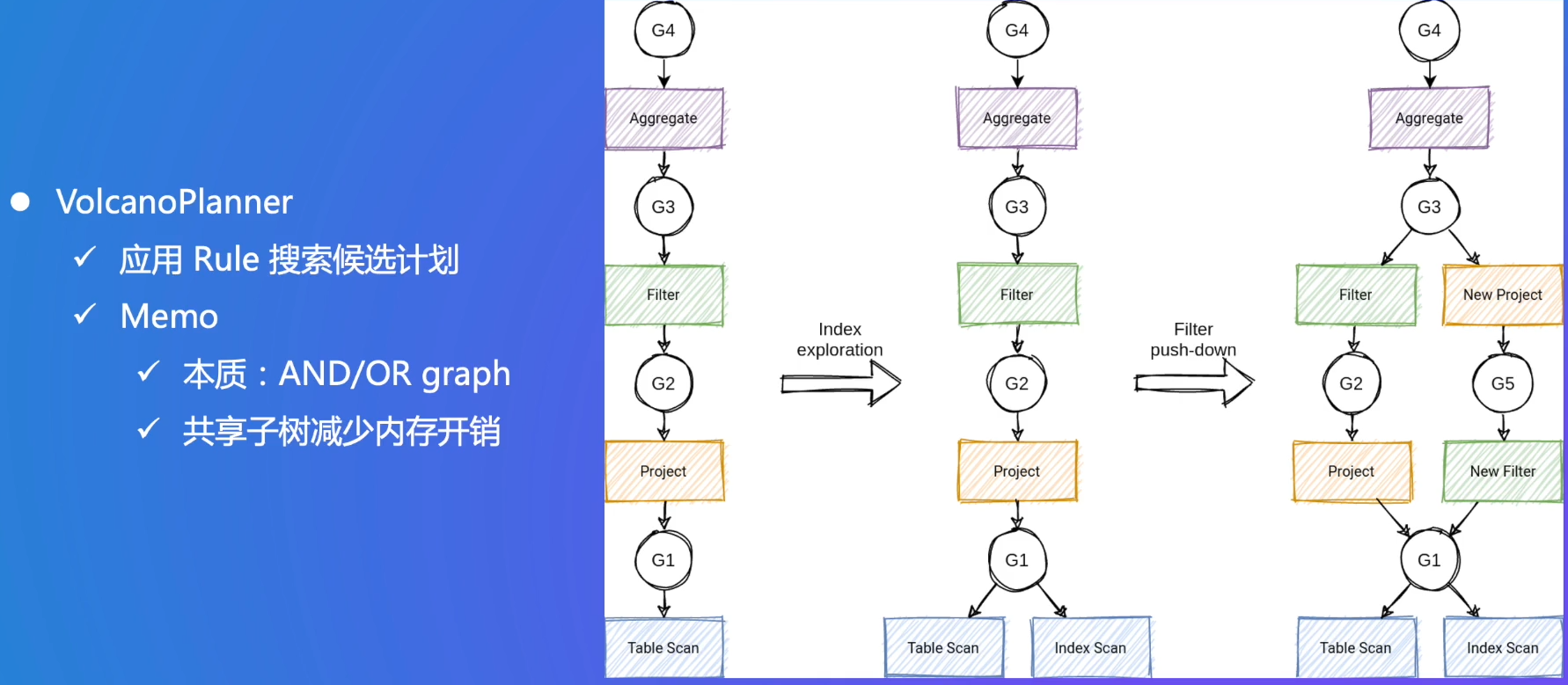
最优解是递归退出来的,best1->best3…

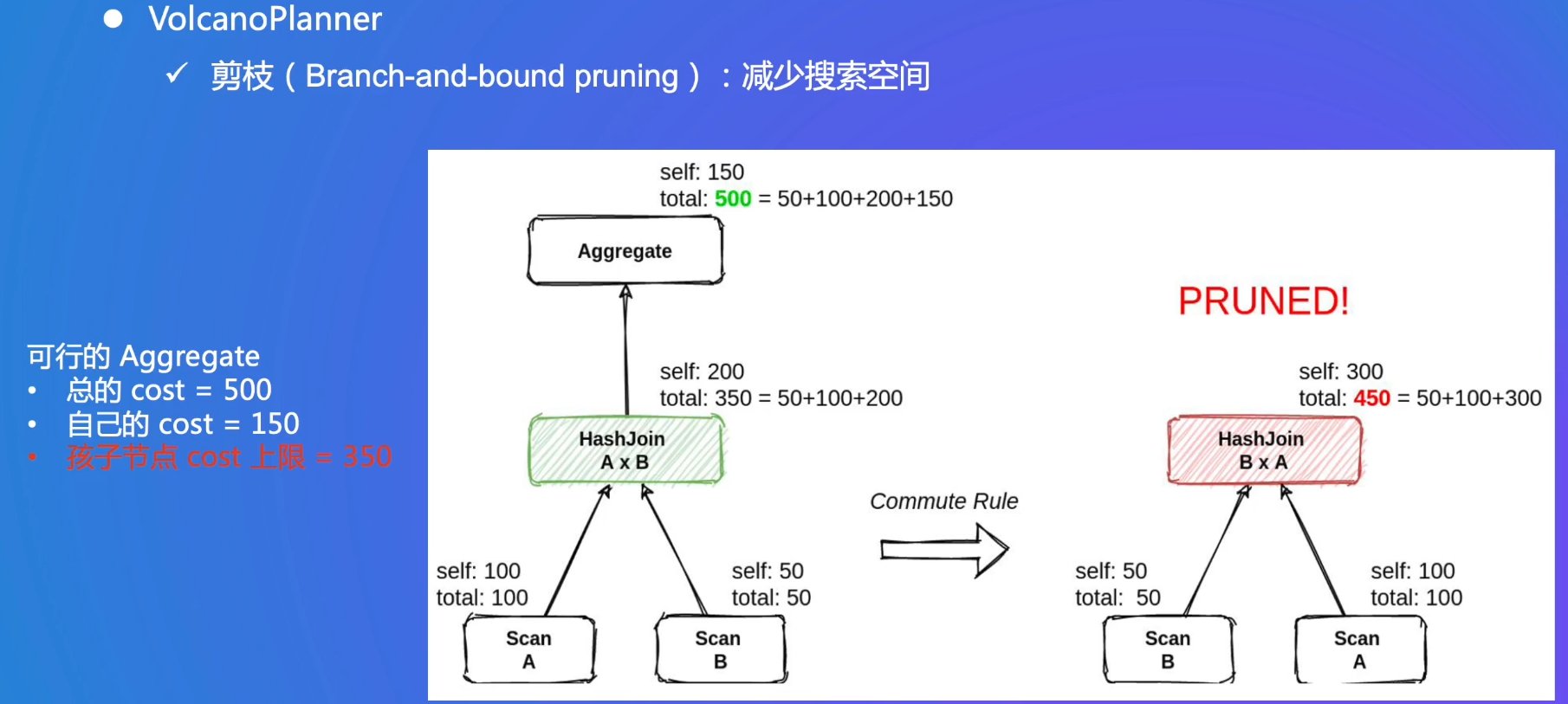
剪枝:避免遍历所有空间,如果已经超过上限了就不看了
Top-down:注意是全局最优,所以第二行选了cost=80

4. 前沿趋势
视频是22年录的

趋势:
数据仓库:预先定义表和模型,对原始日志进行管理,存入:对业务迭代不太好,因为固定结构,不包含原始日志。数据湖就比较灵活,希望两者结合。联邦查询。
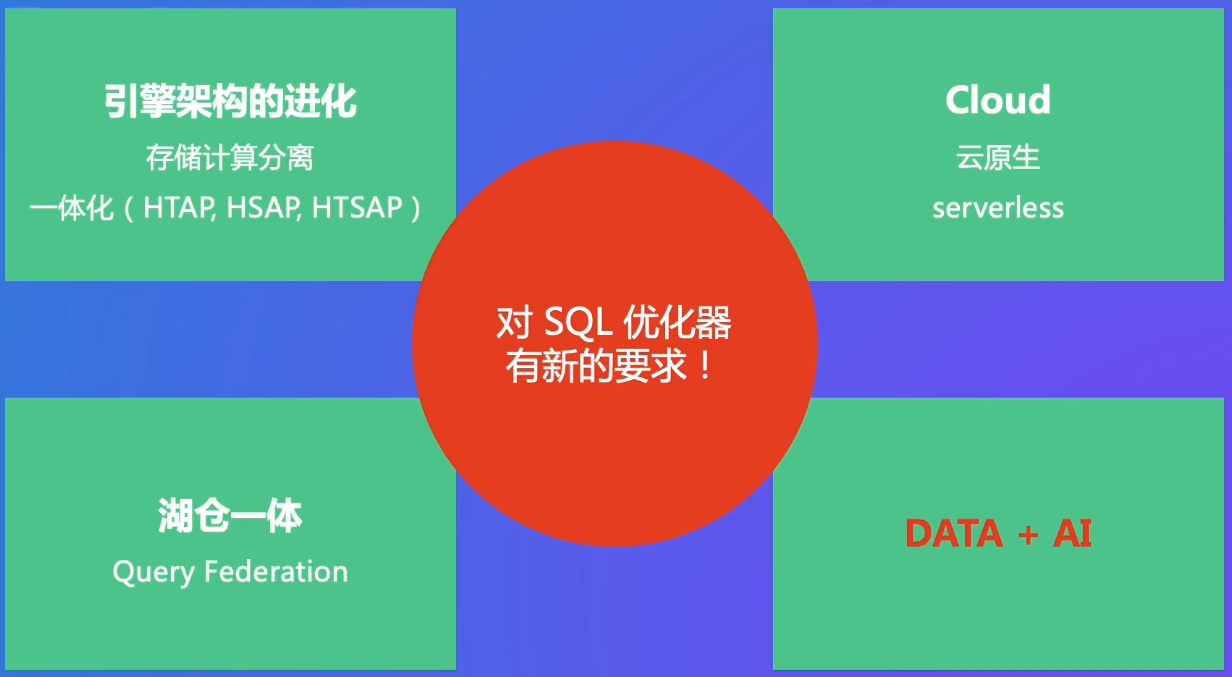
用AI进行SQL查询优化。建索引、视图根据经验。
在数据库里嵌入AI算法,让用户学习成本更少

优化器必不可少,很重要

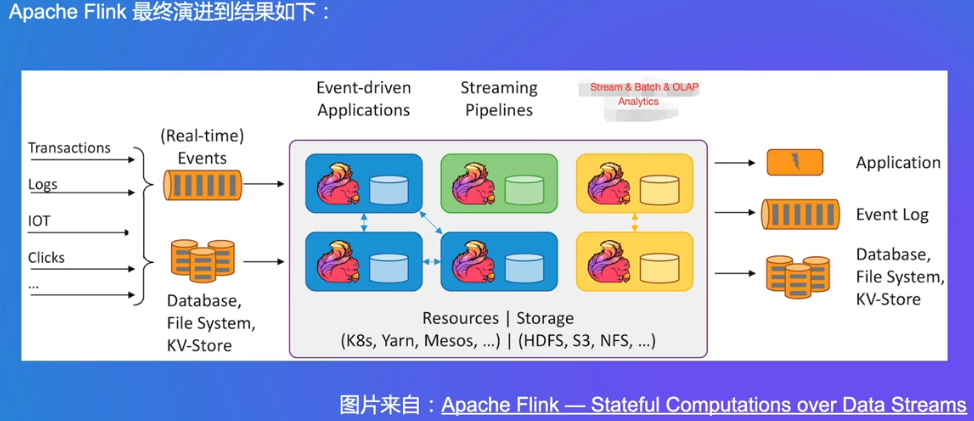
2. 流/批/OLAP 一体的Flink引擎介绍
Flink:实时分析
1. Apache Flink 概述
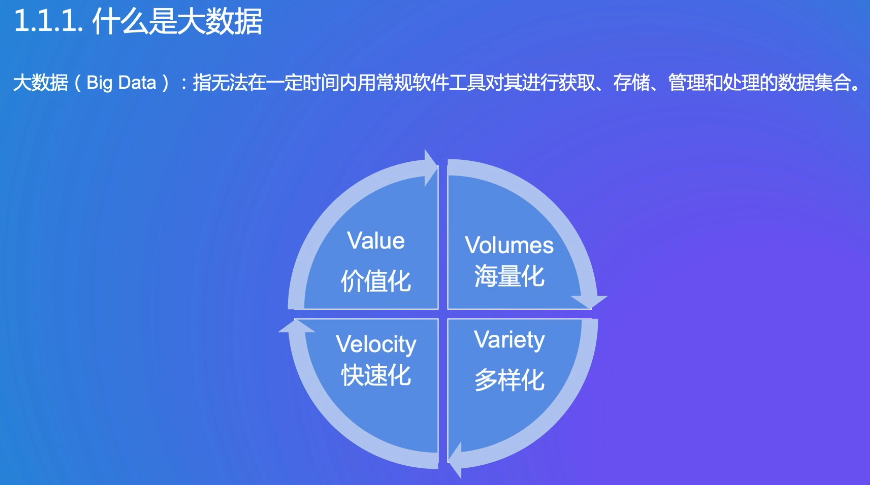
不仅有结构化数据,还有音频、视频等非结构化数据。

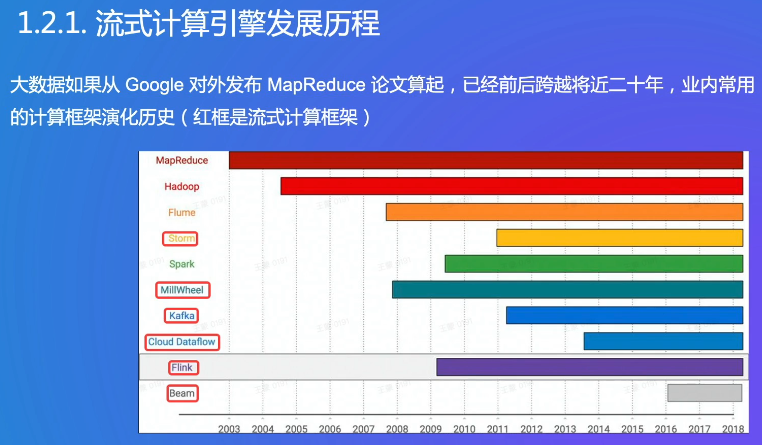
随着数据规模扩大,Google发布了三个论文:HDFS/MD/离线计算。
Spark:MD的数据罗盘,Spark内存迭代;MD有两个算子,api比较固化,Spark支持sql
Flink:流式数据处理实时数据,支持SQL


批式数据处理的是静态数据,一批到了才处理
流式计算:水龙头,对实时数据,动态无边界,持续不断地运行

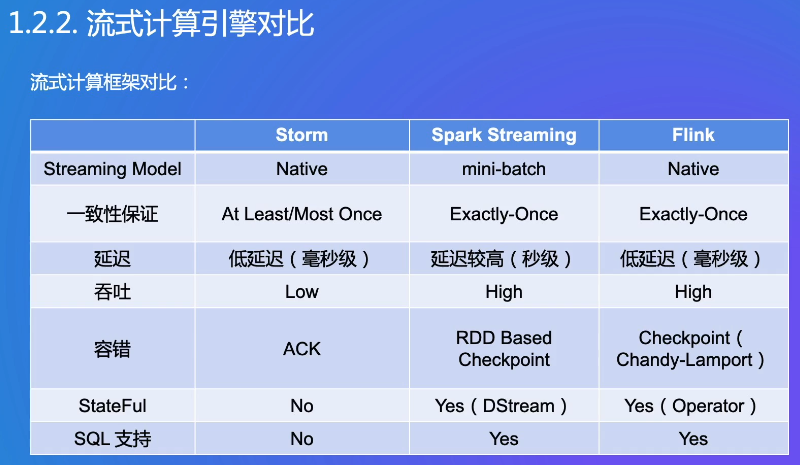
能否做到精确一次计算
状态:Flink之前,中间结果会存在外部数据库,现在不用依赖外部系统,用引擎完成处理需求
SQL很重要,对业务维护成本低

可以基于无边界(Kafka消息队列,流数据)和有边界数据集(批数据)进行处理,既可以处理流也可以处理批数据
- Dataflow思想
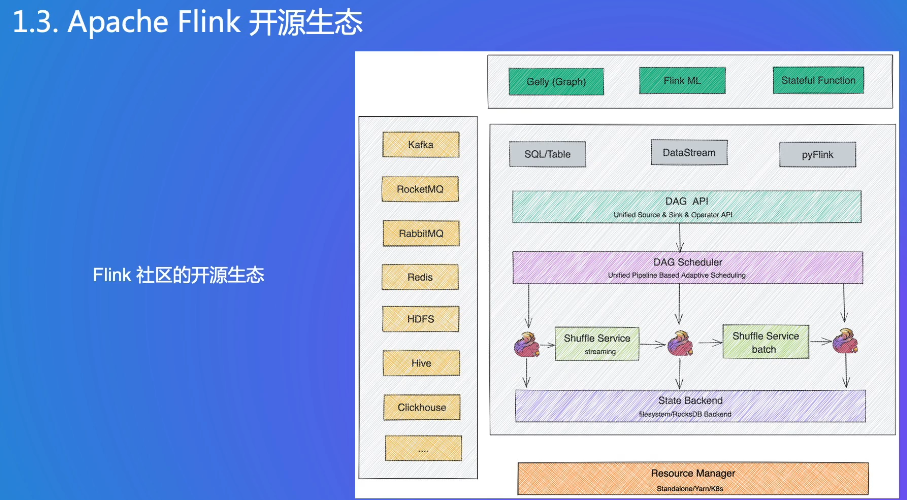
可以部署在k8s等
可以支持图计算
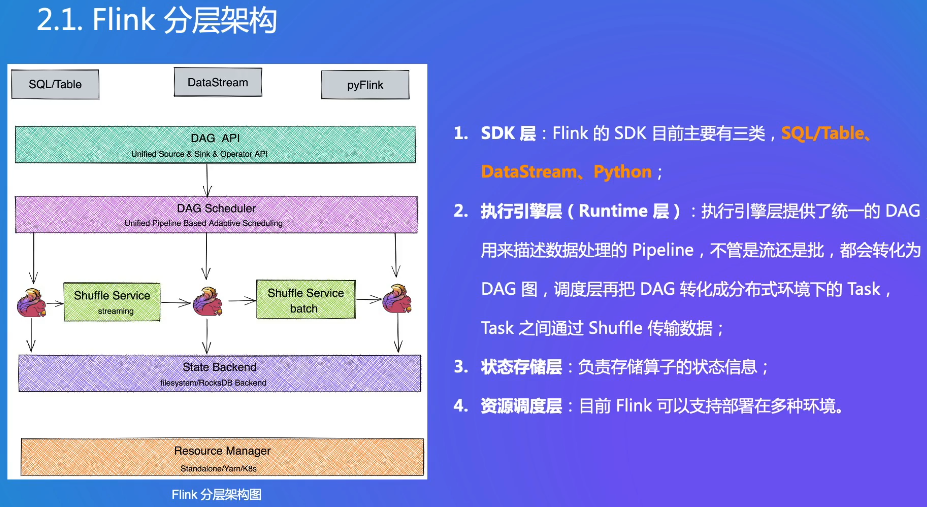
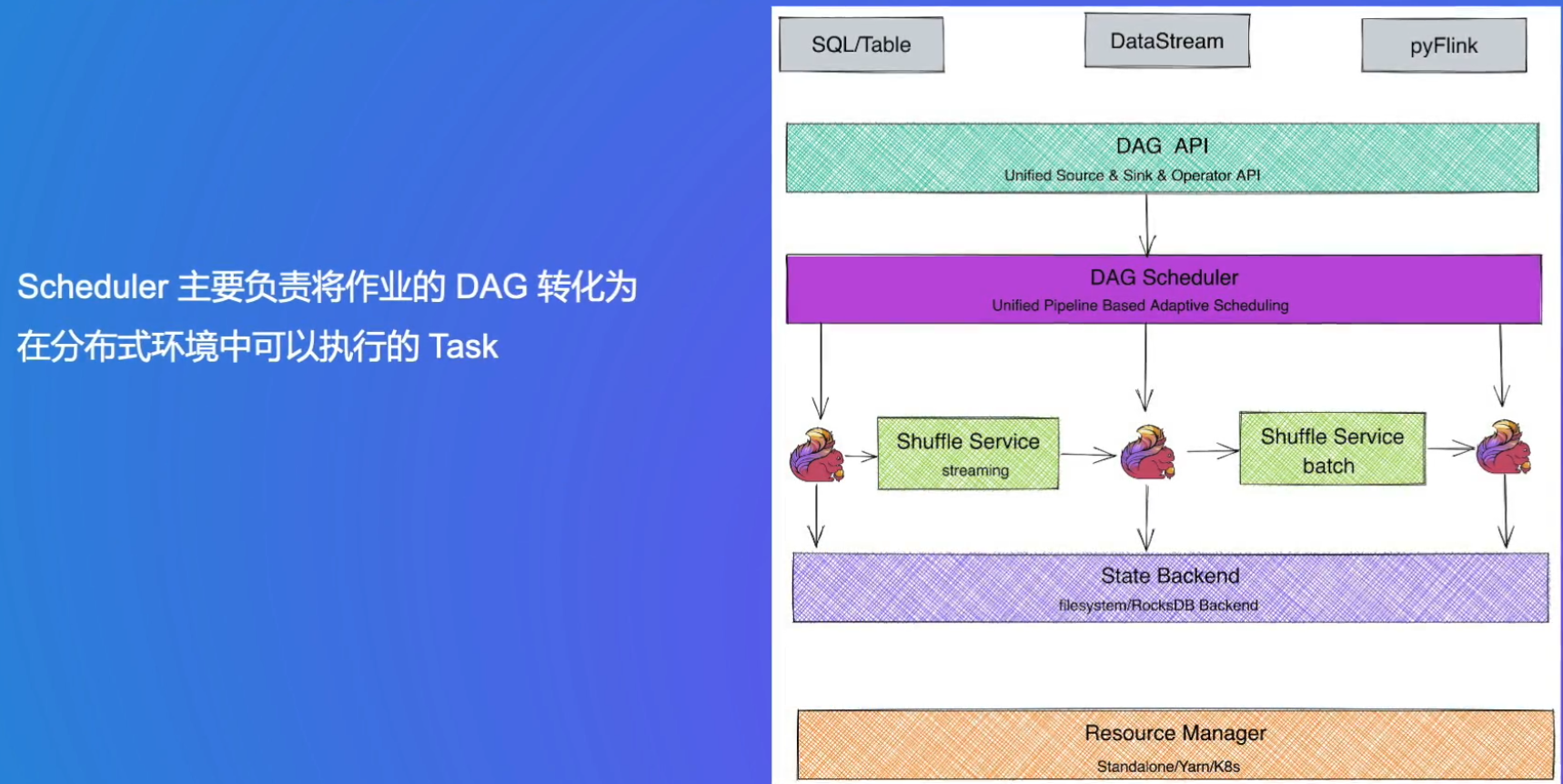
2. Flink整体架构
有些场景SQL写不了,用DataStream的Java API,Python是实现一些ML解决方案的基础
Task之间会有一些数据交换,使用Shuffle Service
状态数据
SDK是Software Development Kit(软件开发工具包),可以同时使用不同的SDK
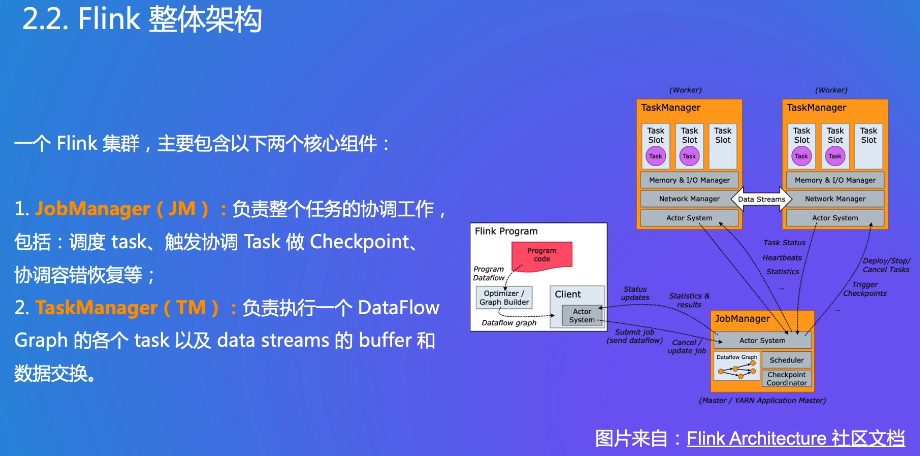
JM:恢复task重新调度
TM:TM之间有数据交换的需求
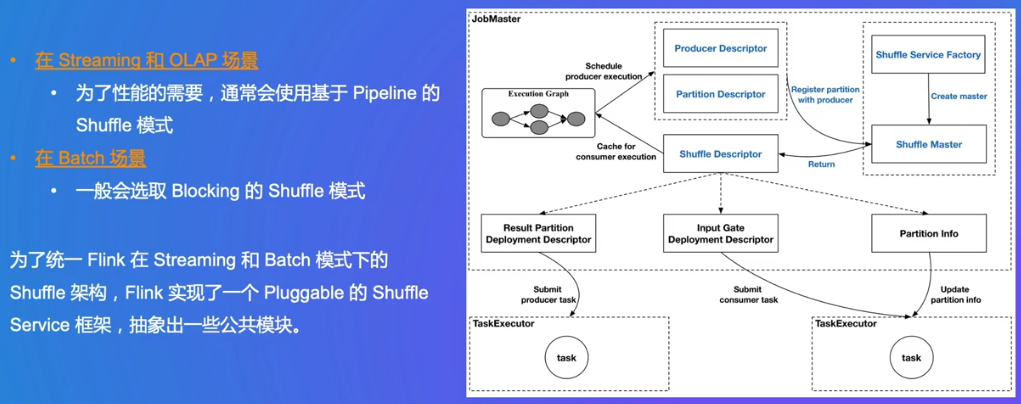
Client端会将用户代码抽象为逻辑的执行图,JM将逻辑执行图转化为物理执行图,调度到不同的Worker节点执行
Dispatcher:

从Kafka消息队列中读流数据
timeWindow是10s一次,“sink”(接收器)指的是数据处理流水线的末端,负责将处理后的数据输出到外部系统 。

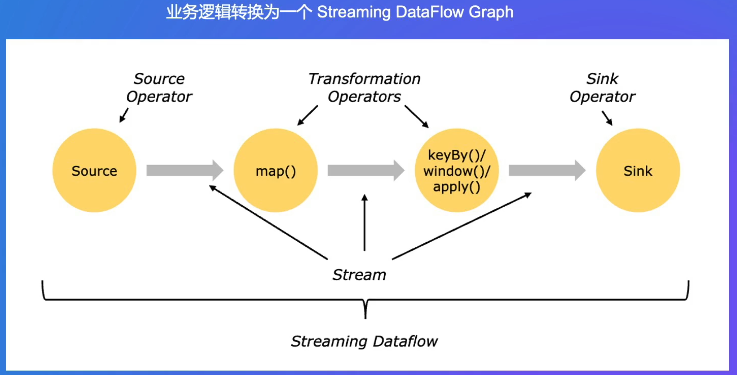
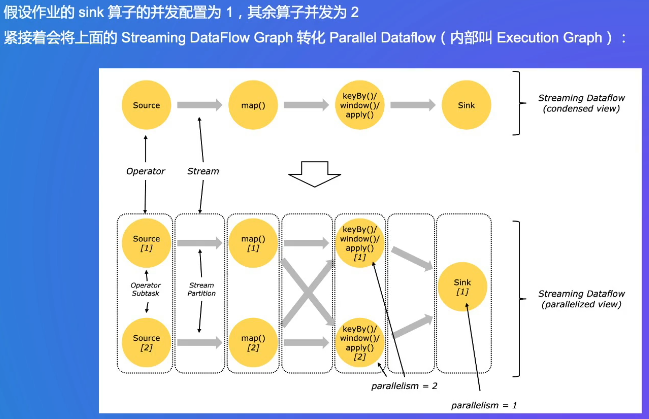
配置情况:sink 算子的并发配置为 1,意味着只有 1 个任务处理数据输出;其余算子(Source、map、keyBy/window/apply)并发为 2,表示这些算子分别有 2 个并行的子任务来处理数据。不同子任务间通过 Stream Partition 传输数据。而 Sink 算子只有一个子任务,它会接收来自上游两个并行子任务处理后的数据进行最终输出 。 这种配置体现了数据处理过程中不同阶段的并行程度差异。
下图是从逻辑图(精简视图)到并发视图的过程
source和map可以chain在一起,可以在一个线程,读到数据就马上map,不存在线程的切换、数据序列化和反序列化,chain在一起后提升效率(减少了数据在TM缓冲区的交换,减少延迟提高吞吐率)
什么算子可以chain在一起是有一些判断条件的
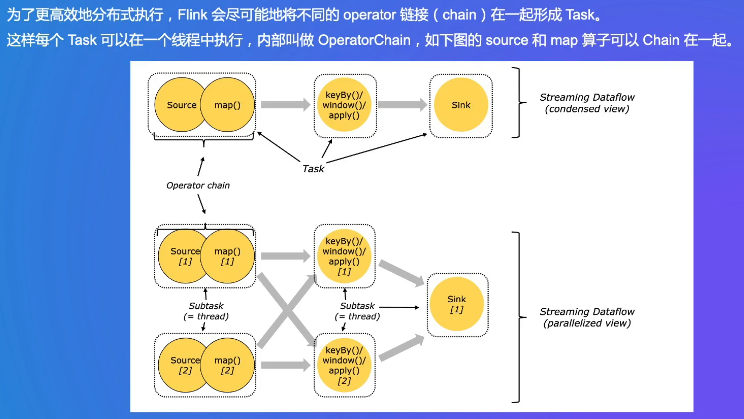
TM申请了一些资源,一个TM包括几个slot是用户自己定义的,一个slot是一个独立的线程,slot之间的cpu和内存没有完全隔离,有一定隔离

上面就是完整的一段代码从精简试图到TM中slot这样具体结构的过程

流批一体
1是流处理,2是批处理
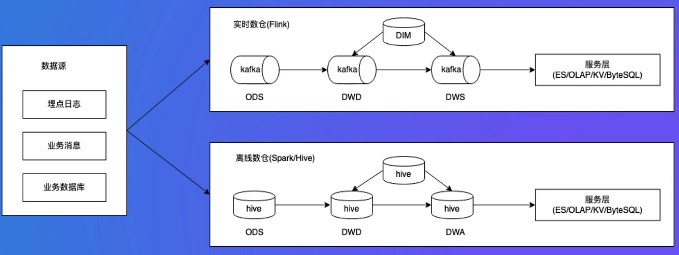
数据源:app的行为数据、活动数据等
实时Flink:统计一些数据,放到服务层
离线:查到一些用户的数据,提供服务


如何实现流批一体:

批式数据是特殊的流式数据,因为是有界的

如何支持:对于流式数据,按照时间段切成有边界

SQL:支持有边界和无边界的输入
DataStream:Java/Scala
调度层:流调度、批调度

Scheduler:DAG指有向无环图,可以用来表示这些任务之间的依赖关系和执行顺序,其中节点代表任务,边代表任务之间的依赖方向,且不存在循环依赖,这样可以保证任务按照正确的顺序执行。
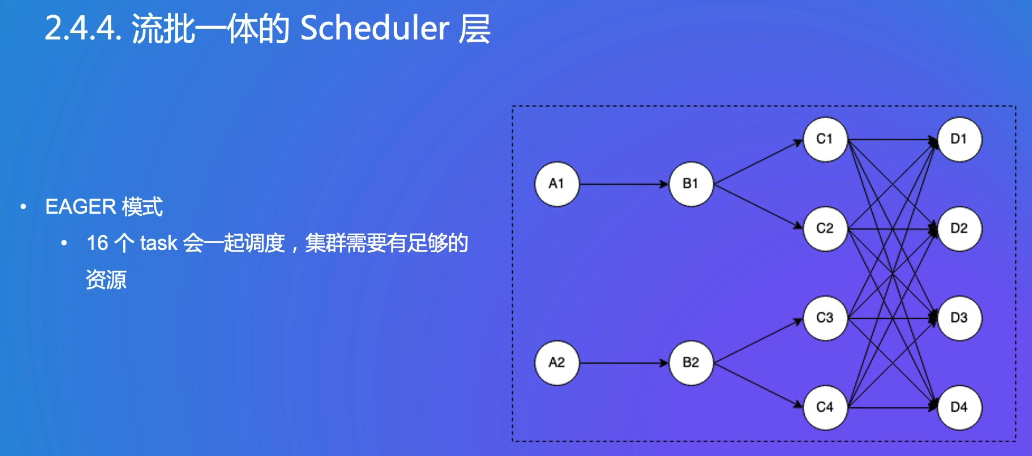
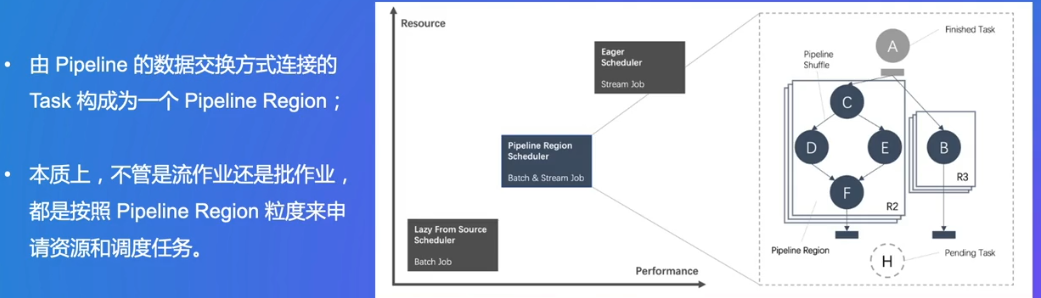
EAGER:流场景,一个作业需要全部的资源
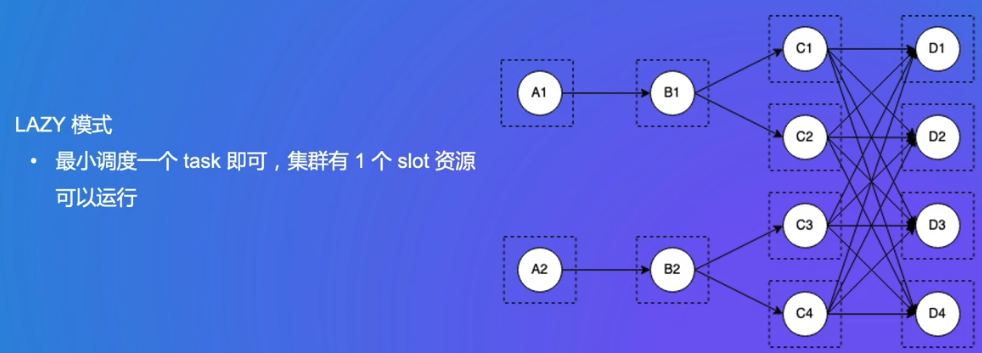
LAZY:批场景,先处理上游,处理完后资源会释放掉

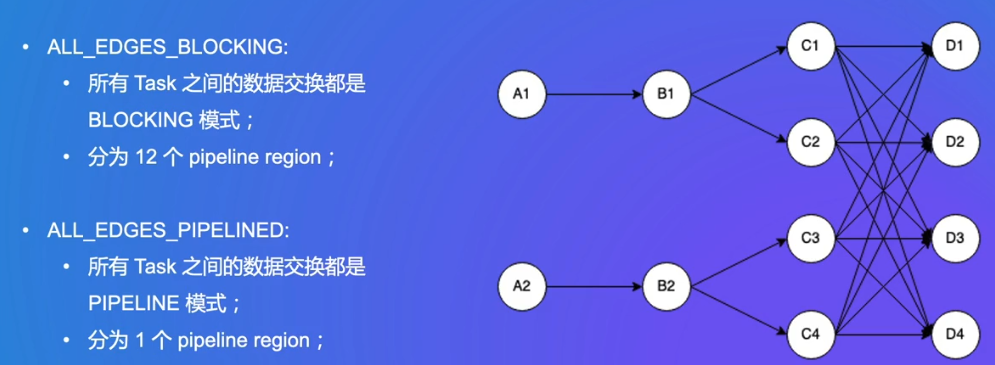
哈希Shuffle
需要12个任务的资源全部拿到后,才能开始工作
因为A1数据是有可能结束的(和流不同),所以可以一个个工作,复用资源
上文是1.12版本之前,下文是最新的调度机制:
BLOCKING:A1的数据会写入磁盘,不是实时传给B1,B1再从磁盘拿,实时性不强,用于批处理
pipeline region:如果有BLOCKING,则认为是2个pipeline region
PIPELINED:用于流处理,数据没有中间被存储下来,性能高
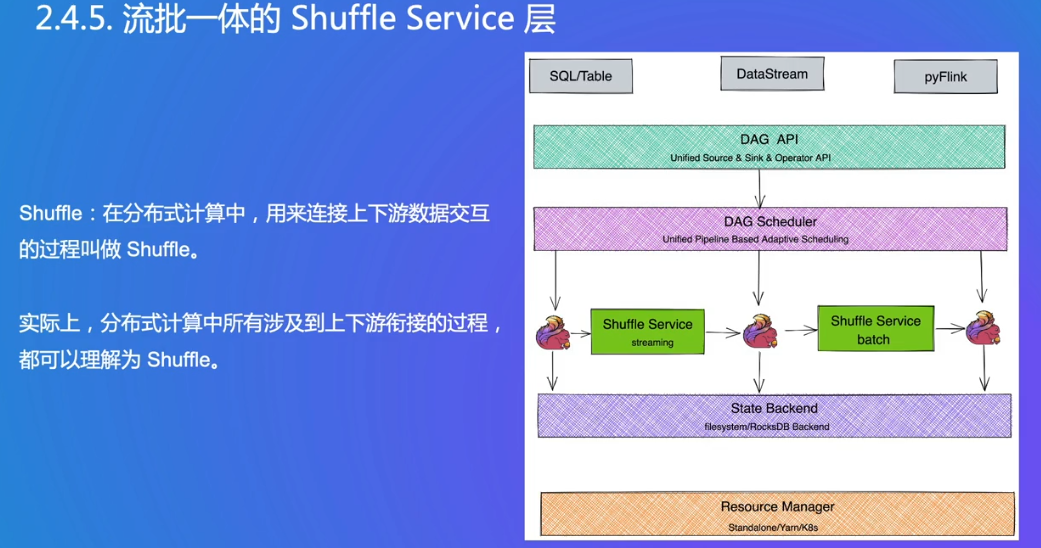
Shuffle
用于连接上下游数据交互的过程是Shuffle
A->B,B->C,C->D,只要是涉及上下游衔接就叫Shuffle

流作业的Shuffle和Task是绑定的,因为Shuffle存在内存钟,而批处理的数据存在磁盘里面了
机器挂机了后批处理重跑的代价高,所以批处理数据有时会复制几份

Flink提出了满足两个模式的Shuffle架构


3. Flink 架构优化与项目实战

抖音红包:如红包雨的数据可以决定下一场红包雨的时间
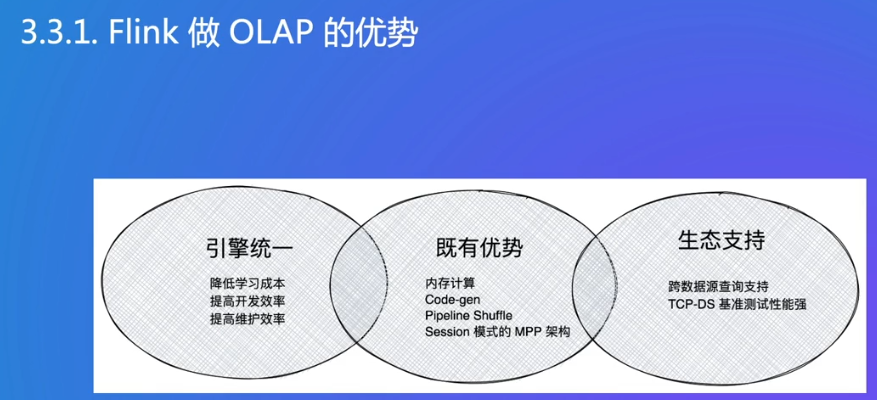
OLAP需要高并发

OLAP是特殊的批处理
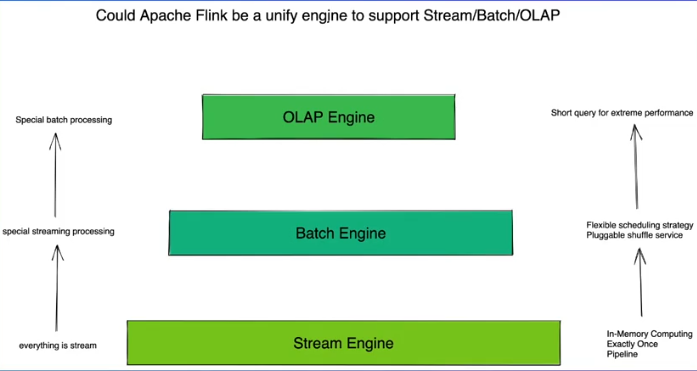

Flink支持OLAP

Flink可以从很多数据源读取数据
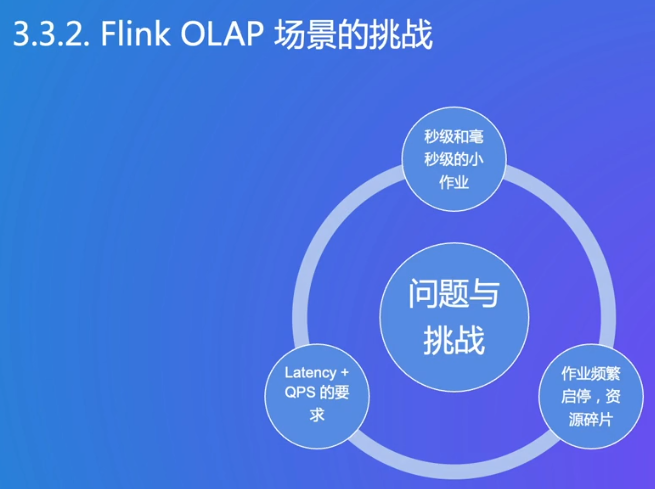
挑战:面向s级,还要高并发,频繁申请内存和磁盘如何处理
QPS:并发调度和执行能力
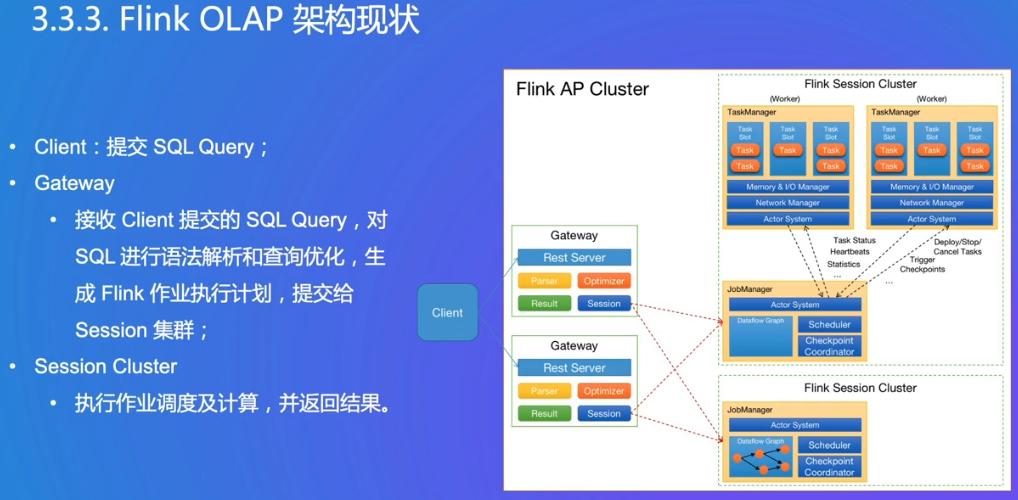
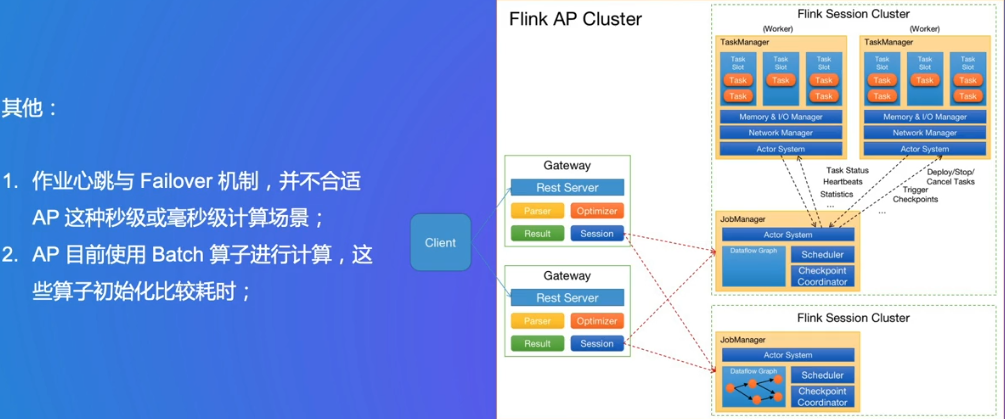
Gateway:和前文Flink Client有点像,给SQL语法解析优化,然后生成DAG图
Session Cluster:
- Per-Job模式的集群,一个集群只运行一个作业,作业执行完毕则集群销毁。
- Session-Cluster模式的集群,一个集群中运行多个作业。
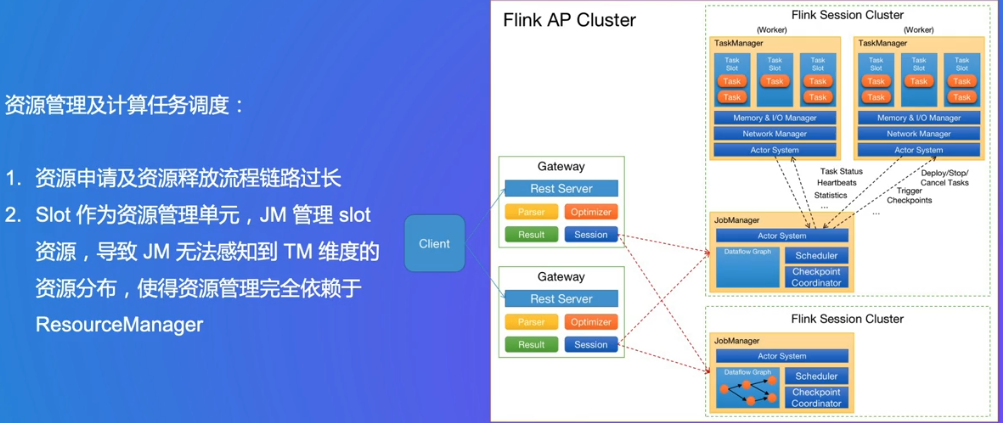
OLAP场景的难点
一些字节内部的设想与提升方向:


总结:
使用案例


希望把流批变成一体,而不是现在分开
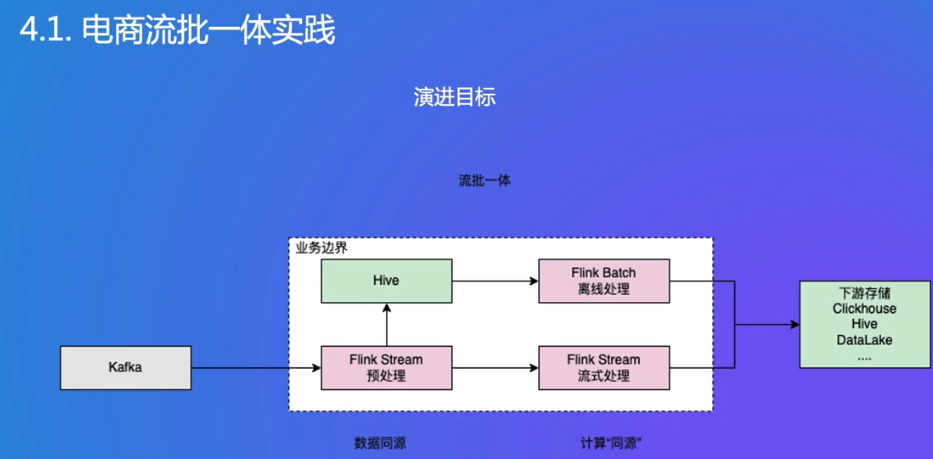
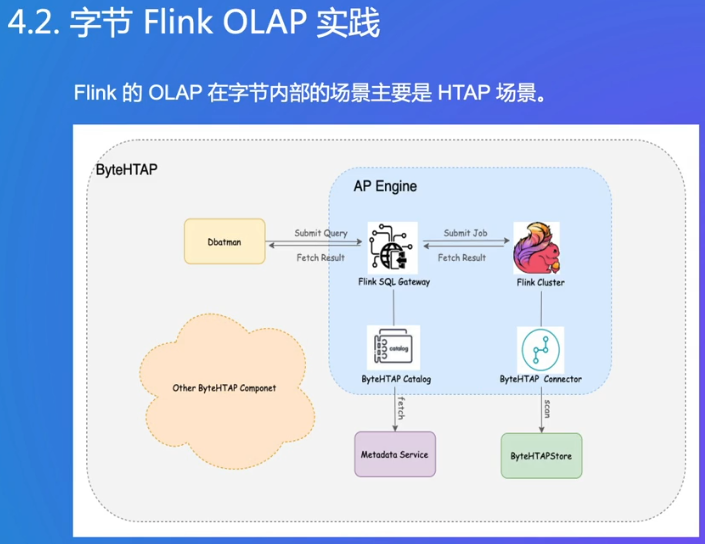
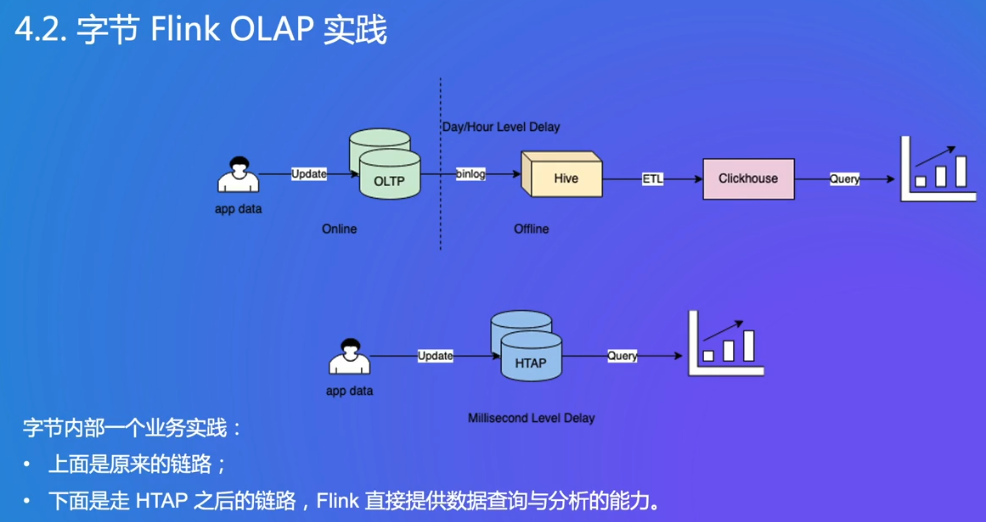
- OLTP(联机事务处理,Online Transaction Processing):主要用于处理日常的、高并发的事务性操作,像电商系统中的下单、支付,银行系统中的转账等。图中 app data 对 OLTP 进行 Update 操作,就是典型的联机事务处理场景,注重数据的实时性、一致性和事务完整性。
- Hive:是基于 Hadoop 的数据仓库工具。可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 的查询功能(HiveQL),用于处理大规模的离线数据。图中 OLTP 通过 binlog(数据库二进制日志)将数据传输到 Hive,之后经过 ETL(Extract,Transform,Load,即数据抽取、转换和加载)处理,再存入 Clickhouse 进行查询分析,体现了 Hive 在离线数据处理流程中的作用。
- HTAP(混合事务分析处理,Hybrid Transactional/Analytical Processing):融合了 OLTP 和 OLAP(联机分析处理)的功能,既能处理事务性操作,又能进行实时分析。图中走 HTAP 之后的链路,相比原来链路减少了中间环节,Flink 可以直接基于 HTAP 提供数据查询与分析能力,且延迟达到毫秒级,大大提升了数据处理和分析的效率 。
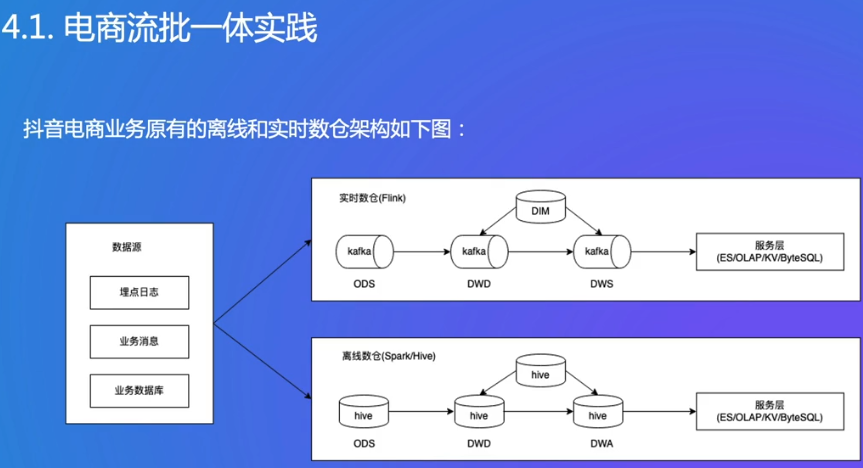
以前在线和离线是完全分开的,Hive是离线的数据仓库,小时/天级别的延时
现在查询、分析都能在HTAP中,秒级别,很快

3. Exactly Once语义在Flink中的实现
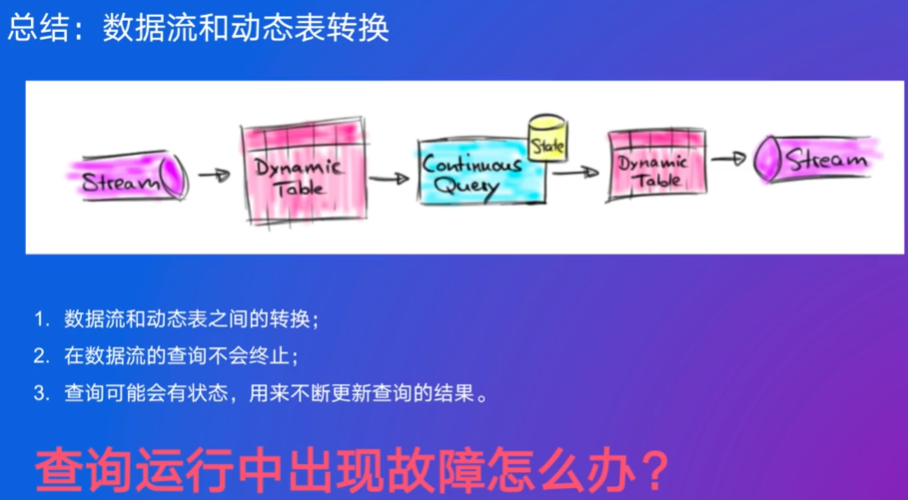
1. 数据流和动态表

端到端的exactly once是什么

流是无限的,不能被完整访问
传统批处理的处理时间一定是可以终止的,流查询是永远不会终止的

表和流可以动态进行转化
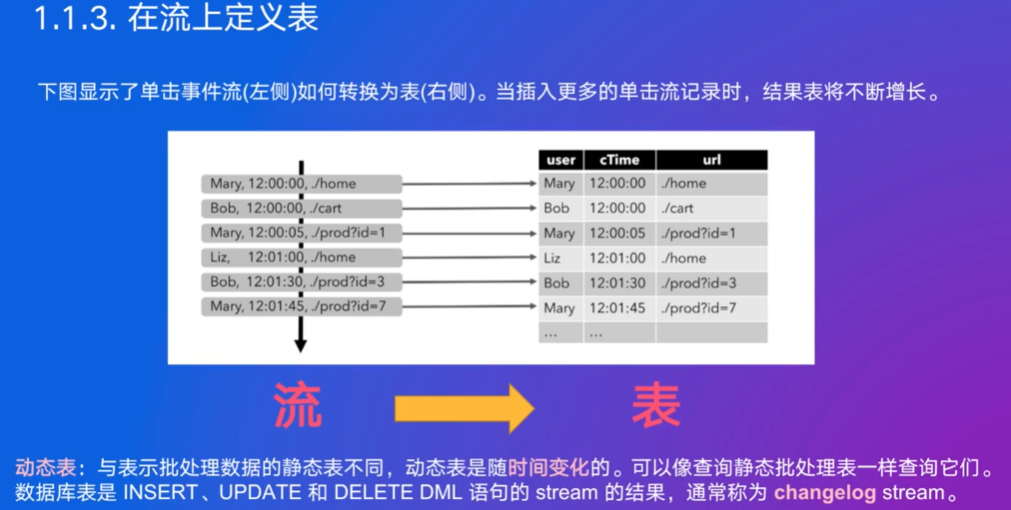
查询的语义跟批处理完全一样(相当于某一刻时间静止),只是一直在进行连续查询,不会终止
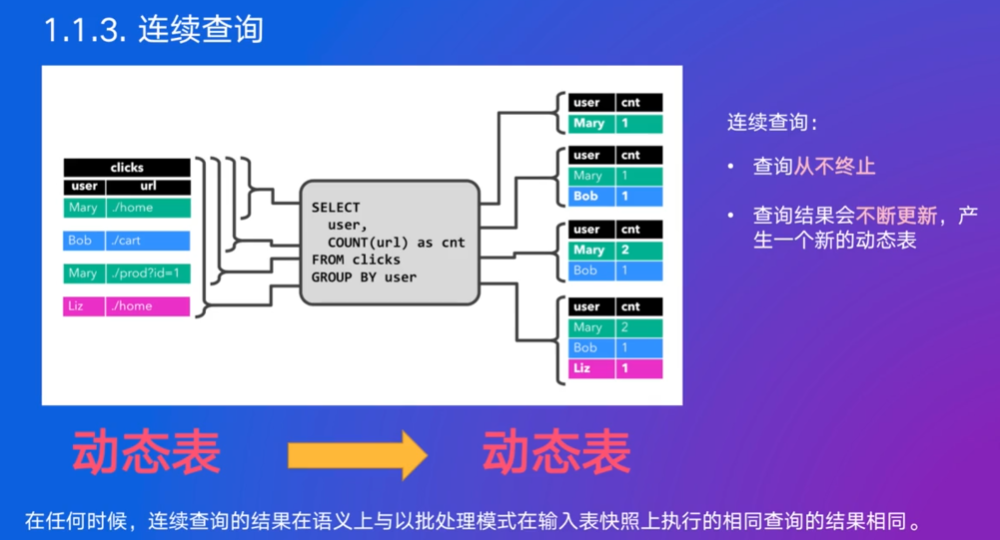
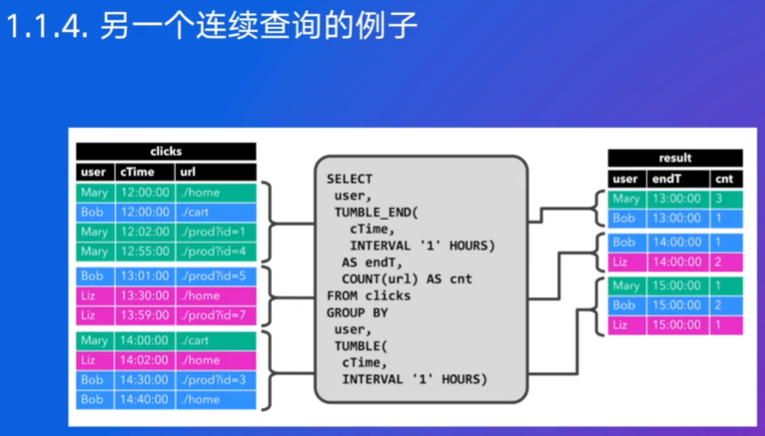
第一个sql统计用户在网站查询的所有次数,第二个统计用户在每个小时段内的点击次数

Mary点击1次,后面又有,下游要更新,如何?发retract进行回撤,再发更新后的消息Mary,2
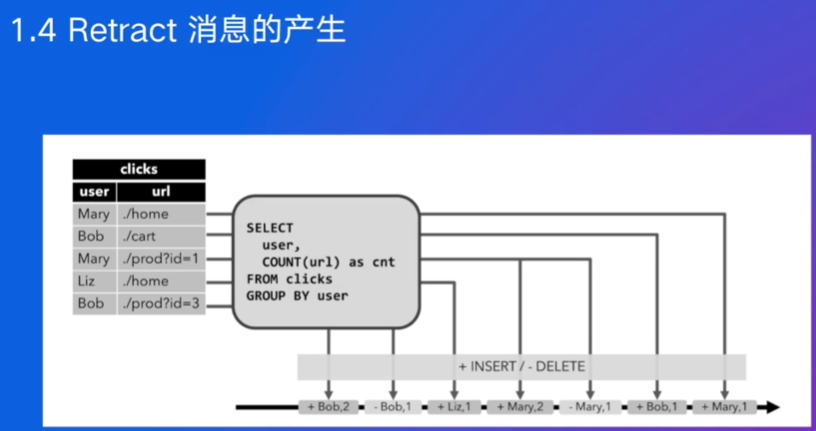
SQL连续查询时会建立clicks的数据表,作为状态保存中间计算结果,当新的数据到来时就可以更新
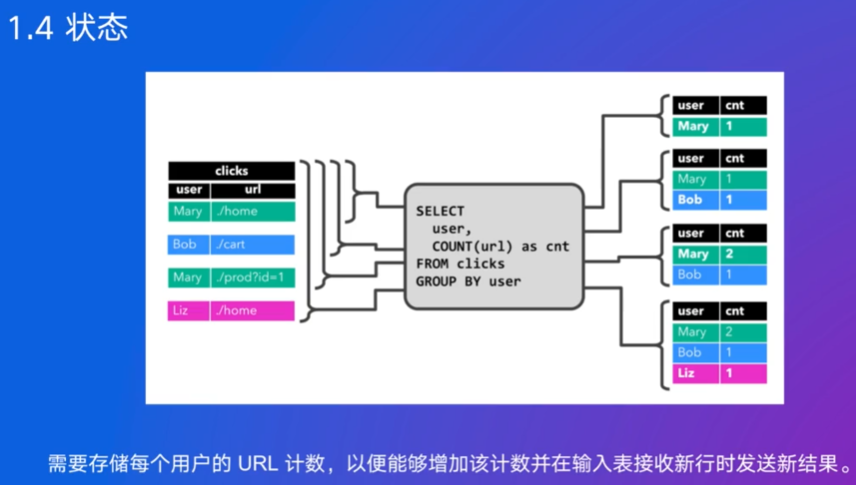
查询结果是动态变化的
消费:从消息队列或流式数据源中读取并处理数据的过程。消费者(Consumer)是负责执行这一过程的实体,它们从生产者(Producer)发送的数据中提取信息,并根据需要进行处理、分析或存储。
At-most-once:出现故障时啥也不做,下游数据可能丢失,可以保证所有时间都处理数据流,时延最低,对数据准确性不高就可以用
At-least-once:虽然存在数据重复处理的风险,但它确保了数据不会丢失。这种语义适用于可以容忍少量数据重复,但不能接受数据丢失的场景
Exactly-once:提供了最高的数据处理准确性和一致性,但实现起来相对复杂,通常需要结合状态管理和一致的检查点机制。

2. Exactly-Once 和 Checkpoint
设置状态保存的时间点作为故障恢复点进行备份,如果有故障回退到此刻
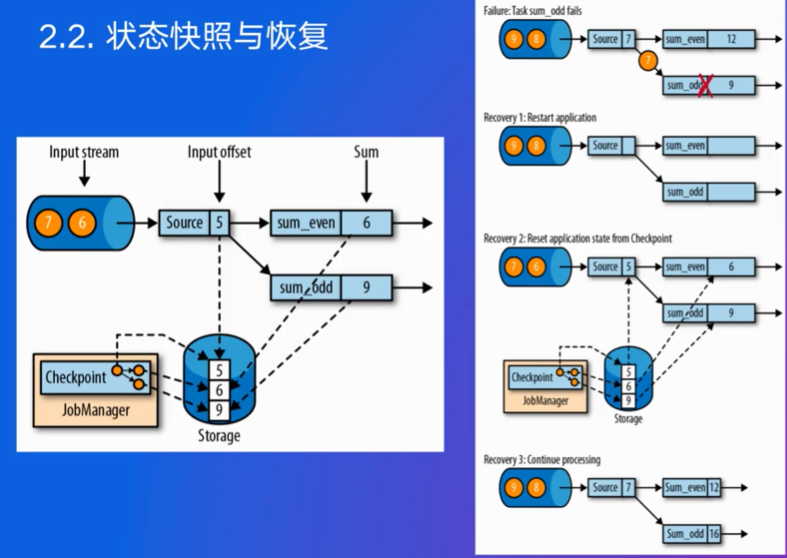
- sum_even和sum_odd分别负责计算偶数和奇数的总和
- Recovery 1: Restart application 如果直接重启应用而不使用检查点,那么sum_odd任务会丢失之前的状态信息。在这种情况下,当新的数据到来时,sum_odd将从零开始重新计算,这会导致数据不一致。
- Recovery 2: Reset application state from Checkpoint 利用检查点进行恢复。JobManager从最近的检查点加载状态信息,并重置所有任务的状态。这样,sum_odd任务可以恢复到故障前的状态,继续处理数据。此时,sum_odd的值仍然是9,而不是从零开始。
- Recovery 3: Continue processing 恢复完成后,系统继续处理新的数据。例如,当新的数字8到来时,sum_even将其累加到当前值上,得到12;而sum_odd则保持不变,因为8是偶数。最终,当另一个奇数到来时,sum_odd将继续累加。
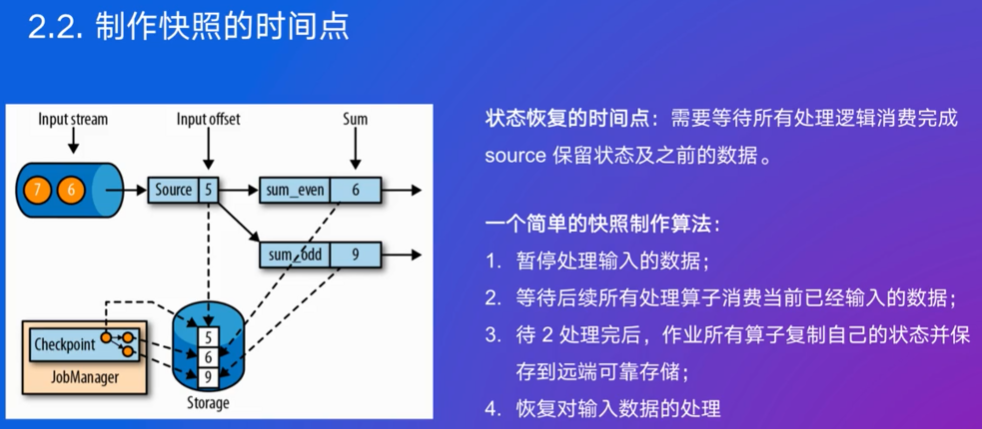
时间点不能选择任意的时间点,要等到所有处理逻辑消费完成
这个算法要等所有逻辑消费完成,效率差,所以提出Chandy-Lamport算法
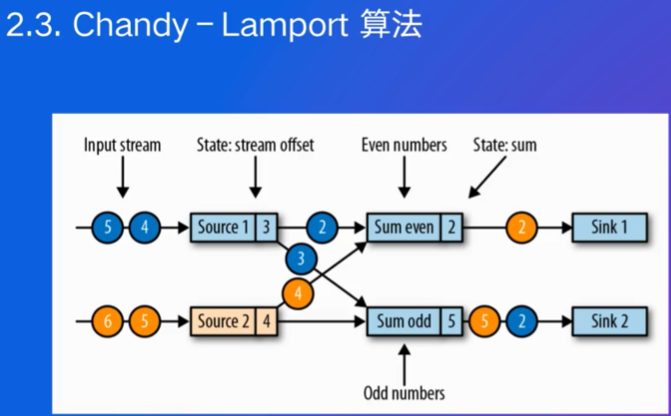
Chandy-Lamport算法
两个source,并行独立处理各自的数据,统计偶数累加和和奇数累加和
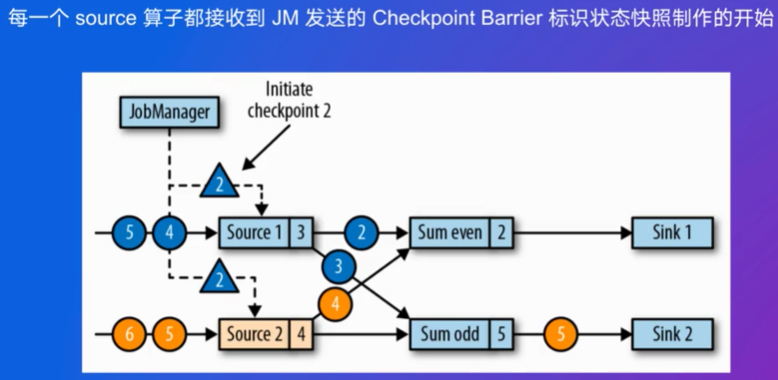
JM会往下游发送Checkpoint Barrier,将数据流分割成多个部分,这些部分代表了不同检查点周期的数据。
当一个算子(Operator)从其输入流接收到barrier时,它不会立即继续处理后续的数据,而是等待从所有输入流接收到对应于同一检查点的barrier。这意味着该算子会暂停处理位于barrier之后的数据,直到所有的输入流都达到了相同的检查点边界。
一旦所有输入流的barrier都已经到达,算子会触发自己的状态快照操作,将当前的状态保存下来。这个状态包括所有中间计算结果,如聚合值或窗口内容等。完成状态快照后,算子会向下游发送barrier,允许下游算子也执行相同的过程。这确保了整个作业图中的所有算子都能同步地创建一致的状态快照。
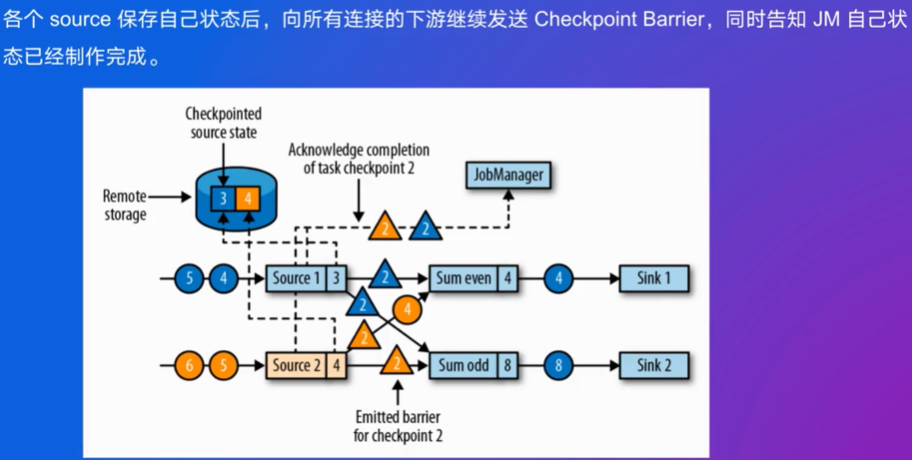
在所有必要的状态快照完成后,算子将继续处理那些被暂时搁置的数据记录,即位于barrier之后的数据。
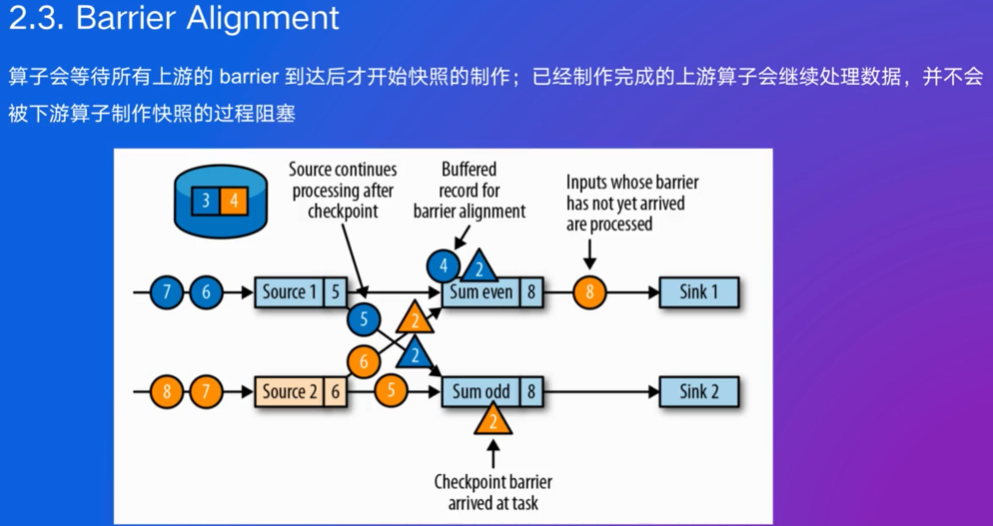
barrier下发后就可以数据处理了,barrier和数据处理是解耦的
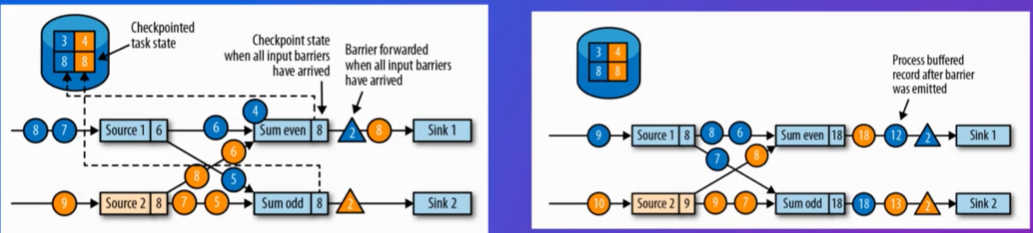
所有算子的状态都保存好了
异步将快照保存到远端
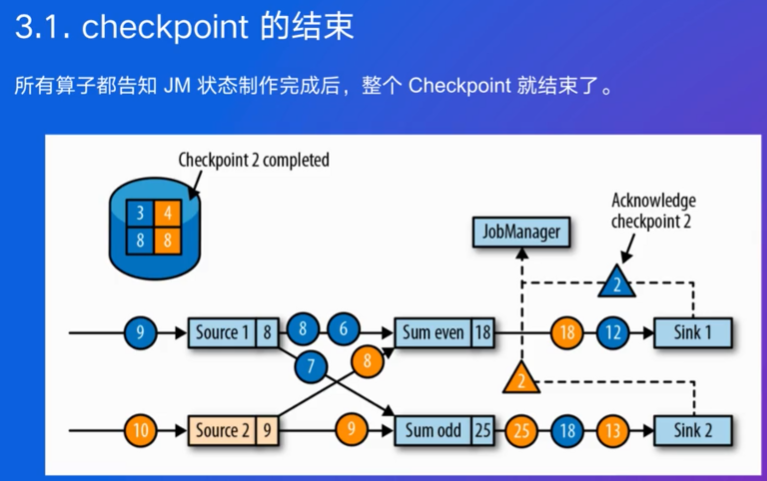
用Checkpoint保证故障发生时有exactly once,保证数据只被消费一次

3. 端到端 Exactly-Once 实现
sink是往下游发数据的,恢复的时间这段时间sink会重复下发,这是不对的,如银行重复存储

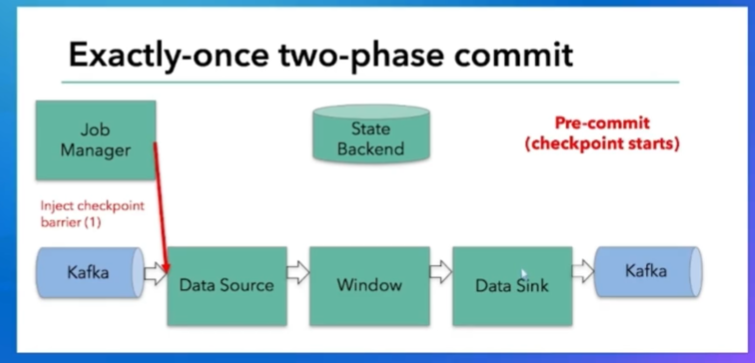
两阶段提交协议:分布式协议
事务性(原子性):要不全部执行操作,要不全部不执行

预提交阶段:没有真正提交

提交阶段:

协作者:管理和统筹所有协议
参与者:参与决策
Kafka:2维数组,有序,无限长,从头读数据,新数据存入尾

第一步:协作者告诉参与者要准备提交了,类似checkpoint barrier,状态制作的开始
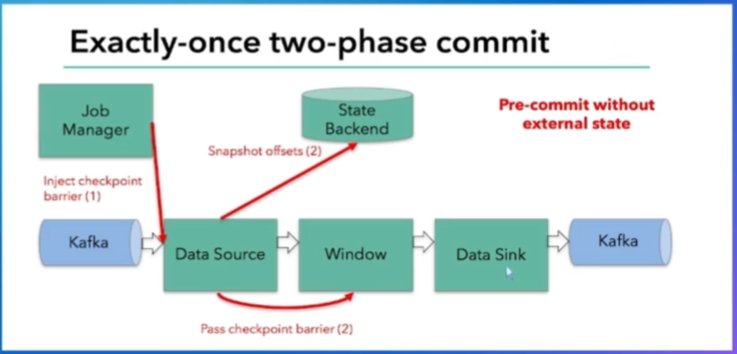
第二步:告诉剩下的参与者要准备提交
提交结束后,向JM说提交完成了,JM再发说所有节点提交成功了
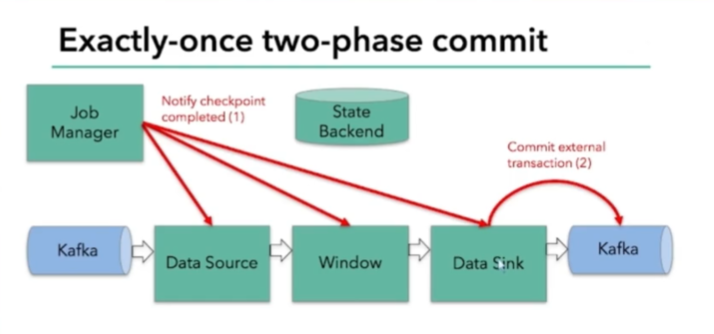
有一个算子失败,就会回滚
一旦有延时和数据慢,会堵塞,要避免

4. Flink 案例讲解
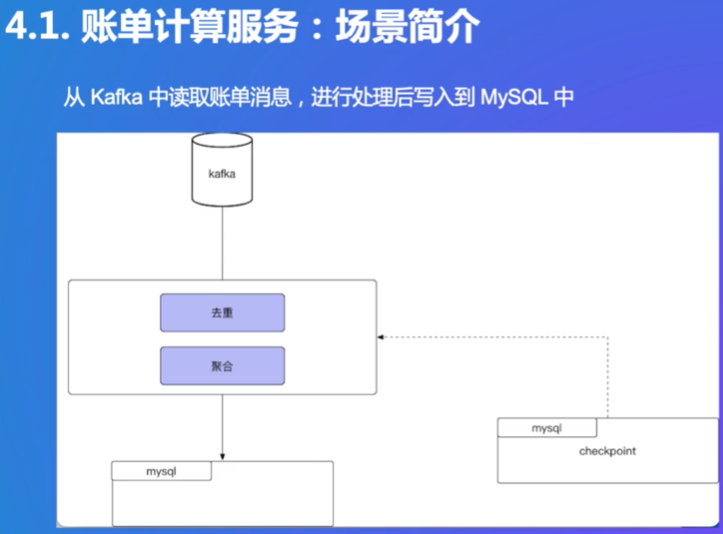
简单实现的Exactly-Once:
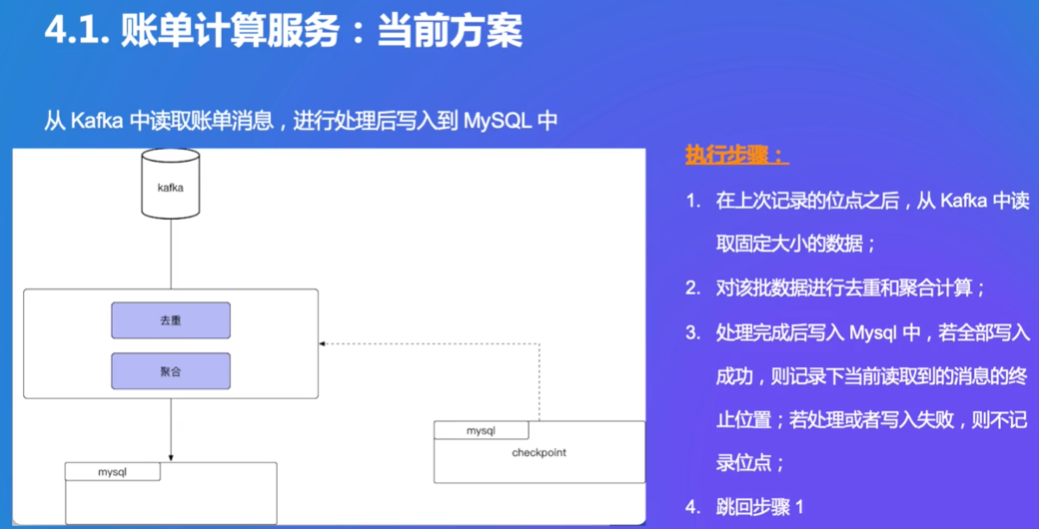
问题:实际上是At-least-once

用Flink解决以上问题,实现严格的端到端Exactly-Once


4. 流计算中的Window计算
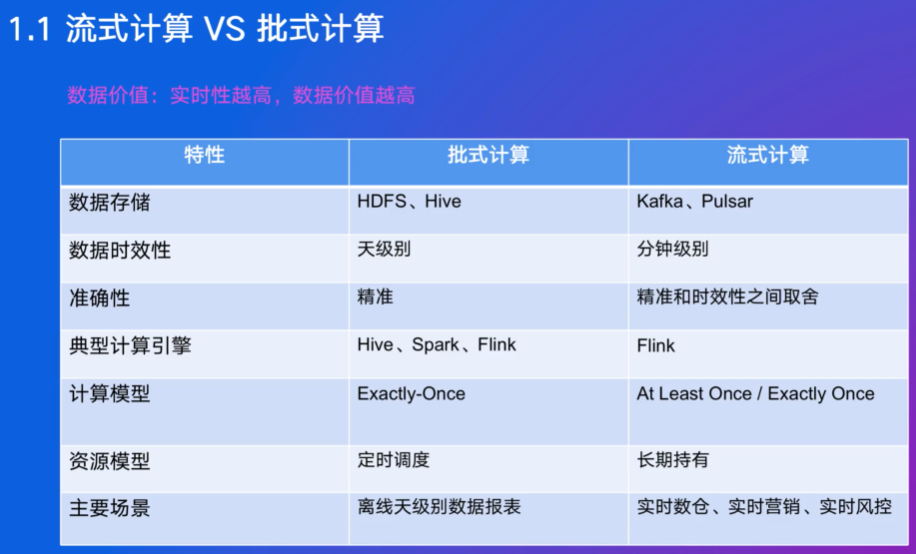
1. 流式计算的概述
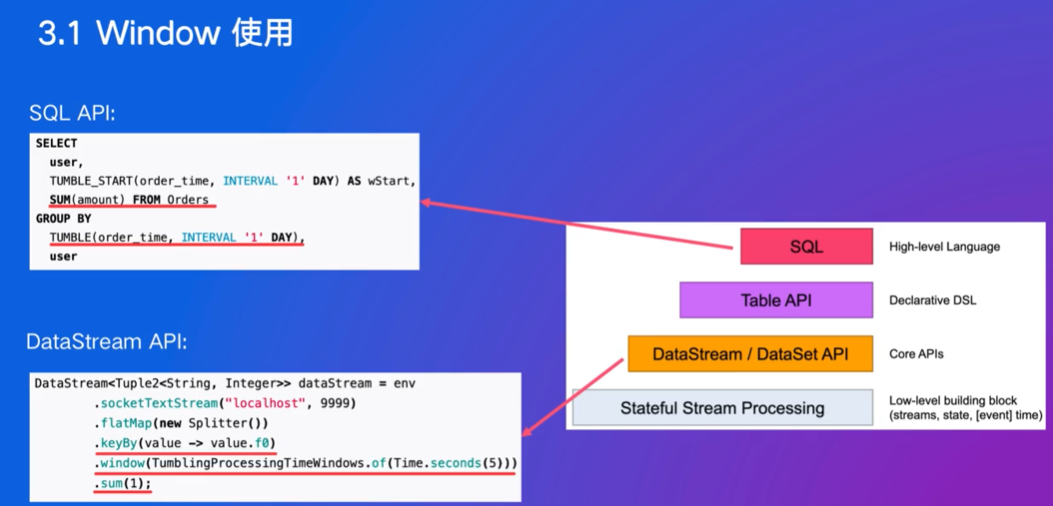
SQL是主导,Flink在字节也用的非常多
企业数仓围绕Hadoop,每天凌晨准备好数据,以天为单位,流式计算是以秒为级别
资源模型:指使用的计算资源是什么,批跑完任务就结束了,所以是定时的,流的计算资源是长期使用,没有释放和申请,一直在使用
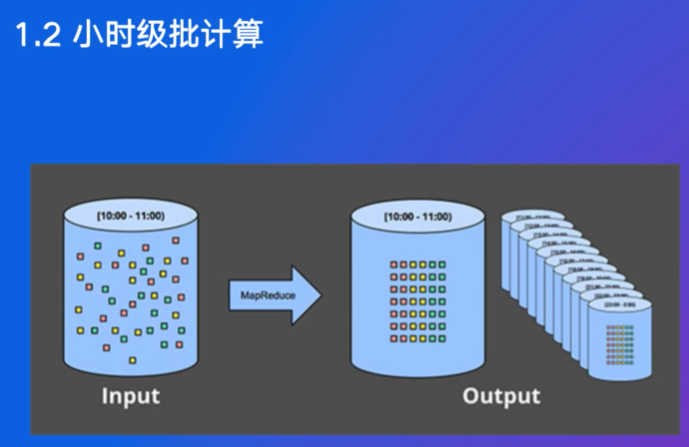
如何更实时?从天变成小时,技术上没问题,申请/释放的周期调度需要资源,数仓需要分层,数据产生到计算完成有时在1小时做不到

时间窗口:数据进来就直接计算,时间结束就下发数据

引入Watermark:表示数据处理到哪里了,表示窗口结束


2. Watermark 基本机制概述
对比机器时间:现在是10:30,但真实事件时间可能是昨天

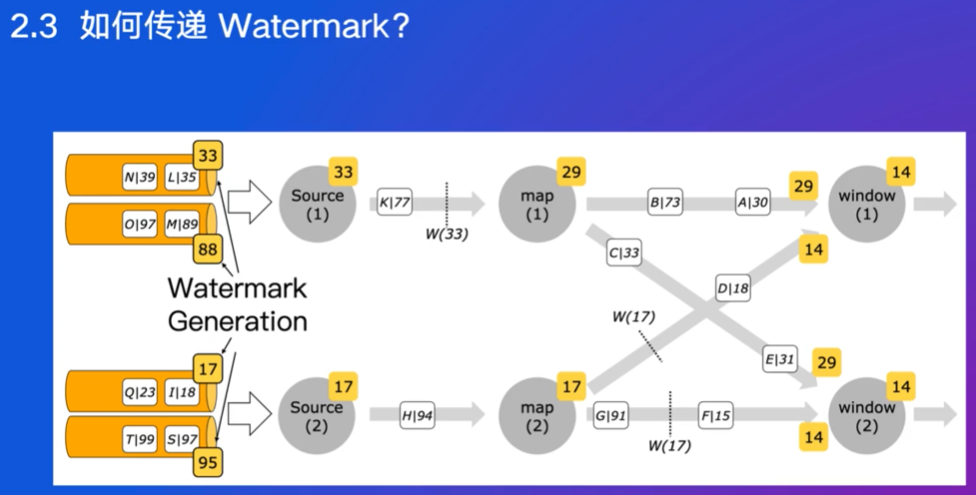
从原始时间-5s/-20s作为Watermark,表示事件时间

33会传递W(33)给29
window1取上游传递数值的最小值,也就是14
Flink应用有数据输入,没有数据输出:很有可能是Watermark不正常

上图一个source消费两个partition,多个partition可能加重乱序
新版本取最小值,解决问题

白天有数据,晚上没数据,让断流了怎么办:设置超时时间,忽略这个subtask

迟到数据:晚于watermark


3. Window 基本功能和高级优化
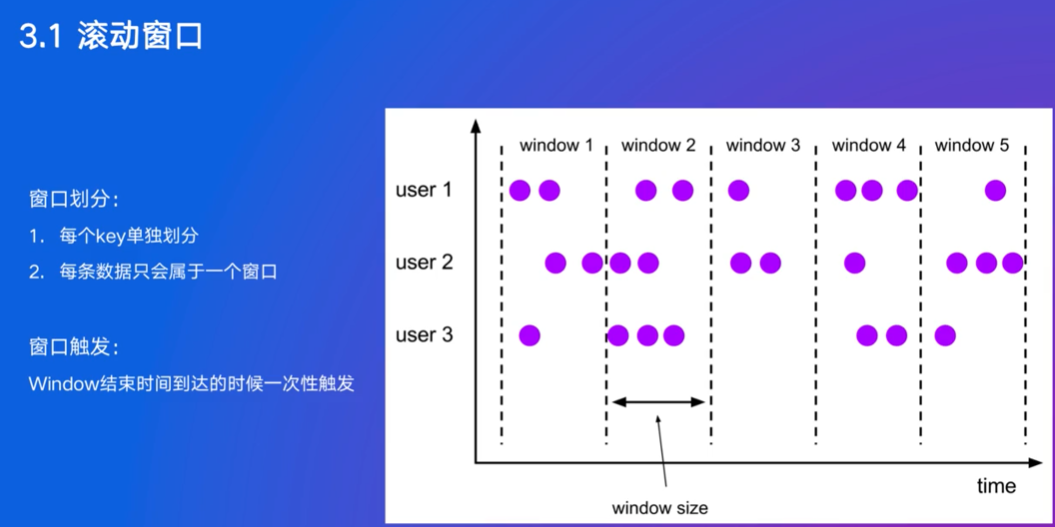
窗口的目的:将无限流数据划分为有限块、支持基于时间或数量的聚合操作
累计窗口:如0-1点累计是多少

SQL大部分的算子是自己优化过的,并不是直接用window
图里有14个窗口,3有4个,12有5个
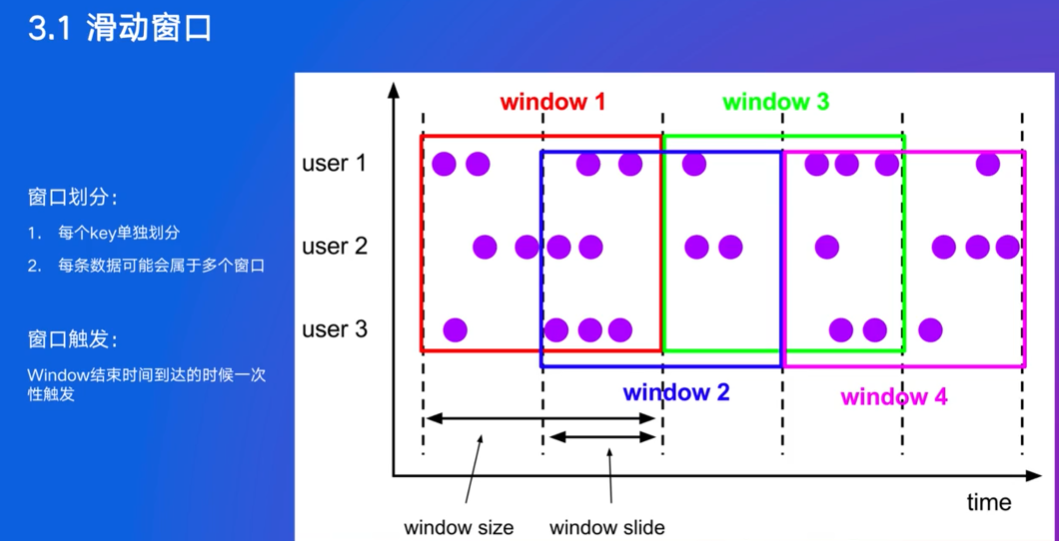 前面两个窗口是根据时间划分的,会话窗口不是,并不确定数据所处的窗口,划分是动态过程,可能与其他数据合并
前面两个窗口是根据时间划分的,会话窗口不是,并不确定数据所处的窗口,划分是动态过程,可能与其他数据合并
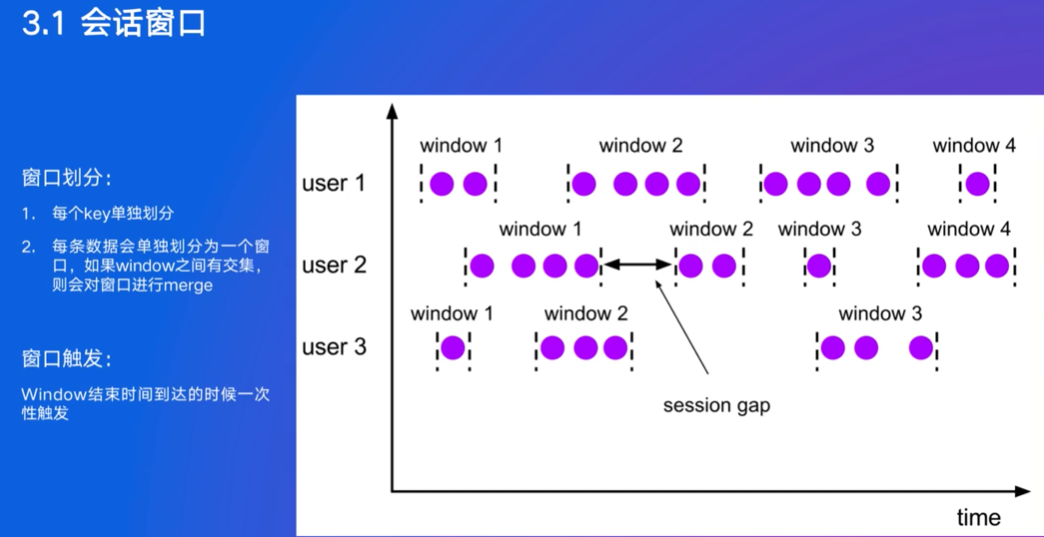
迟到数据:只有事件时间才会迟到,来了就算的模式不算迟到


增量:每条数据来了就计算,保存的值少一些,如只保留中间结果sum
全量计算:需要大量的缓存,积累一定数据后再一起计算

窗口结束才触发,窗口时间可以设置
EMIT允许中间结果可以输出多次,防止窗口比较大,实时计算慢
FIRE跟案例场景一致,相当于保留中间结果


高级优化
解决中间结果偏多和访问频繁的问题
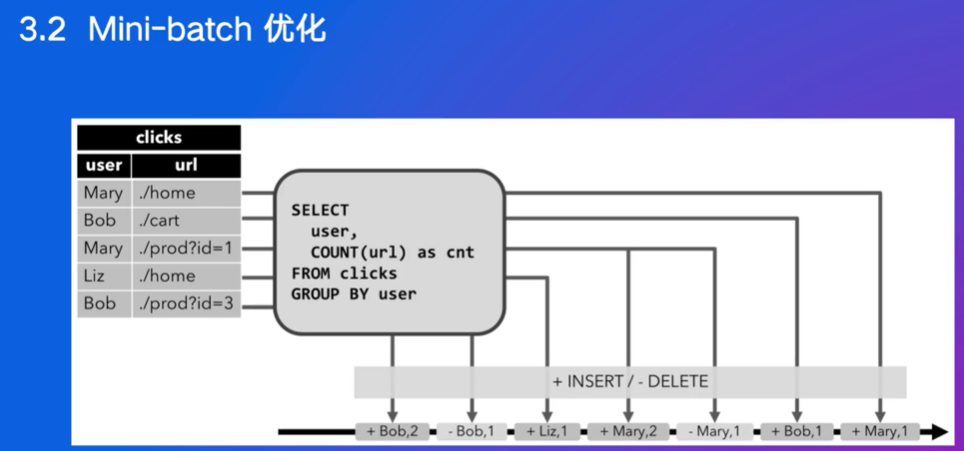
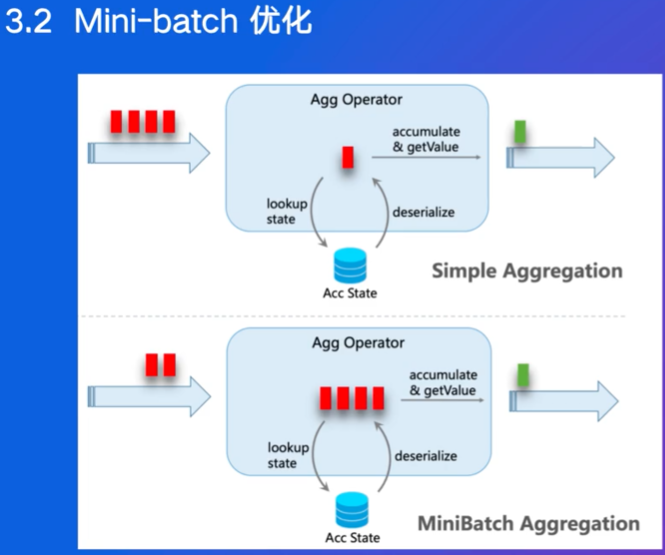
mini-batch:将多条数据打包成一个批次(Mini-batch)进行处理,减少状态操作的频率。
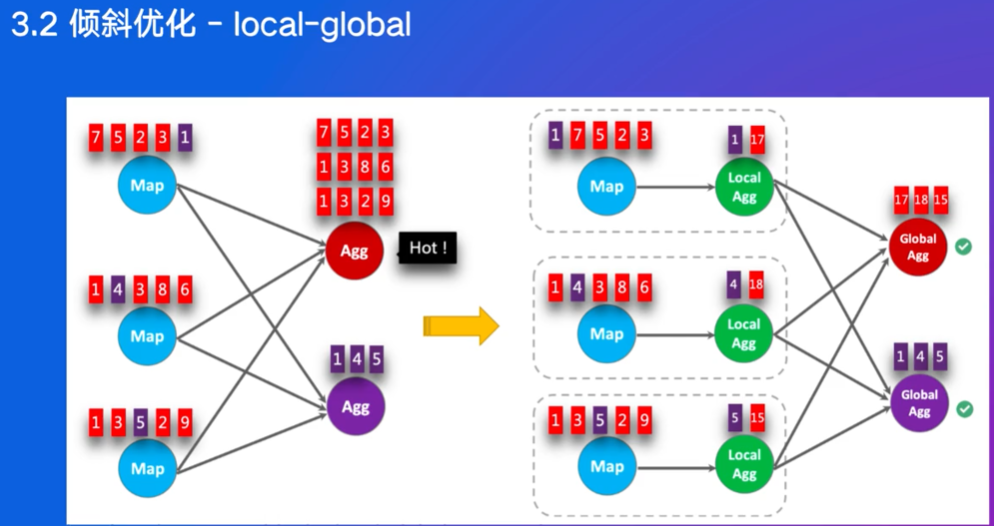
倾斜问题通常发生在数据分布不均匀的情况下,导致某些任务需要处理大量数据,而其他任务则相对空闲,从而影响整体处理效率。
局部聚合会在本地对数据进行初步的聚合操作,减少后续传输的数据量。
- 由于已经进行了局部聚合,每个Global Agg节点接收到的数据量大大减少,避免了单个节点过载的问题。
每个COUNT(DISTINCT item_id) FILTER (WHERE flag IN (…))都需要独立地计算唯一值,这会导致大量的重复计算和资源浪费。
distinct(去除查询结果中的重复记录)有时会优化为group by,而flink有窗口,不能随便优化
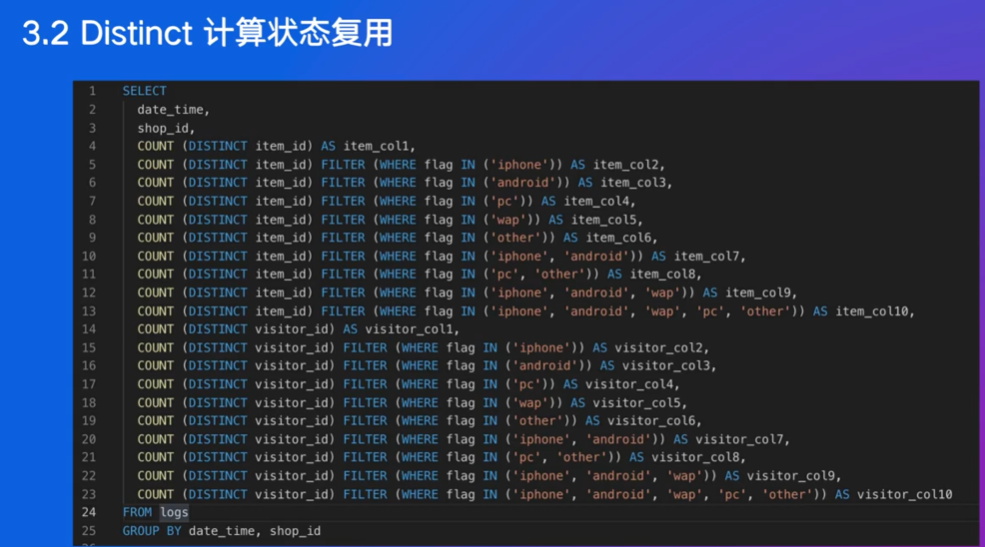
TODO:这里看不懂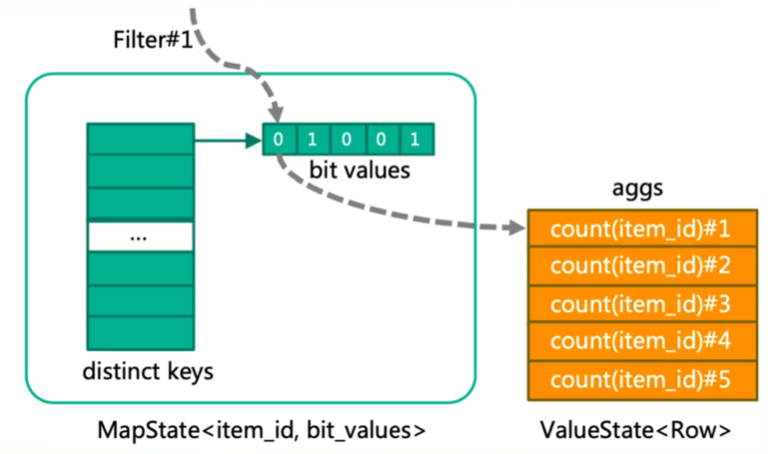
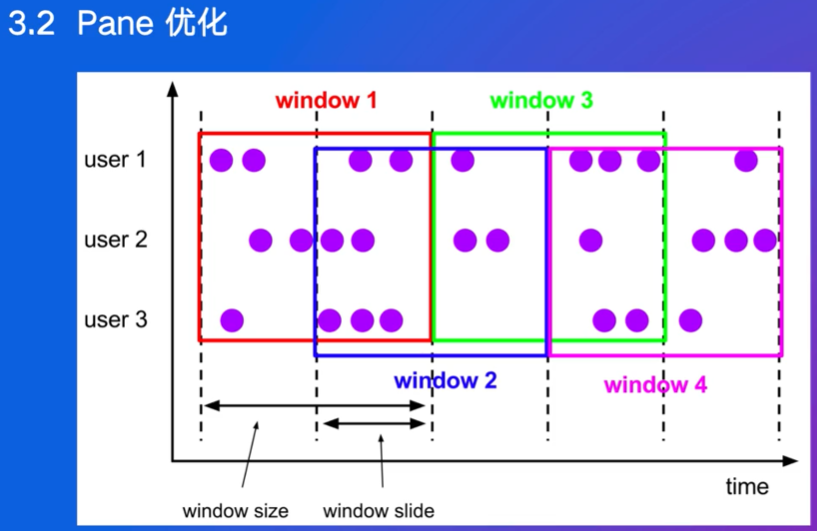
同时属于1和2,开两个窗口,让两个窗口都计算,数据参与2个,这样计算量会大,能否划分成更小的粒度?
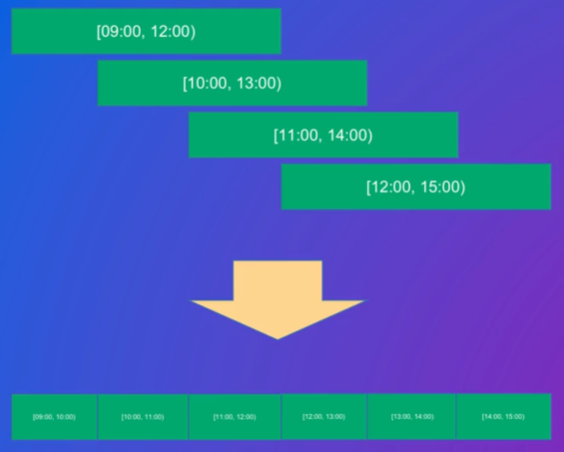

4. 流计算相关案例分析
日活曲线:每个分钟都有点,看从早到晚DAU(Daily Active Users,即日活跃用户数量)的变化过程

思路:滚动窗口,每隔一段时间输出
这个SQL的问题:不能进行全局的聚合

改进:变成2阶段,每个桶进行distinct uid
第一部分聚合后数据量已经小了


大数据任务特指离线计算,尽可能快的在任务结束后拿到资源开销



5. Spark原理与实践
1. 大数据处理引擎 Spark 介绍
云原生方向
存储要选择合适的格式,可以存到HDFS也可以存到Kafka

Spark的几个feature:仪表盘、机器学习



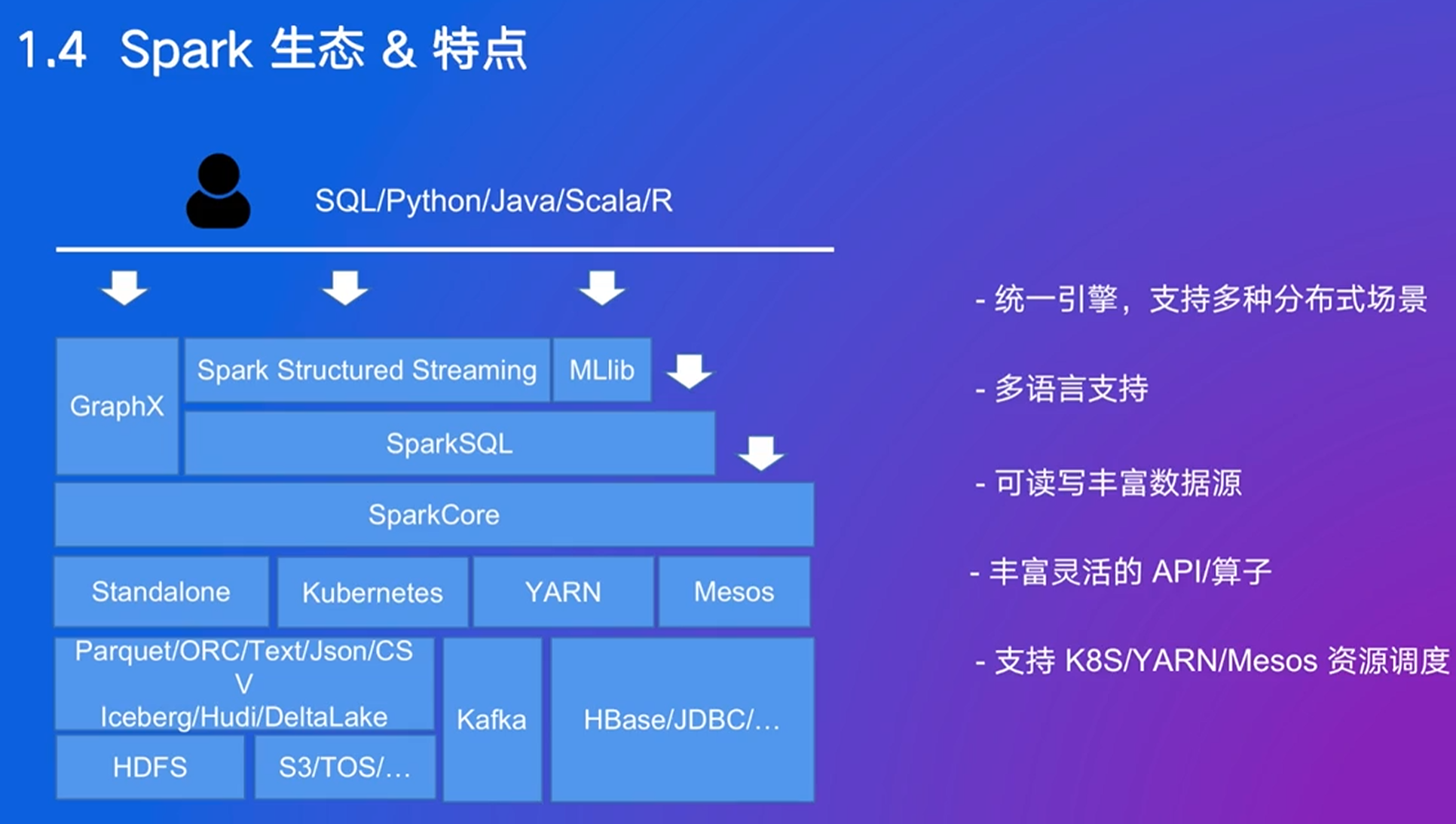
多语言支持,很多的资源调度


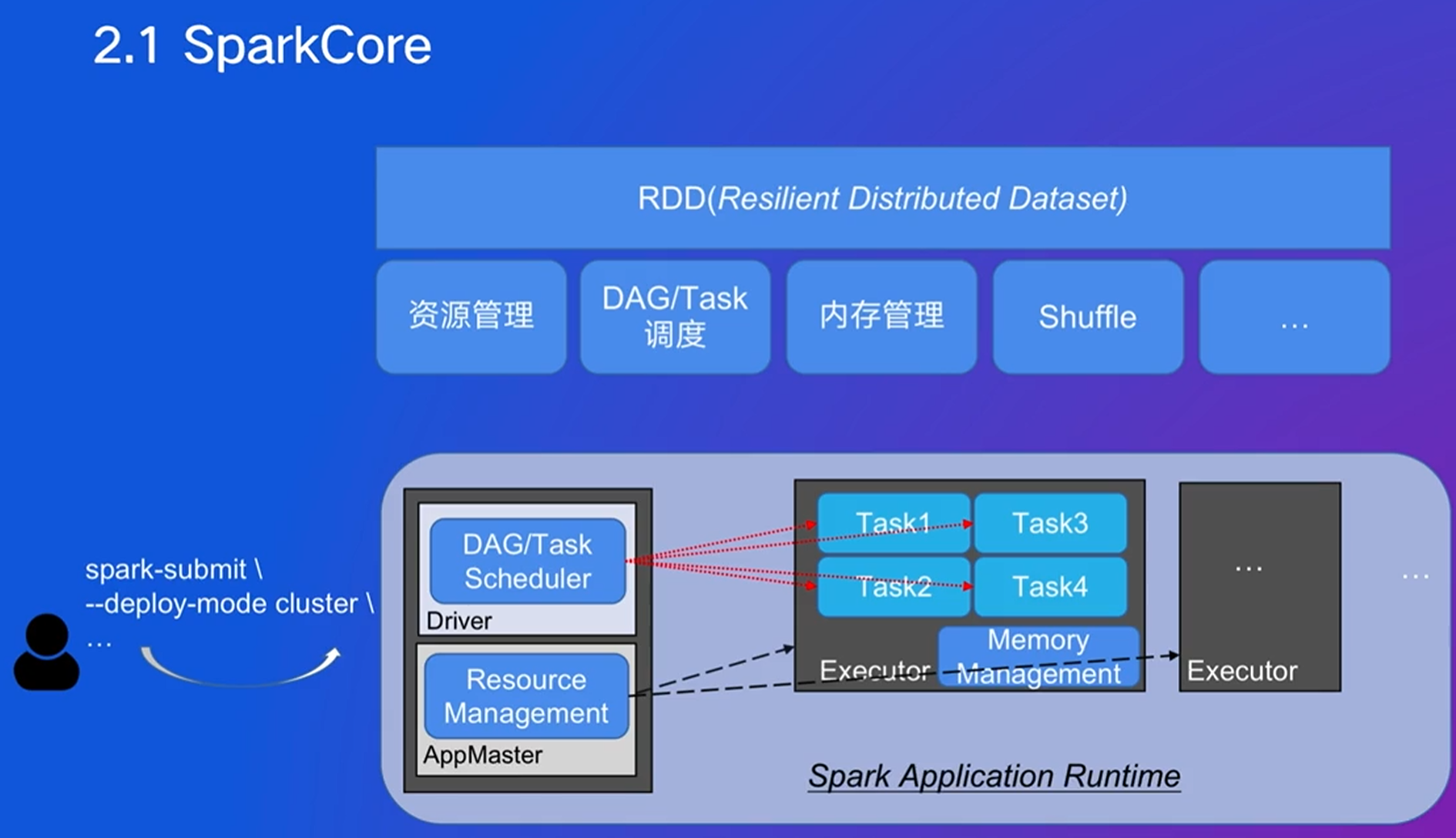
RDD:弹性数据集,对任何函数的计算可以看作一个算子
DataFrame:类似传统的二维表格

CM:监控Worker节点,负责支援调度
Worker:从节点,可称为Node Manager
任务:只有一个Driver
Executor:实际执行任务
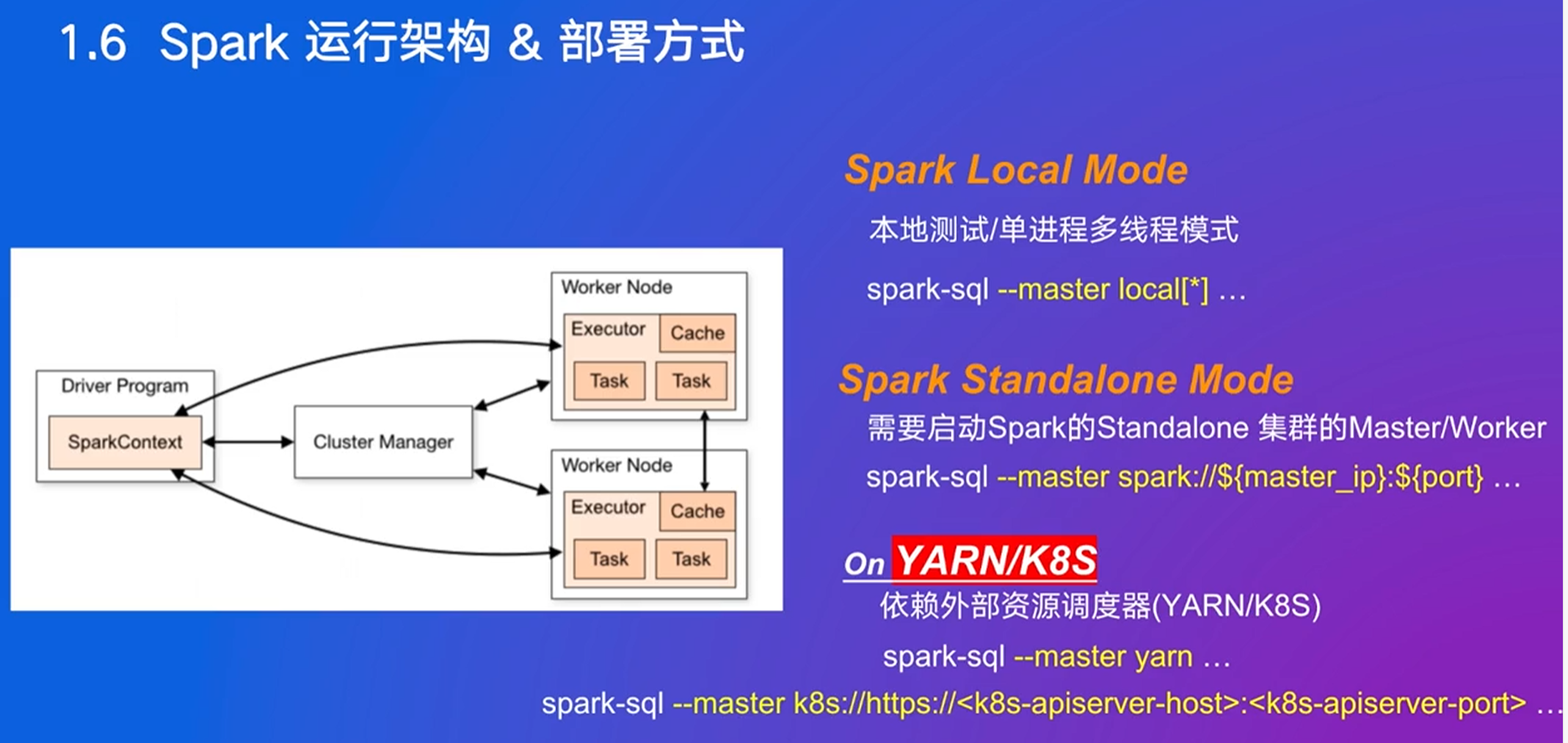
–master表示委托给谁进行资源管理

bin目录有很多提交命令,后面可以跟许多参数

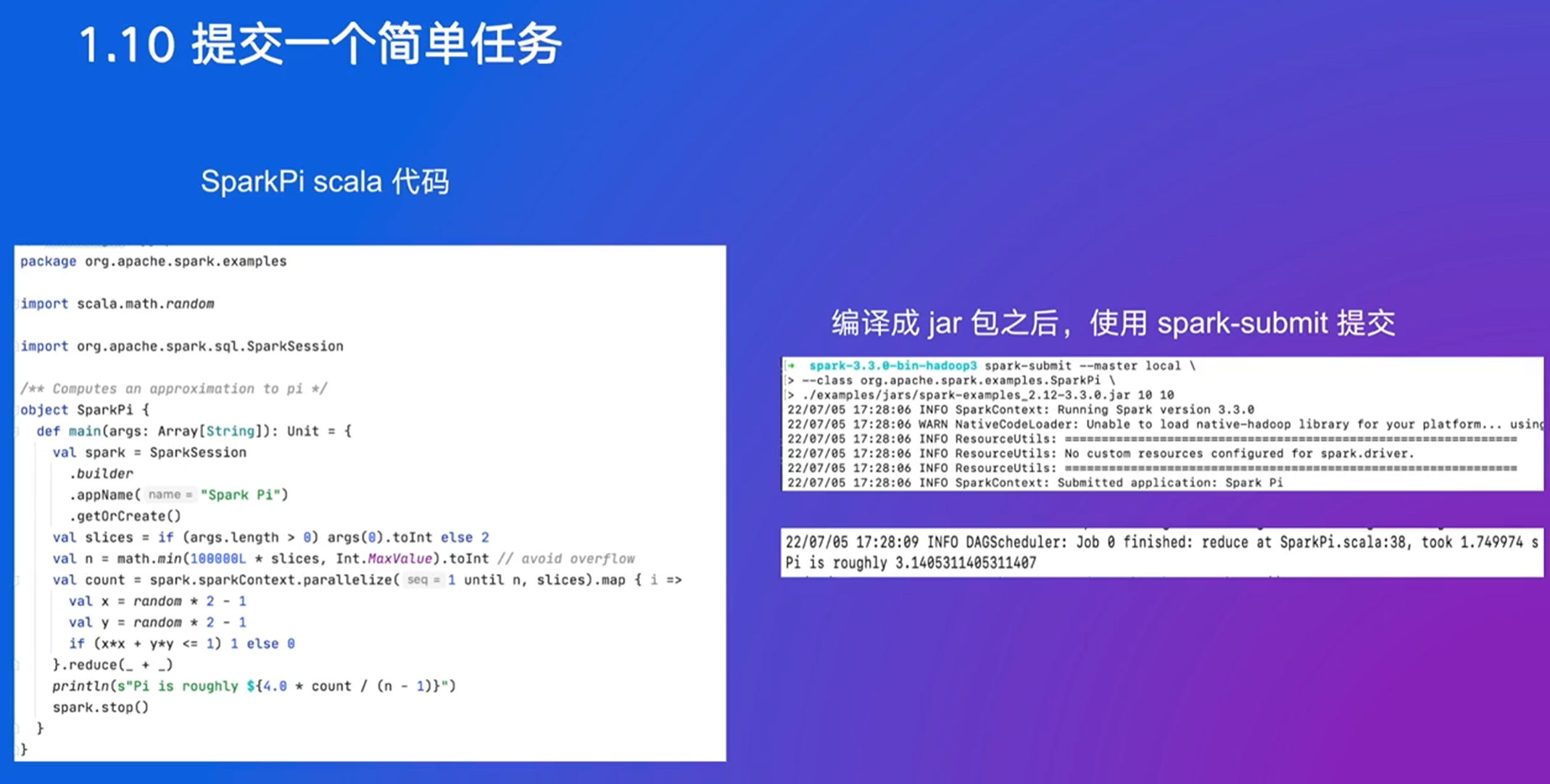
线上时,大部分用Spark scala来提交

2. SparkCore 重要机制解析
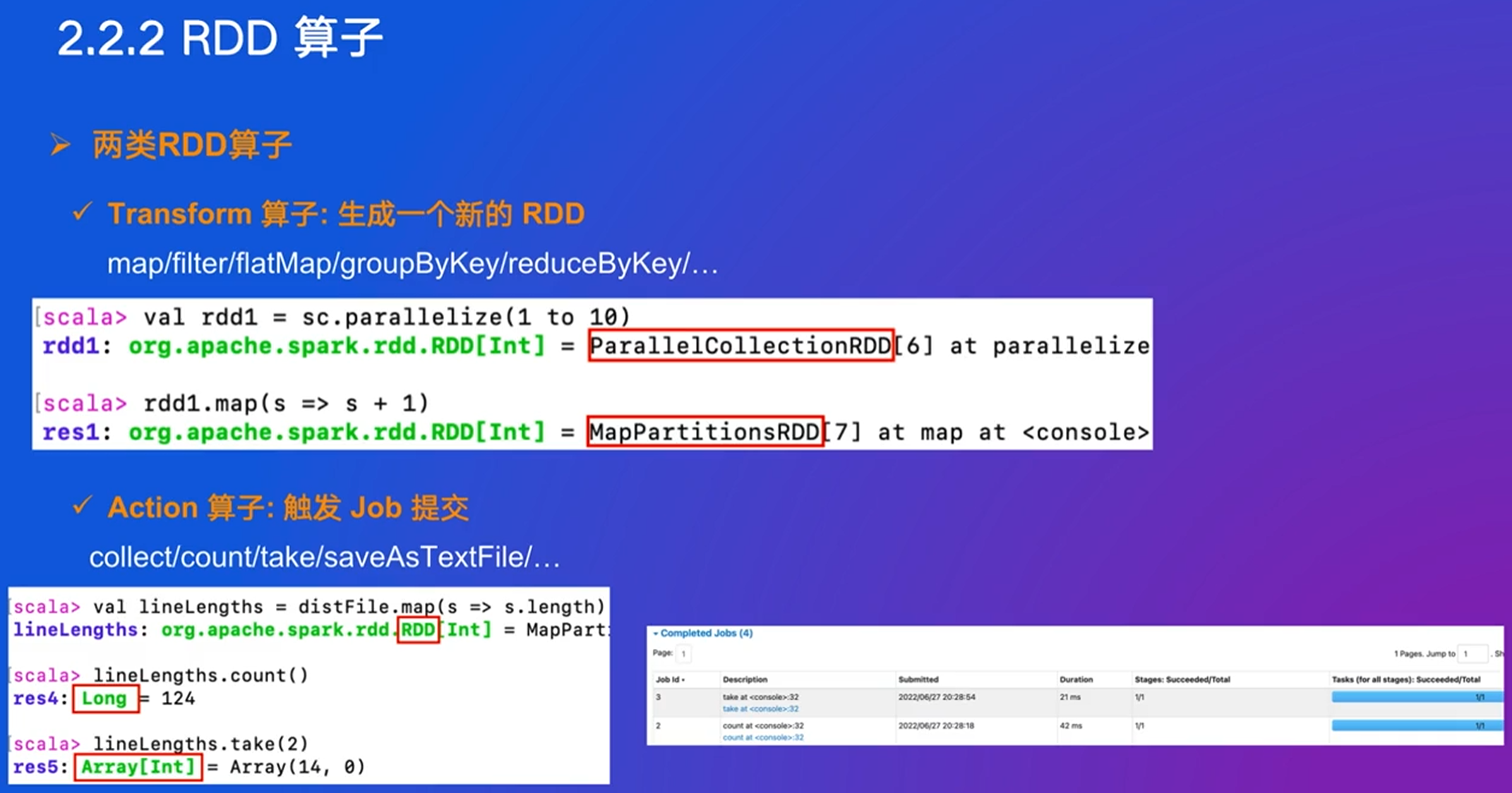
RDD:创建时要指定分区;每个RDD有计算函数;每个RDD依赖别人,像pipeline一样

创建RDD:

窄依赖:父RDD至多对应一个子RDD
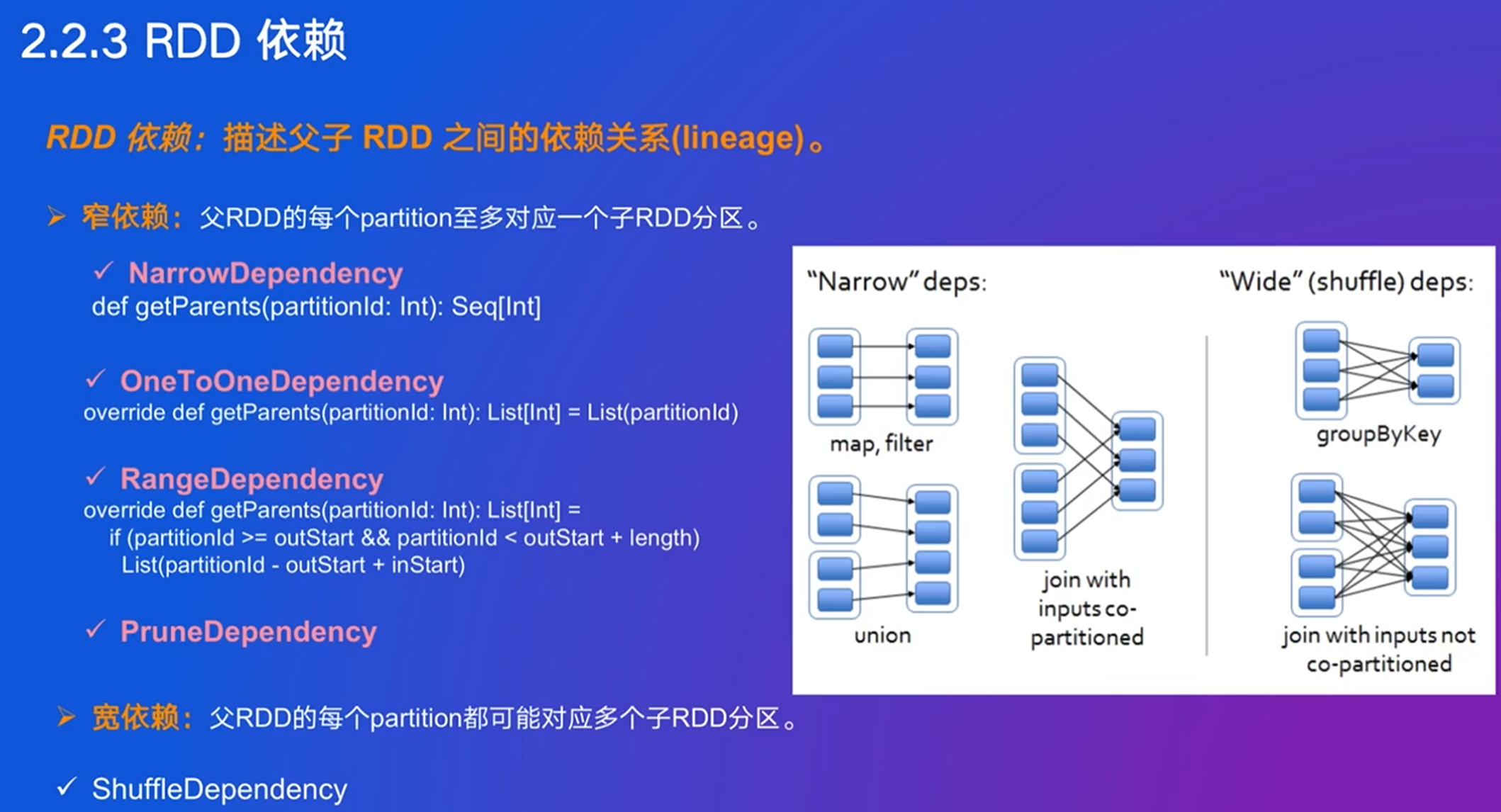

遇到宽依赖,就划分stage,不然加入stage


内存机制
栈(Stack):栈是一种后进先出(LIFO, Last In First Out)的数据结构。栈上的内存分配和释放速度通常比堆上快得多。这是因为栈的操作仅仅是移动栈顶指针来分配或释放内存,这个过程非常迅速且高效。此外,栈上的数据存储位置是在进程的调用栈中,这使得对栈内数据的访问也很快,因为这些数据通常是连续存储的,能够更好地利用CPU缓存。每当一个函数被调用时,一个新的“栈帧”(也叫活动记录)就会被创建并压入调用栈中。
堆(Heap):堆则是一个更复杂的自由存储区,允许动态分配内存。与栈不同,堆上的内存分配(如通过malloc()或new操作)涉及到搜索可用空间并将该块标记为已使用的过程,这通常比简单地调整栈指针要复杂和耗时。同样,释放堆上的内存也可能需要额外的操作来维护堆的结构。因此,堆的分配和释放速度较栈慢。当一个程序执行时,操作系统会为该程序分配一定的内存空间,这部分内存包括了代码区、数据区、堆区以及栈区等。
这些是堆内存,off-heap也有,比heap更好管理
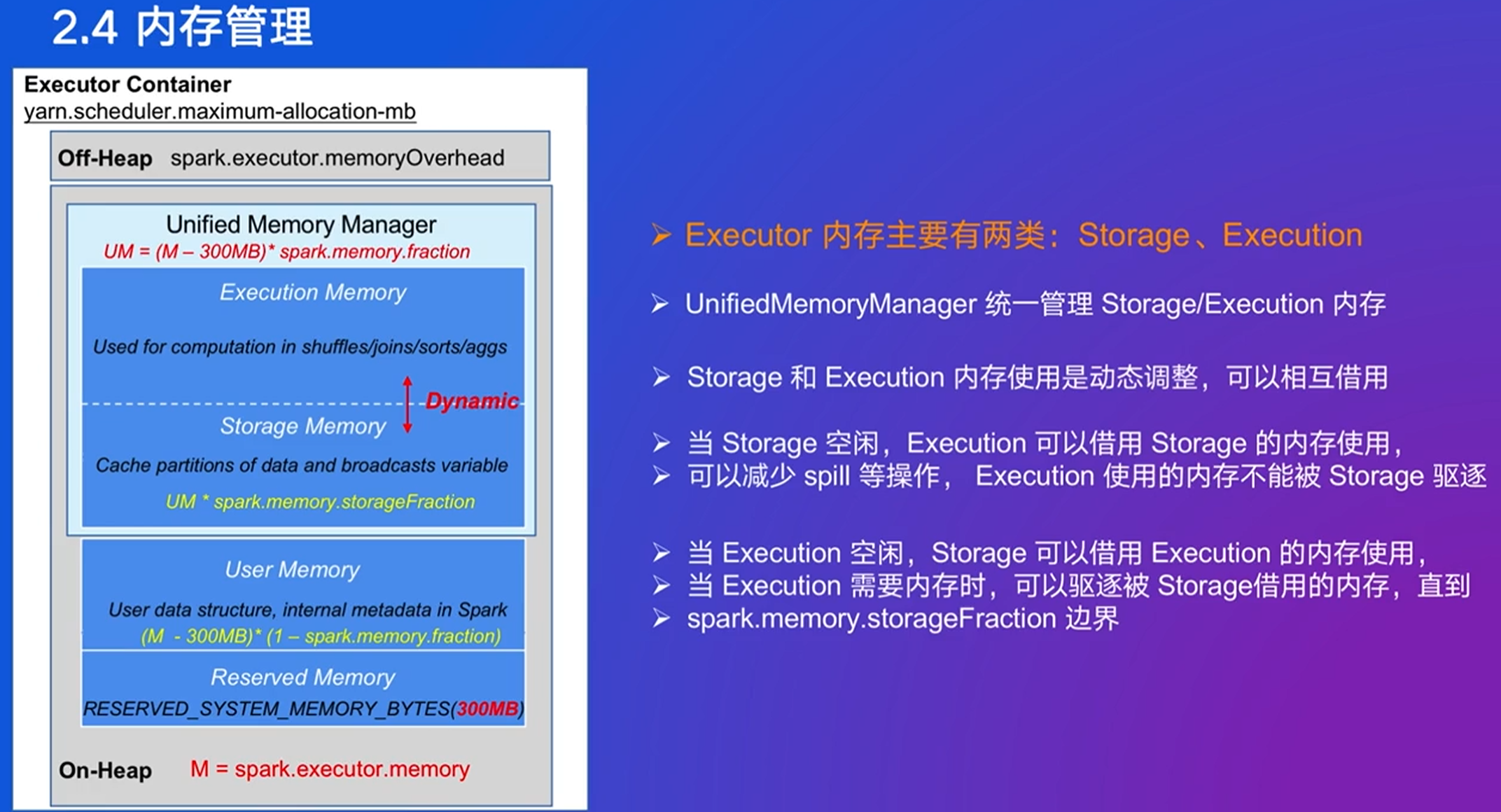
存储和执行内存是可以互相借用的
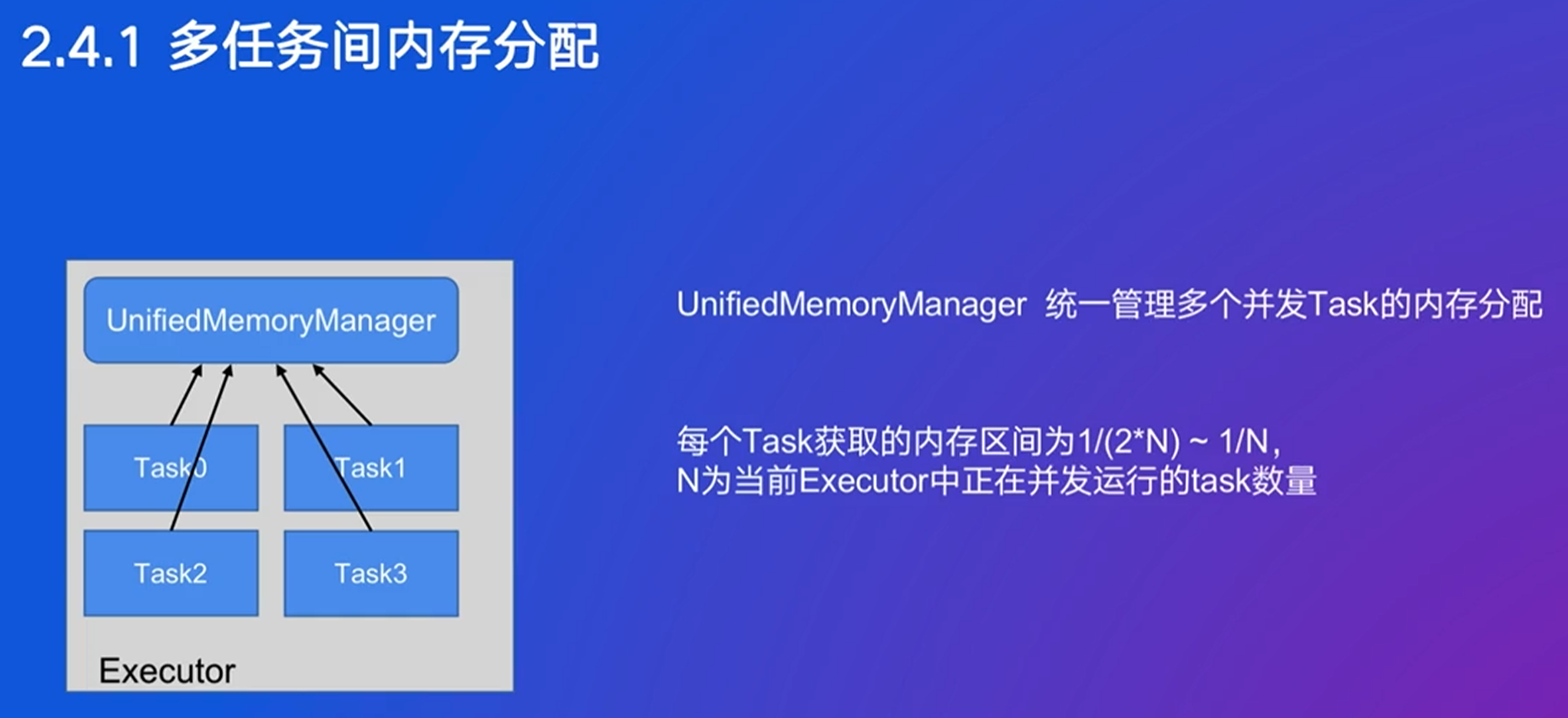
一个Executor可以允许多个Task
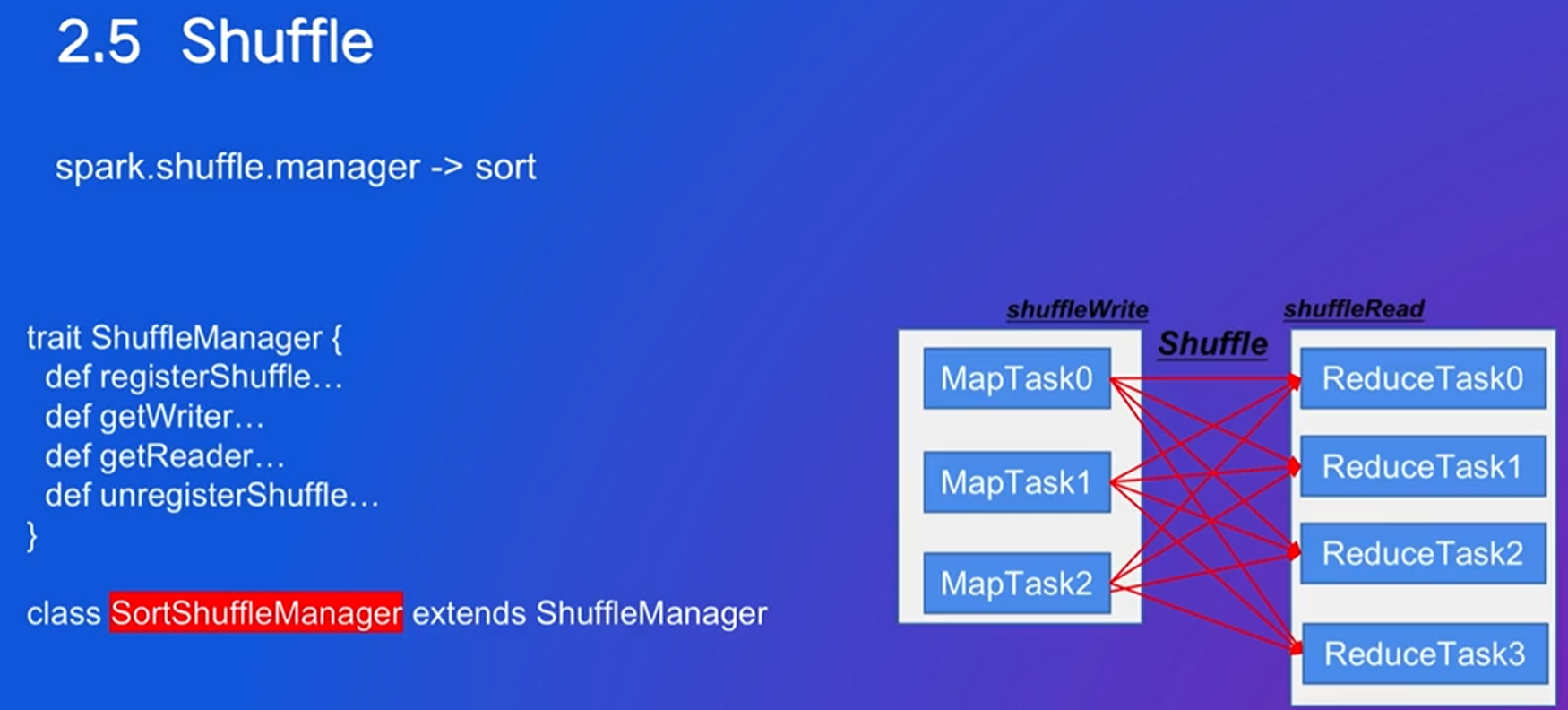
Shuffle
Shuffle是指数据重新分配的过程,这个过程通常发生在并行计算任务之间,目的是将数据按照某种规则重新分组或排序,以便后续的任务可以基于这些重组后的数据进行处理。Shuffle是实现许多常见操作(如groupByKey、reduceByKey、join等)的关键步骤。

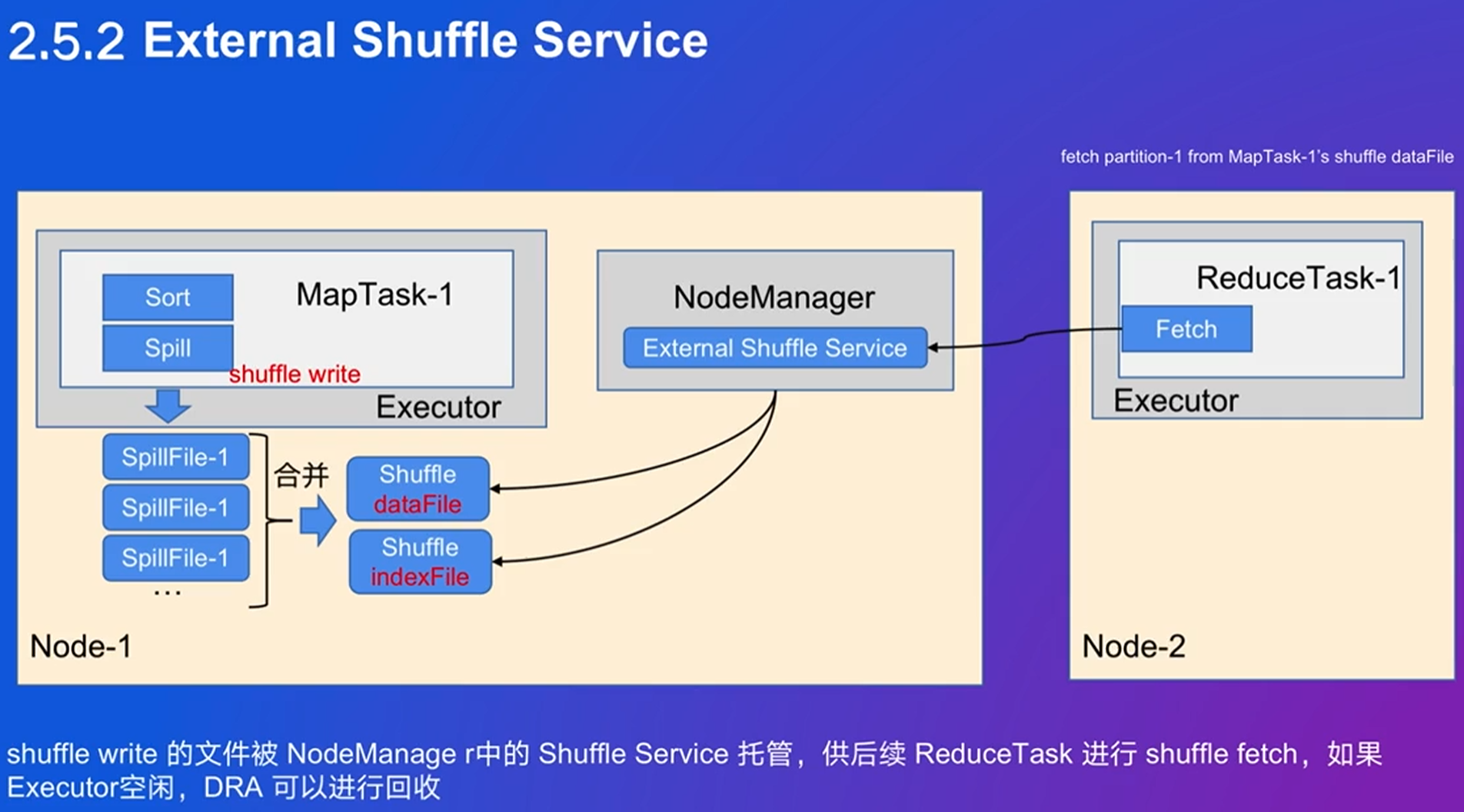
3. SparkSQL 原理解析
优化逻辑计划->选择最佳的物理执行计划:基于规则的优化等

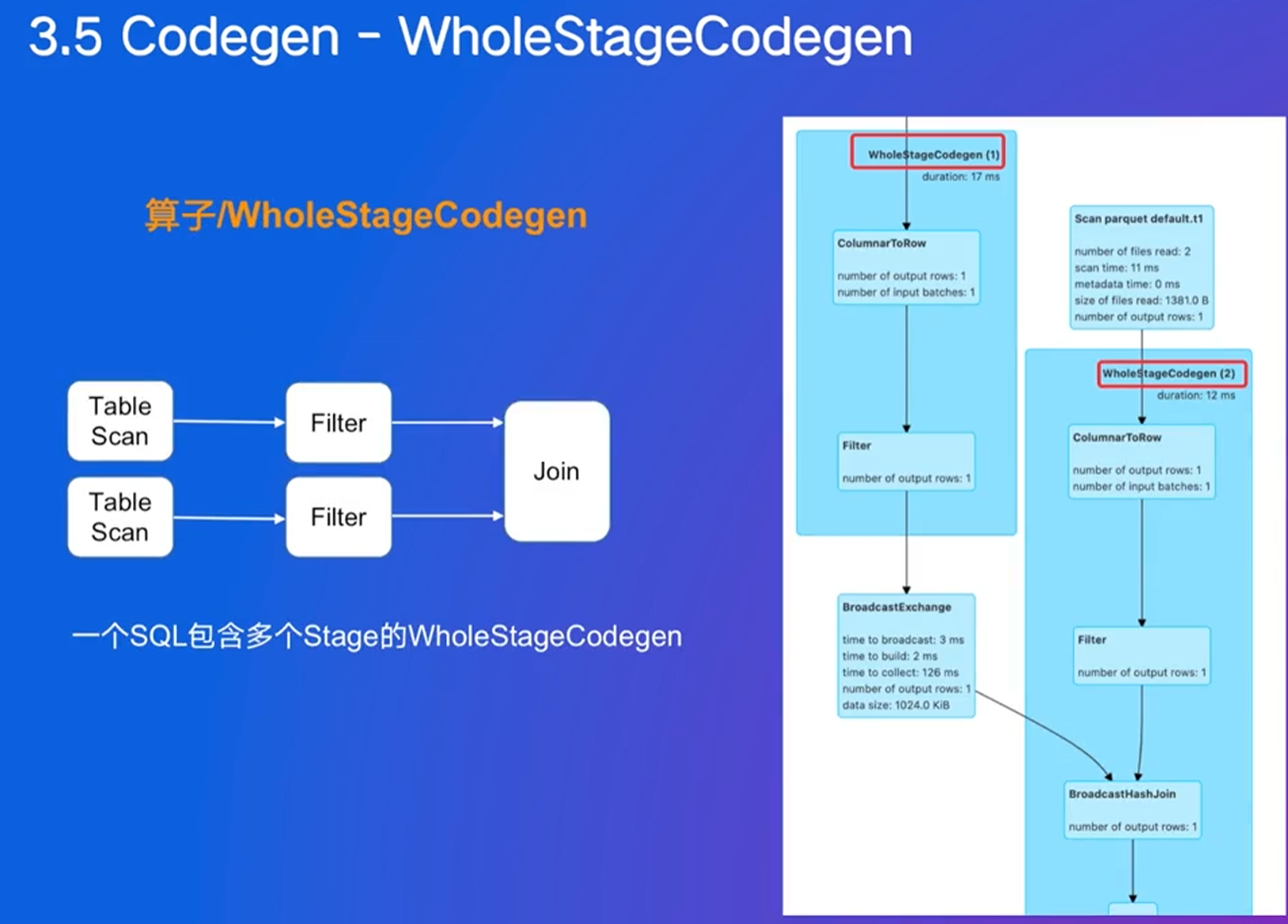
Catalyst:生成可以执行的代码


RBO:经验式、启发式,谓词下推
CBO:依赖数据库对象的统计

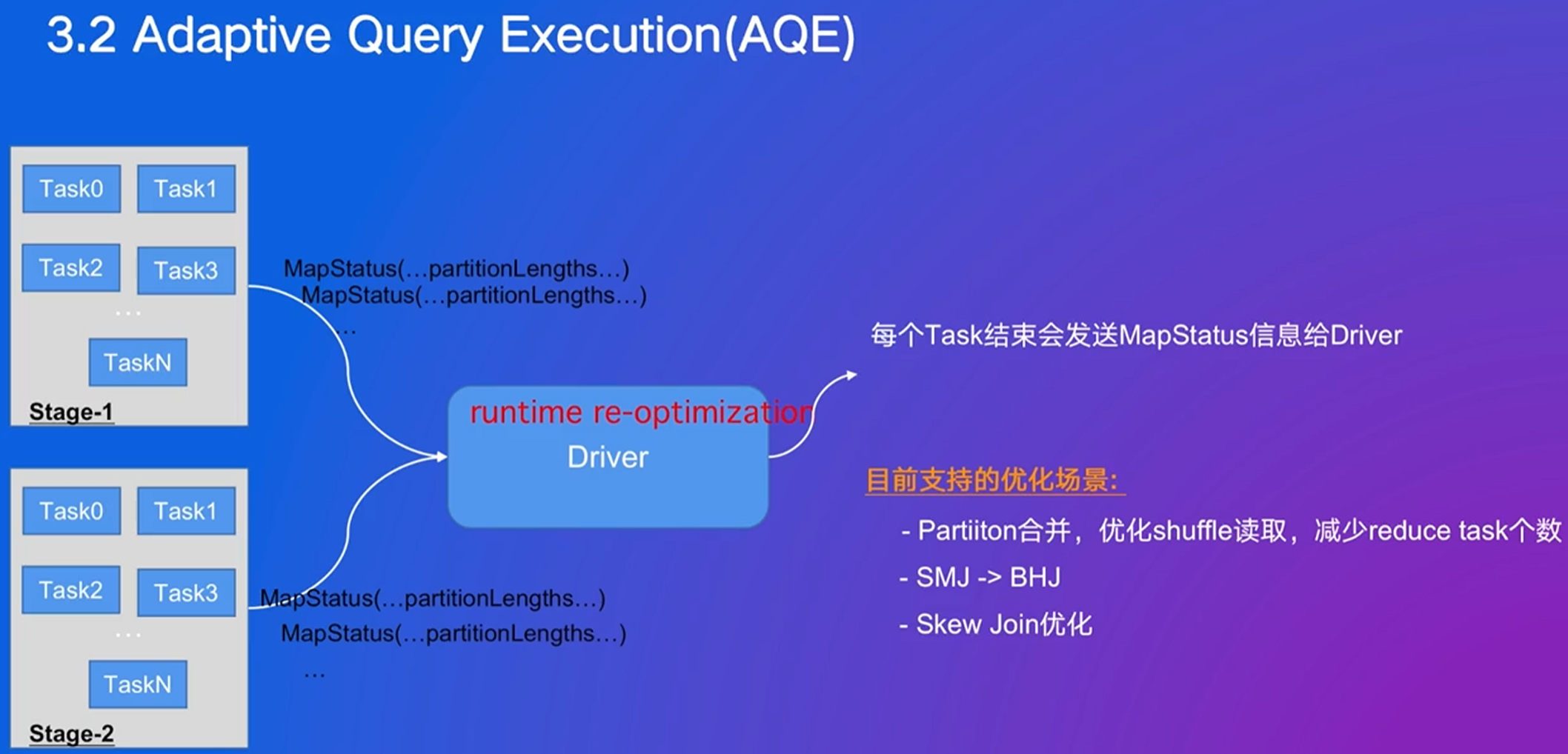
自适应查询:执行中检测哪些可以进行优化,边执行边优化并有反馈
- 动态合并Shuffle分区
- 动态切换join策略
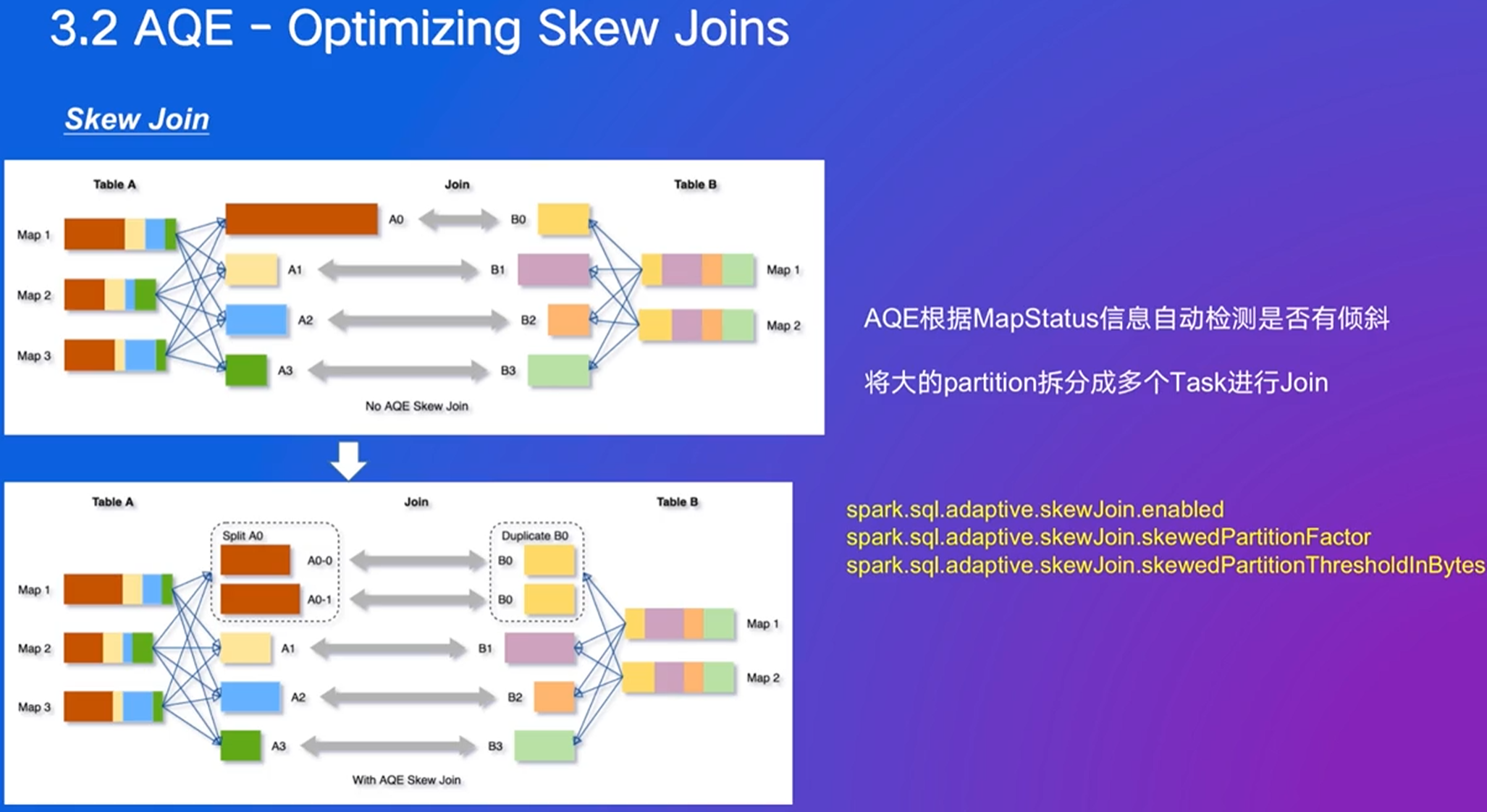
- 处理状态数据倾斜的问题
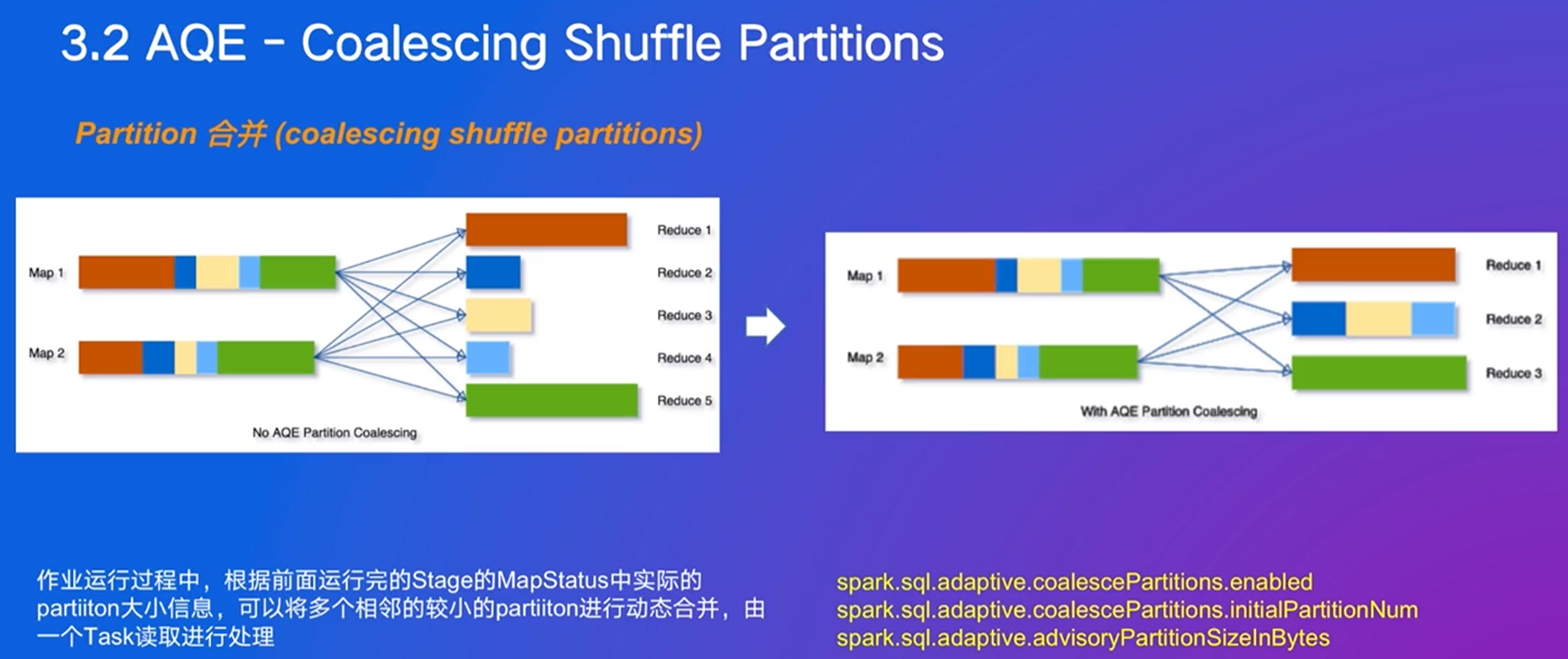
partition要适中,刚开始shuffle较大,然后合并相邻的(下图从5->3)
实现时开启参数即可


常规代码是遍历语法树,每个节点都要进行类型匹配,会额外创建很多对象:没必要,只是一个表达式

每个filter只用关注自己的逻辑
4. Spark 在业界的挑战与实践

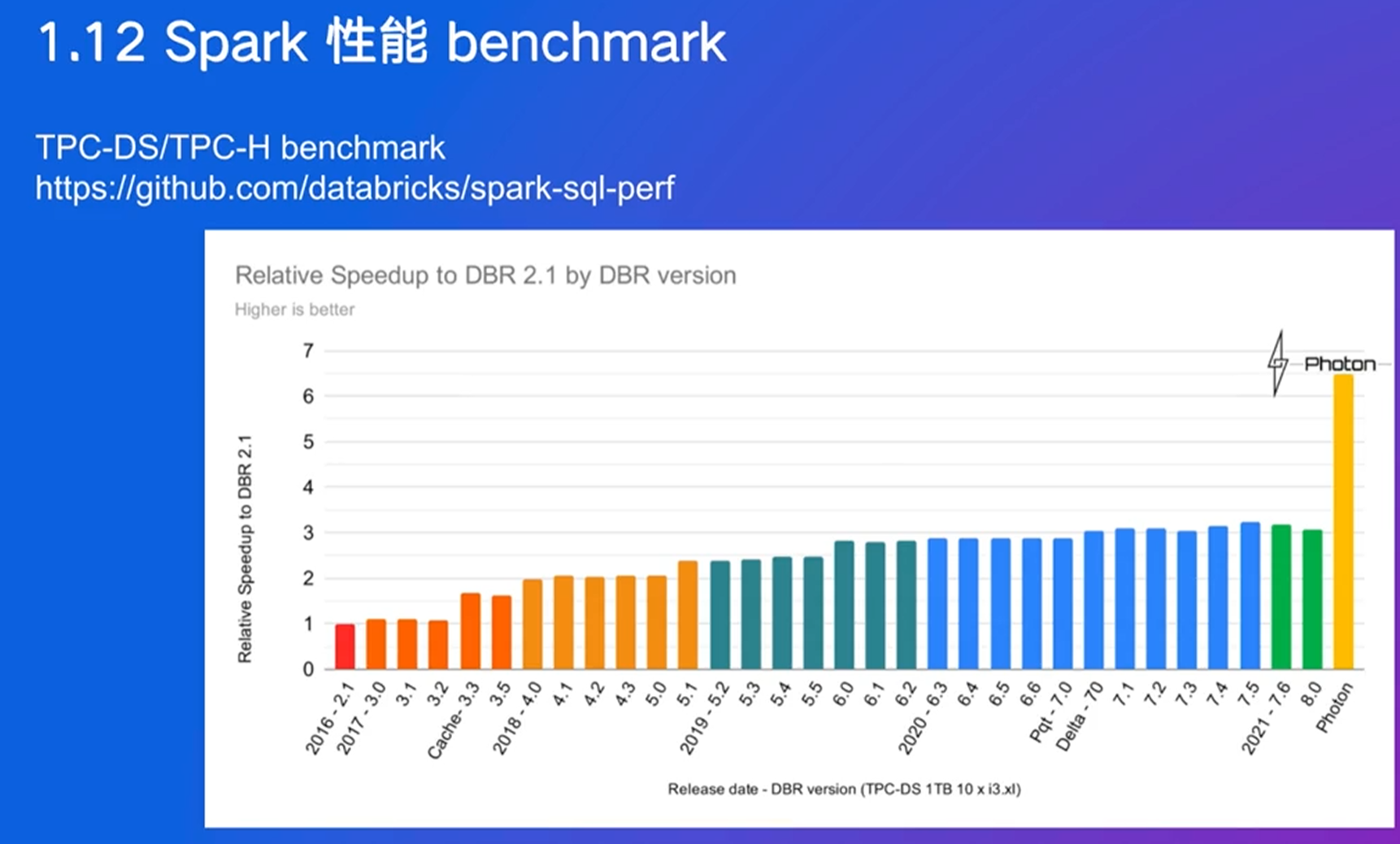
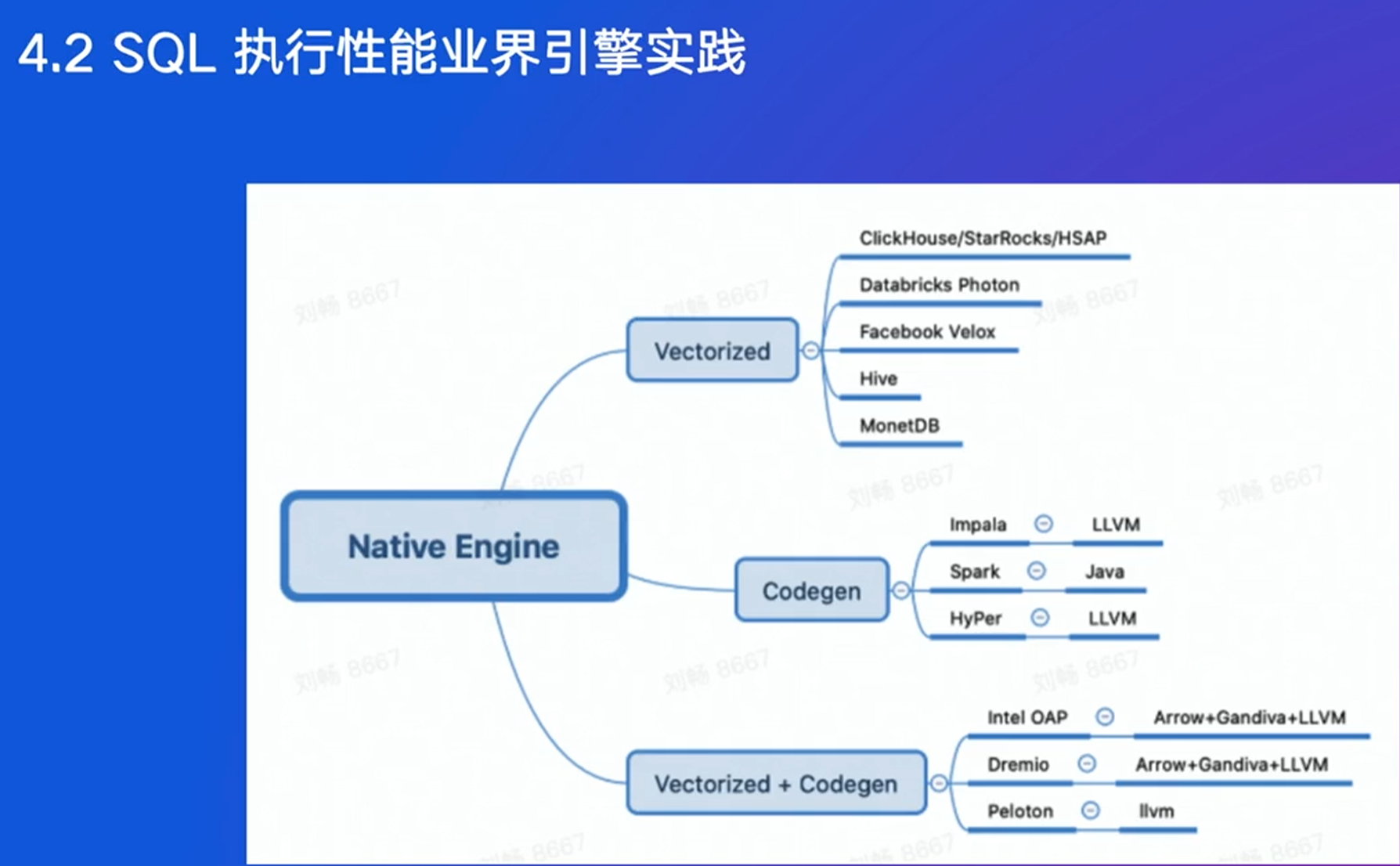
近些年的优化关注CPU
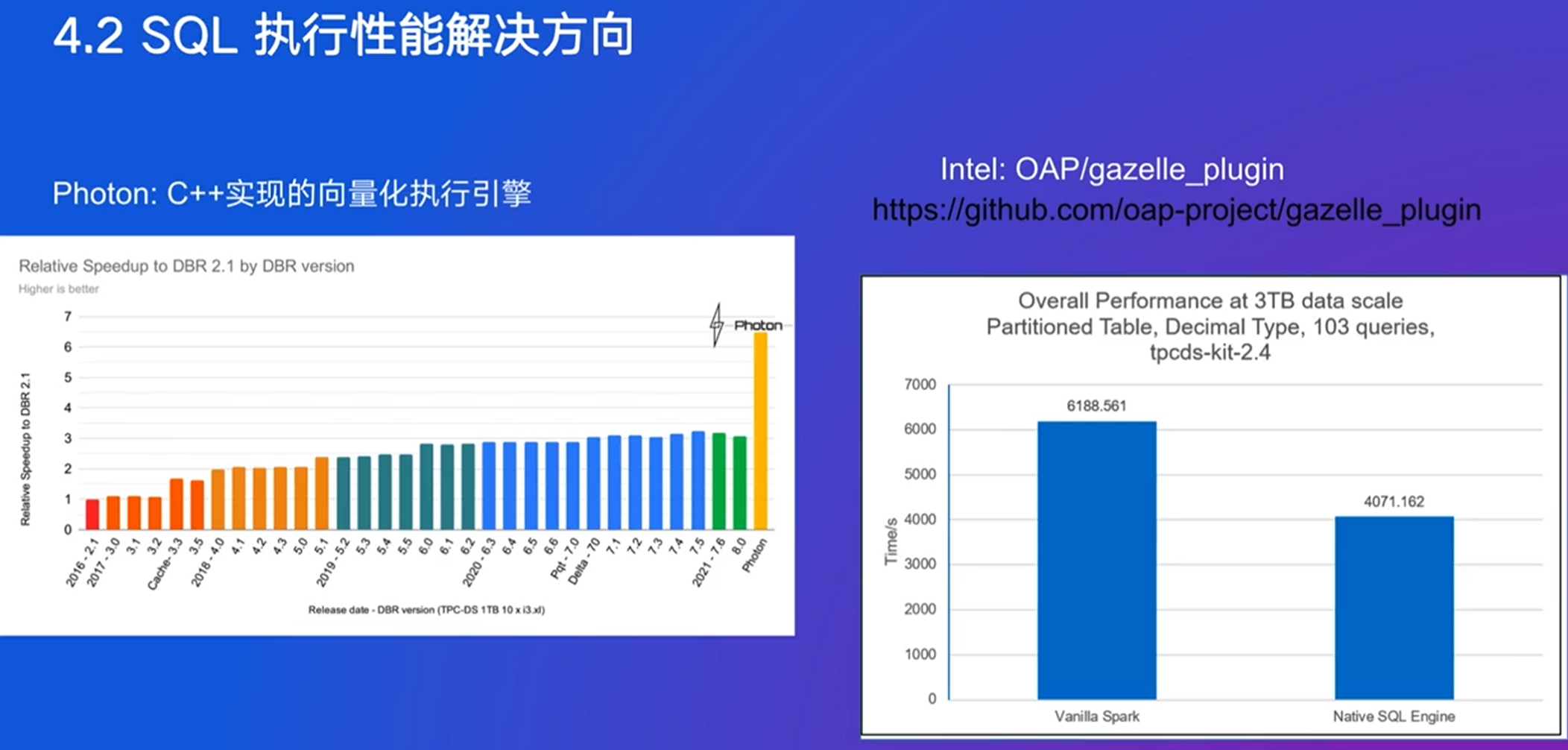


6. 大数据Shuffle原理与实践
1. Shuffle 概述
从Oracle单机引擎到现在的分布式MapReduce
把数据拆分成小份partition,做并发处理
- 对不同颜色的数据分别处理
- Shuffle:移动数据




不光有网络连接,还有网络请求
可能要以颜色进行排序
序列化消耗大量CPU


2. Shuffle 算子
repartition:改变分区
join:本身不在一起的数据放在一起
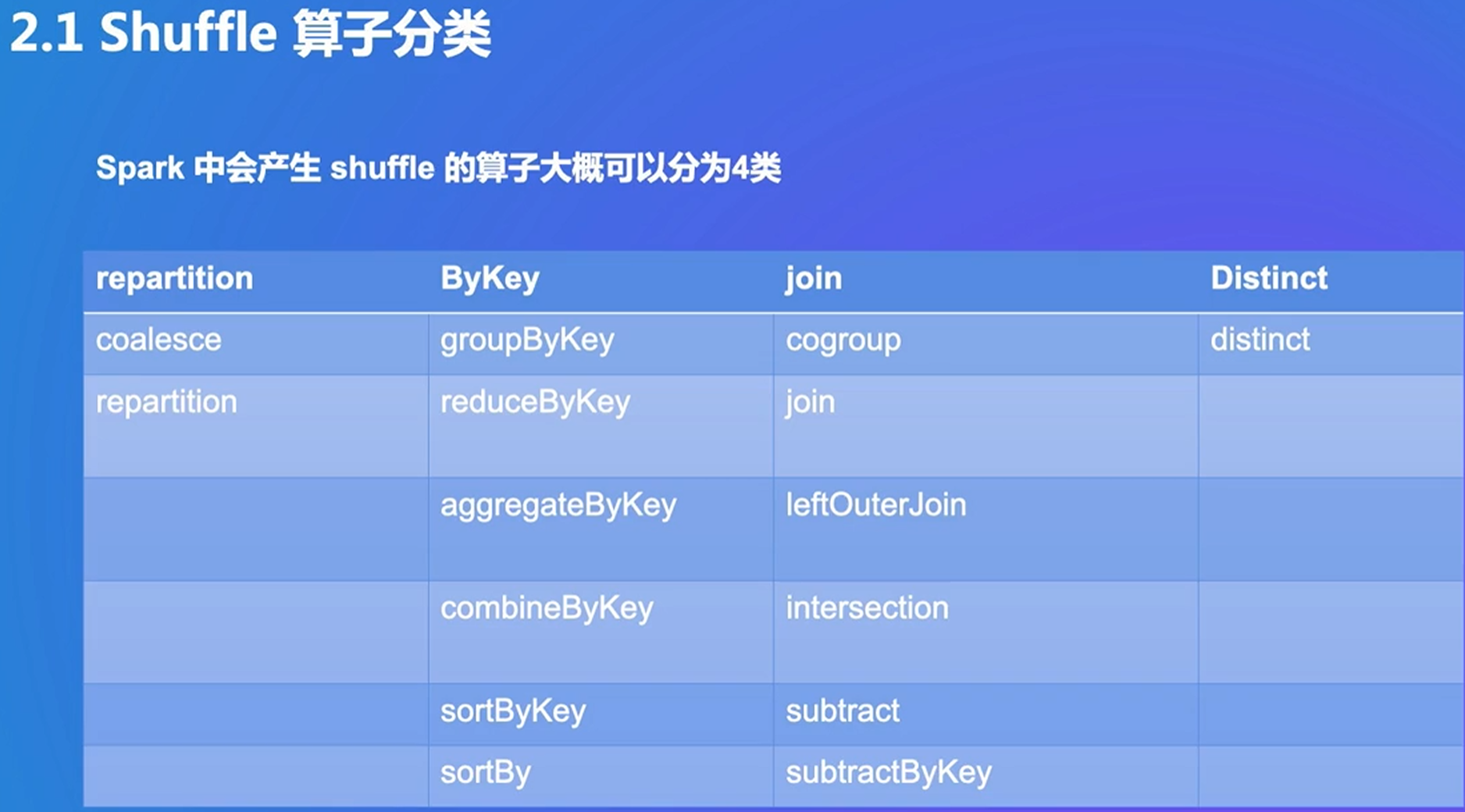

需要数据移动就使用shuffle
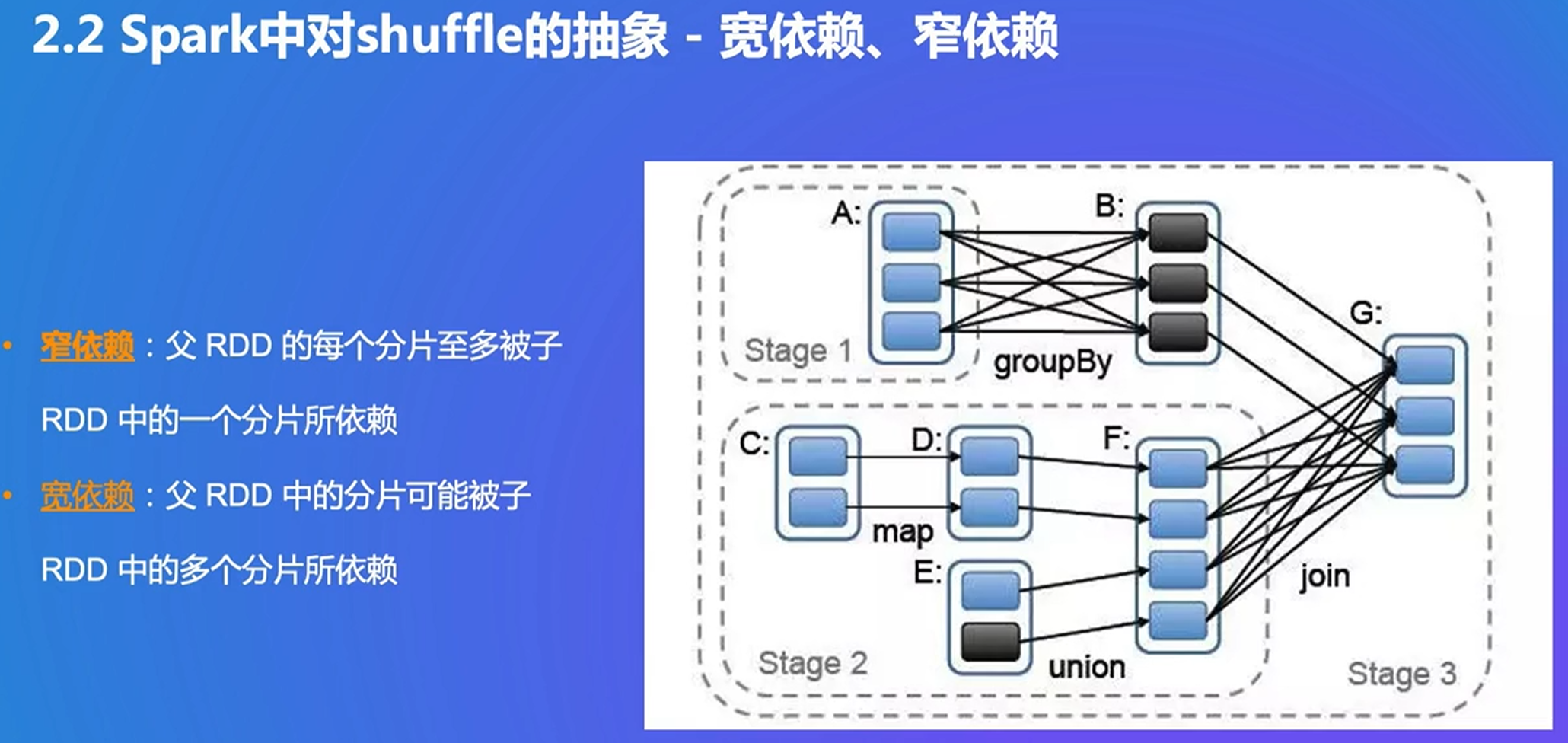


numberPartitions:一共有多少分区,get:给一个k返回所在分区


3. Shuffle 过程
tradeoff问题

写满了就把file写入磁盘,同时打开和生成的文件都很多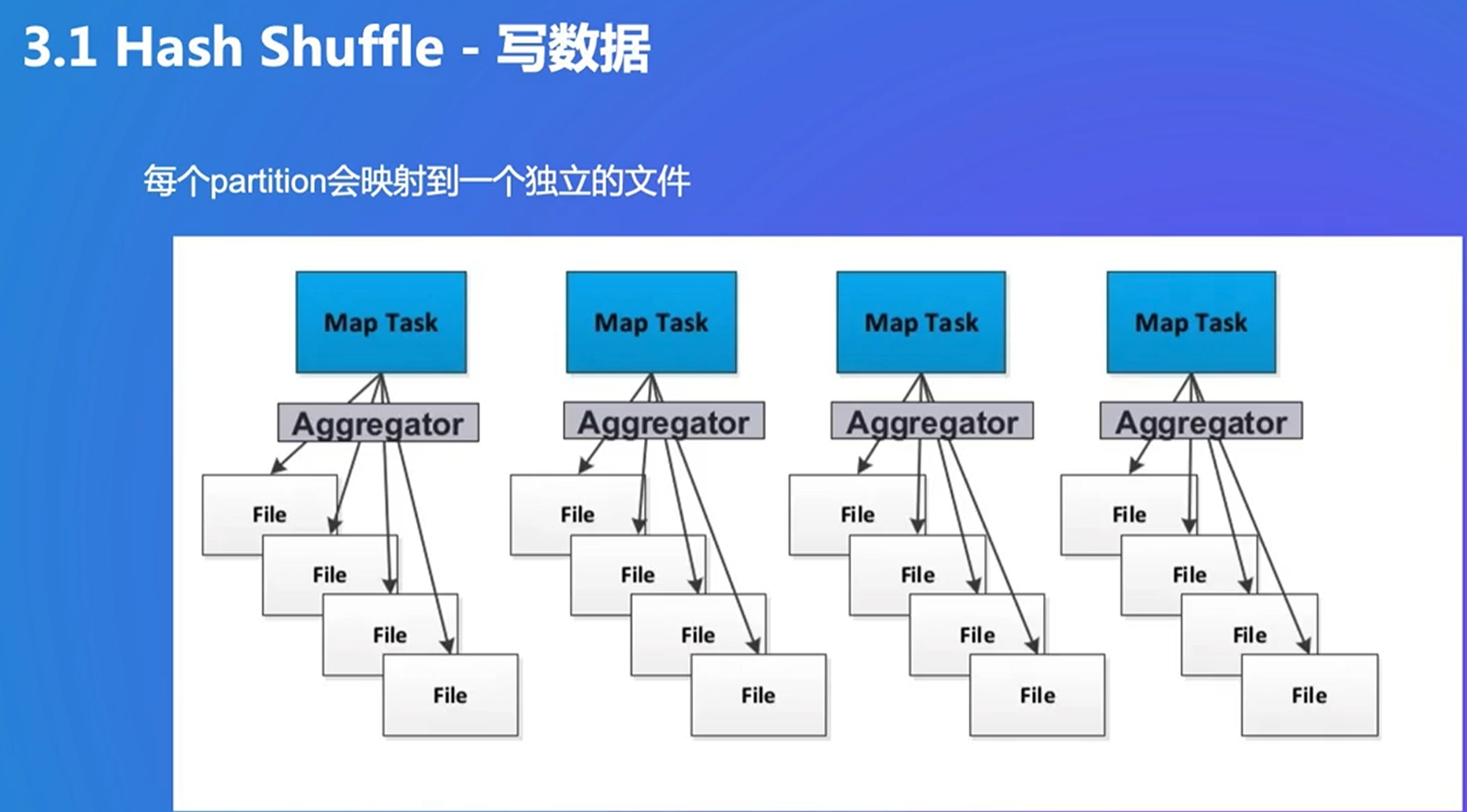

不是给每个partition一个buffer,现在是一个task一个buffer,包含所有数据
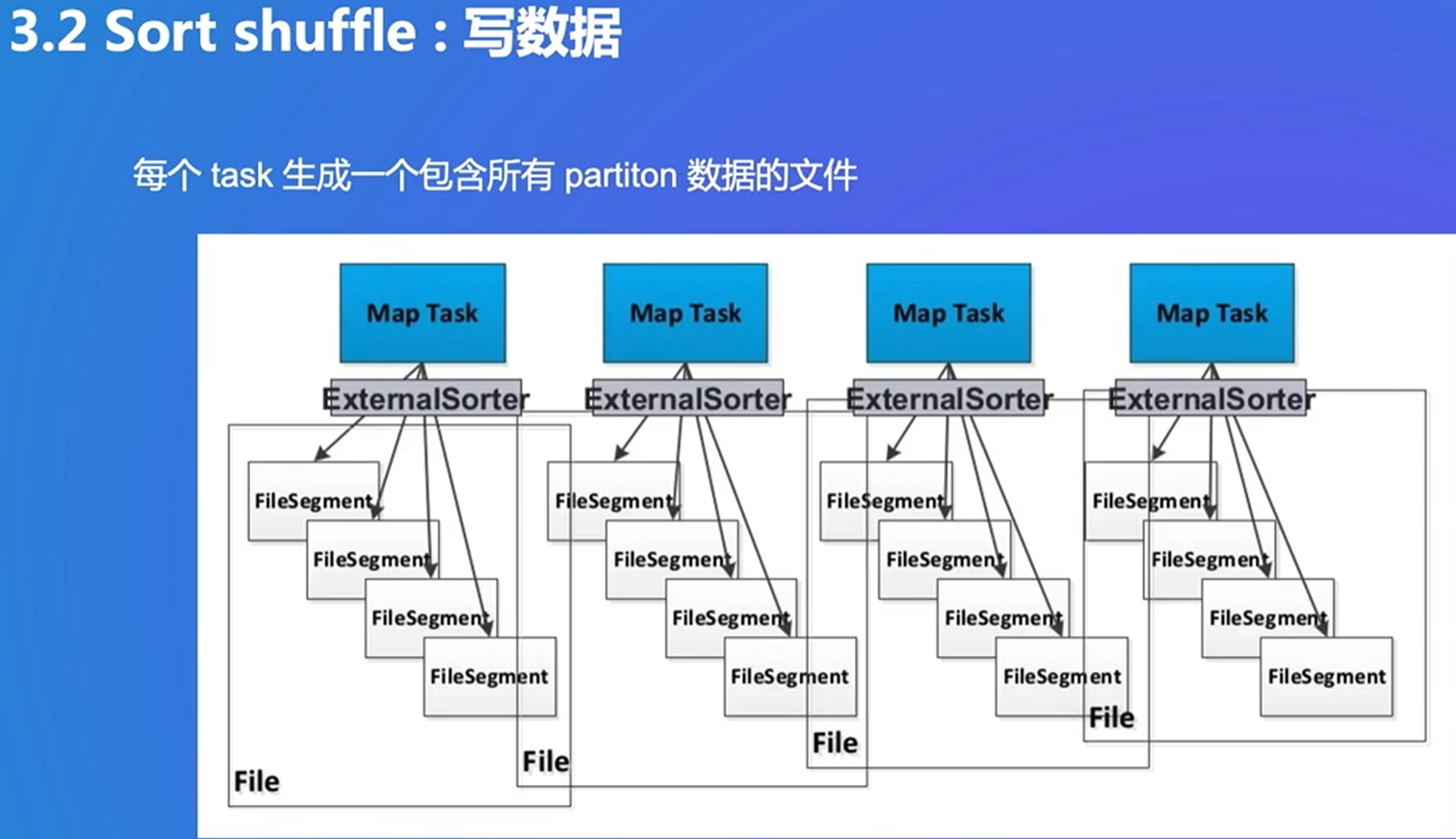
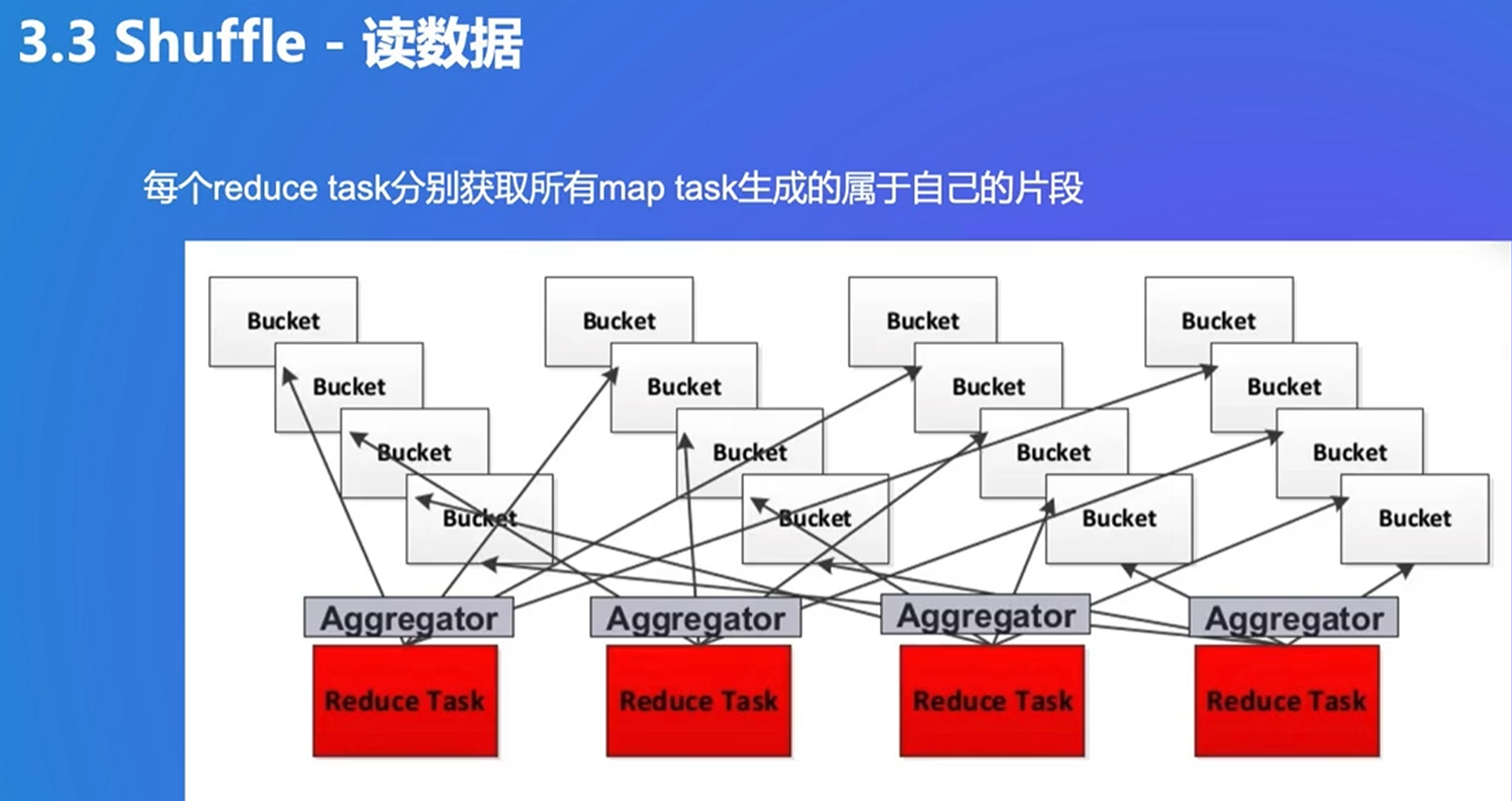


最终生成两个文件。没排序,只适合数据较少时
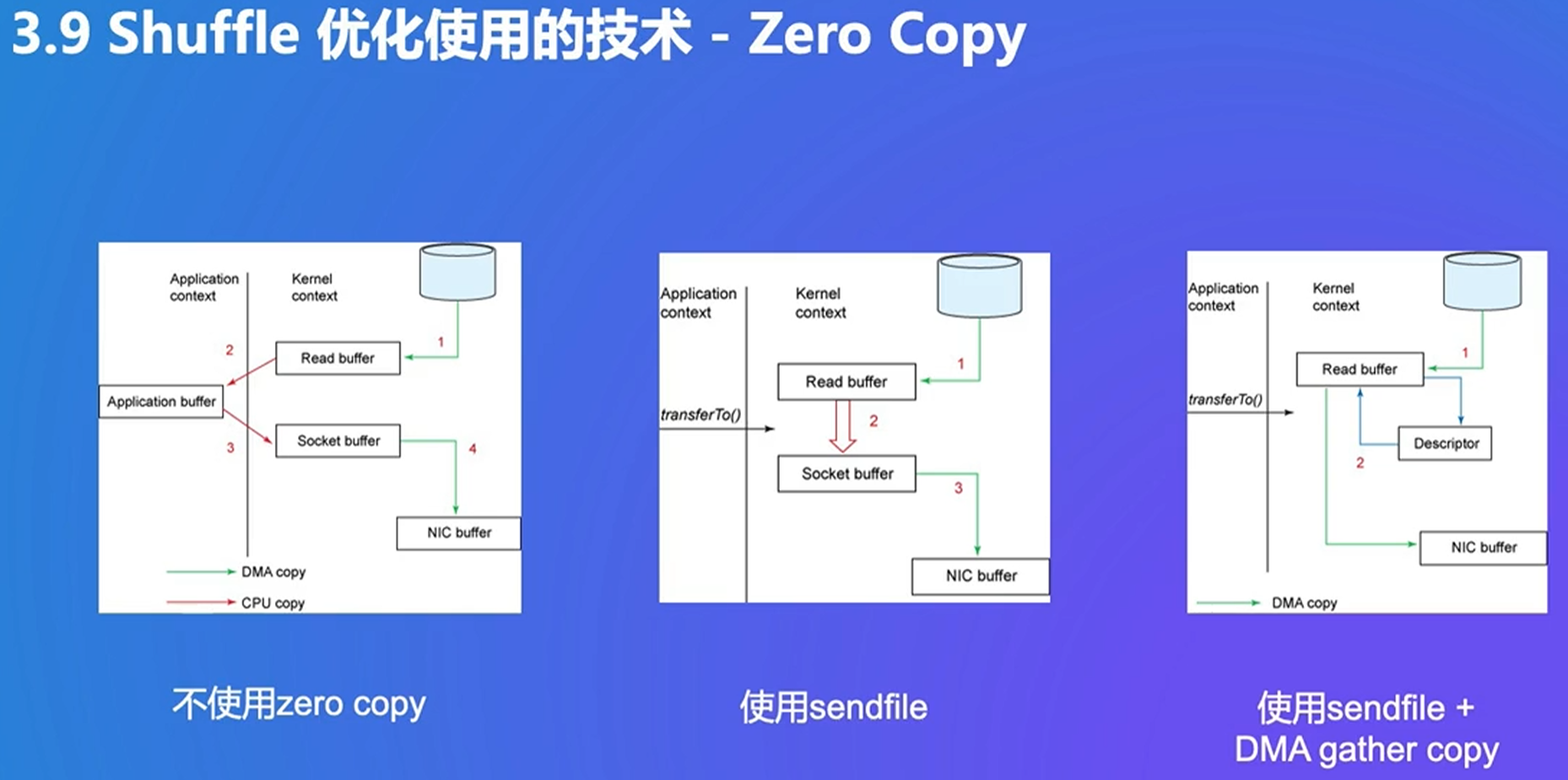
OS中的zero copy?

unsafe:没有垃圾回收的开销
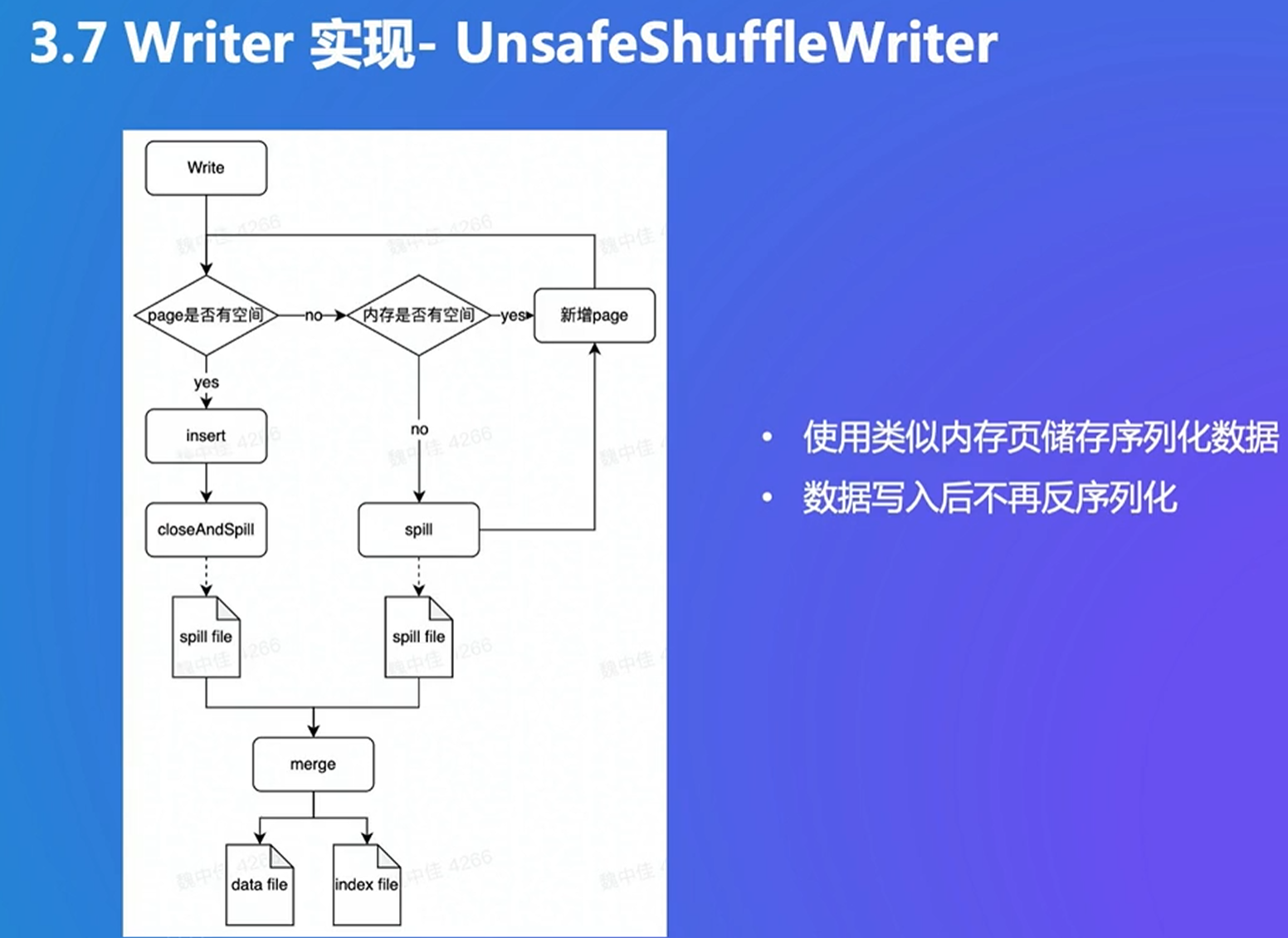

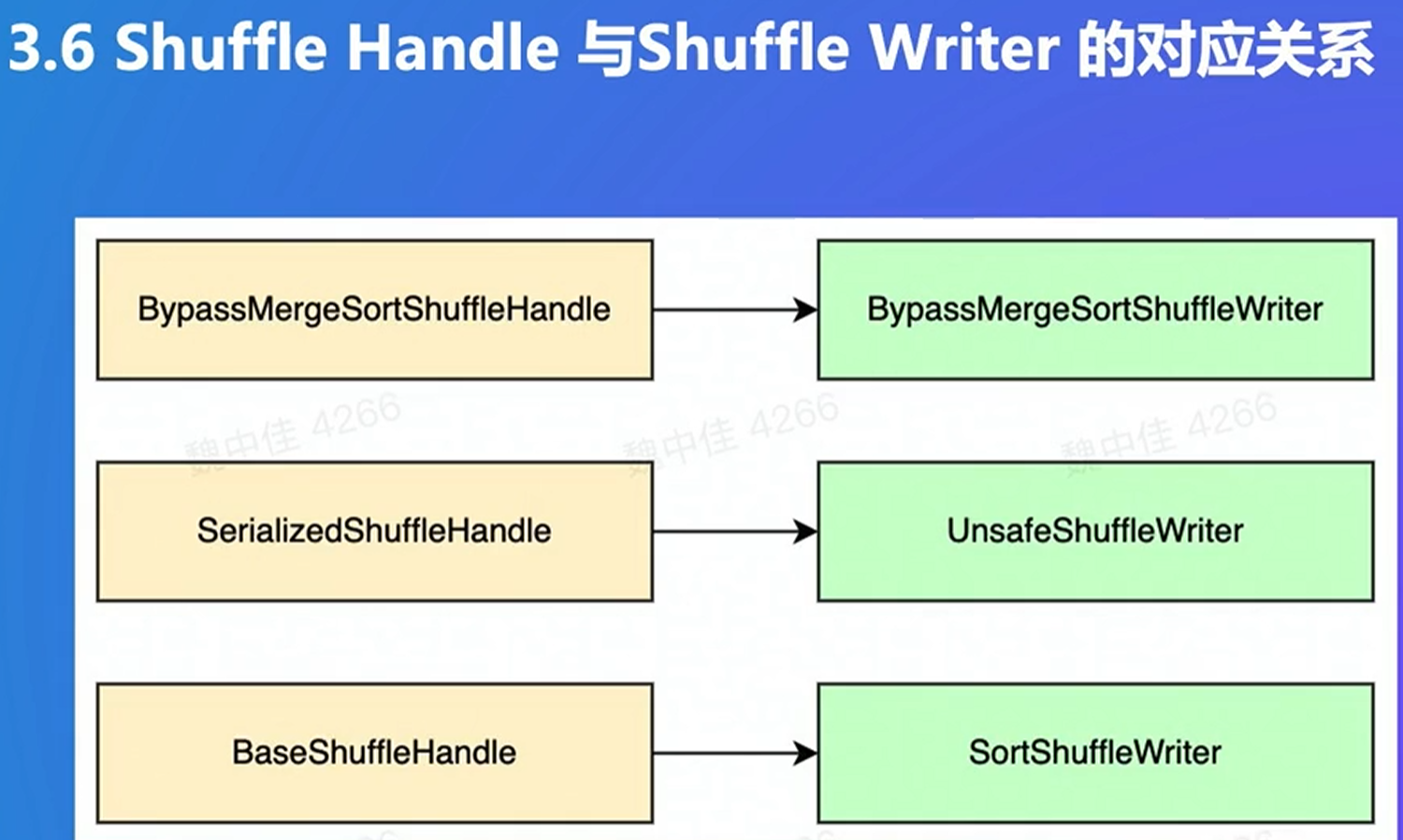
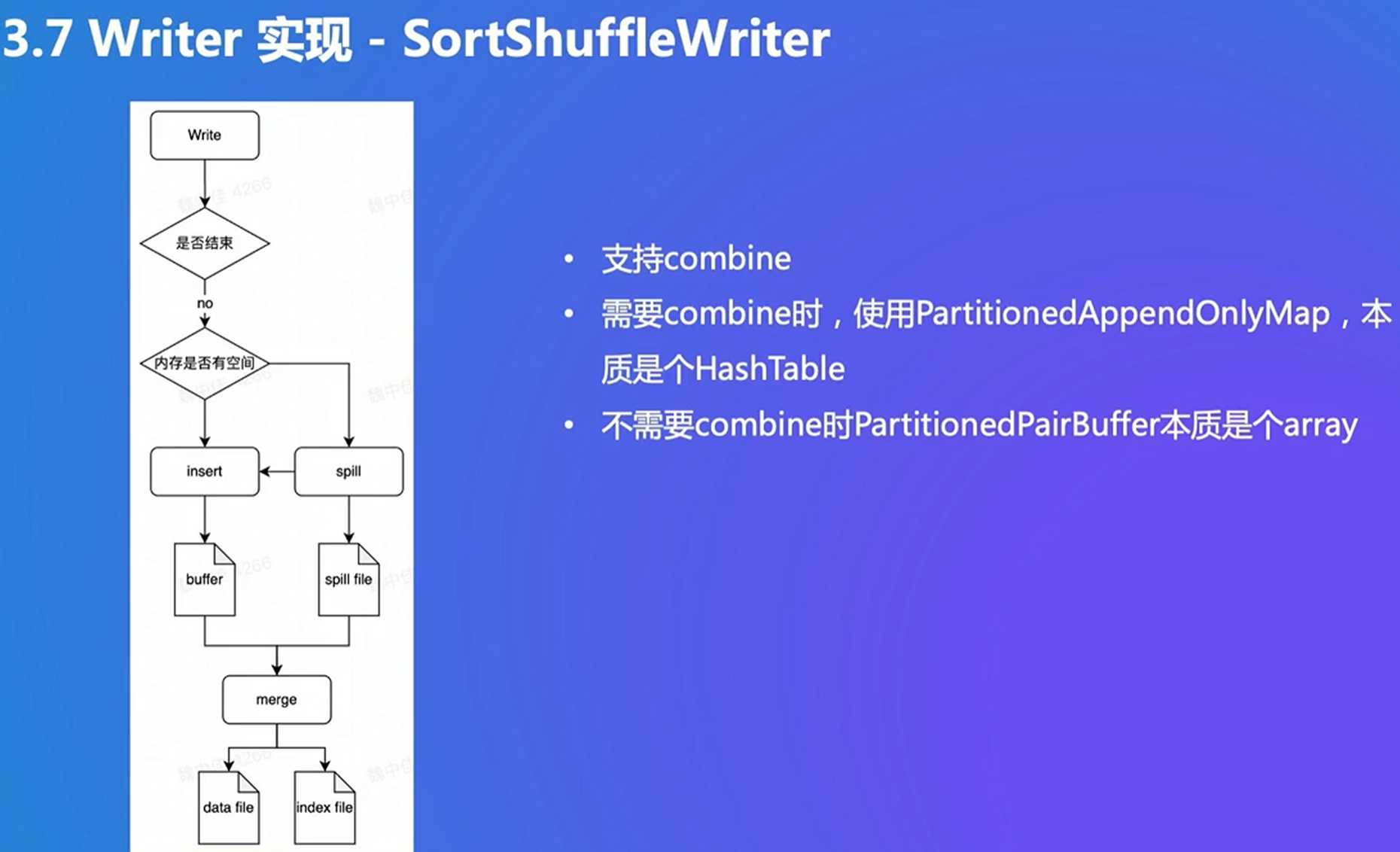
有排序和combine,和mapreduce有点类似



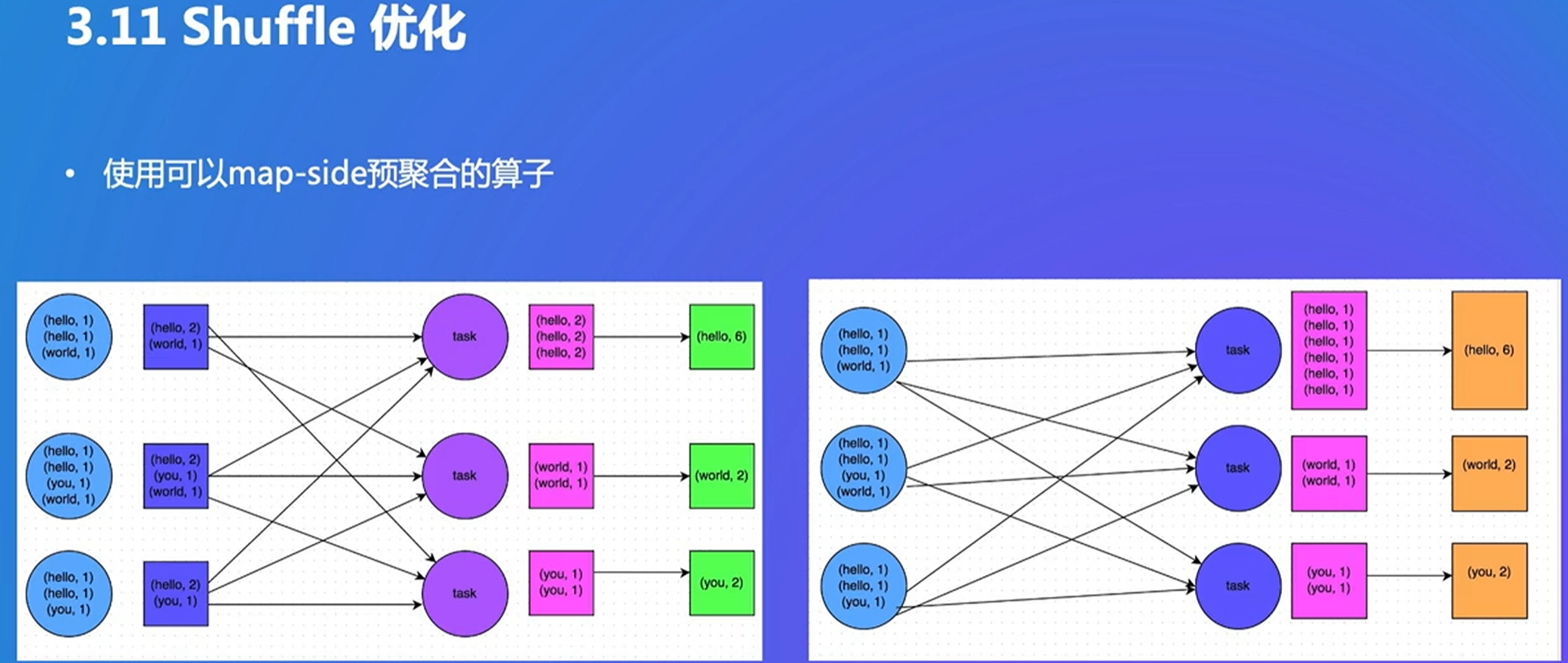
做wordcount,右侧shuffle的数据量多,左边提前算了hello的count,算子是有优先级的。如果能聚合尽量做聚合

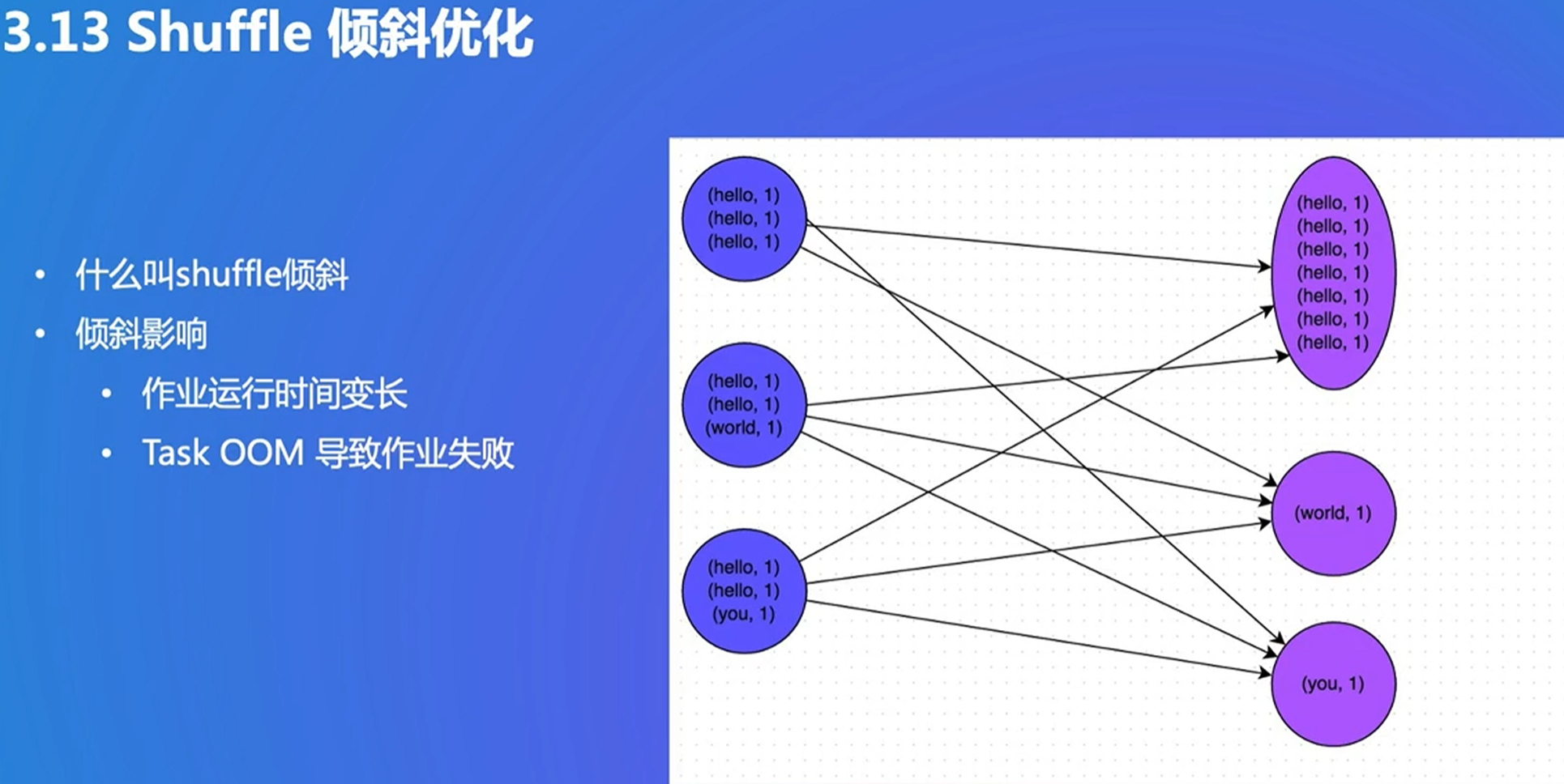
倾斜:某个reduce数据非常多,其他很少,因为总时间取决于最大的作业

84万文件,5千task,数据量非常大

优化后只有5000个partition,shuffle数据量变少(因为单个task处理的变多了),有combine用conbine
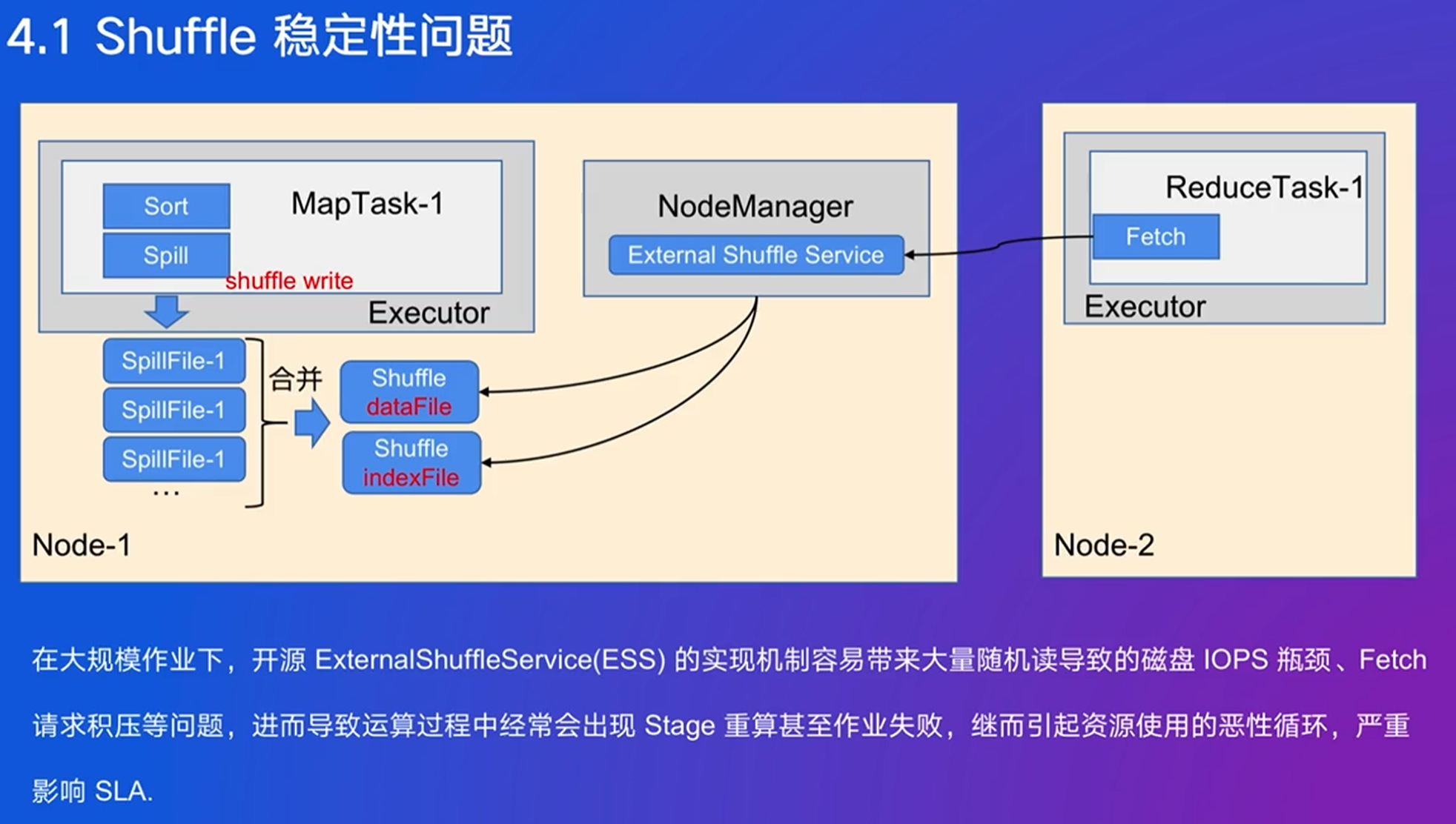
减缓随机读的要求

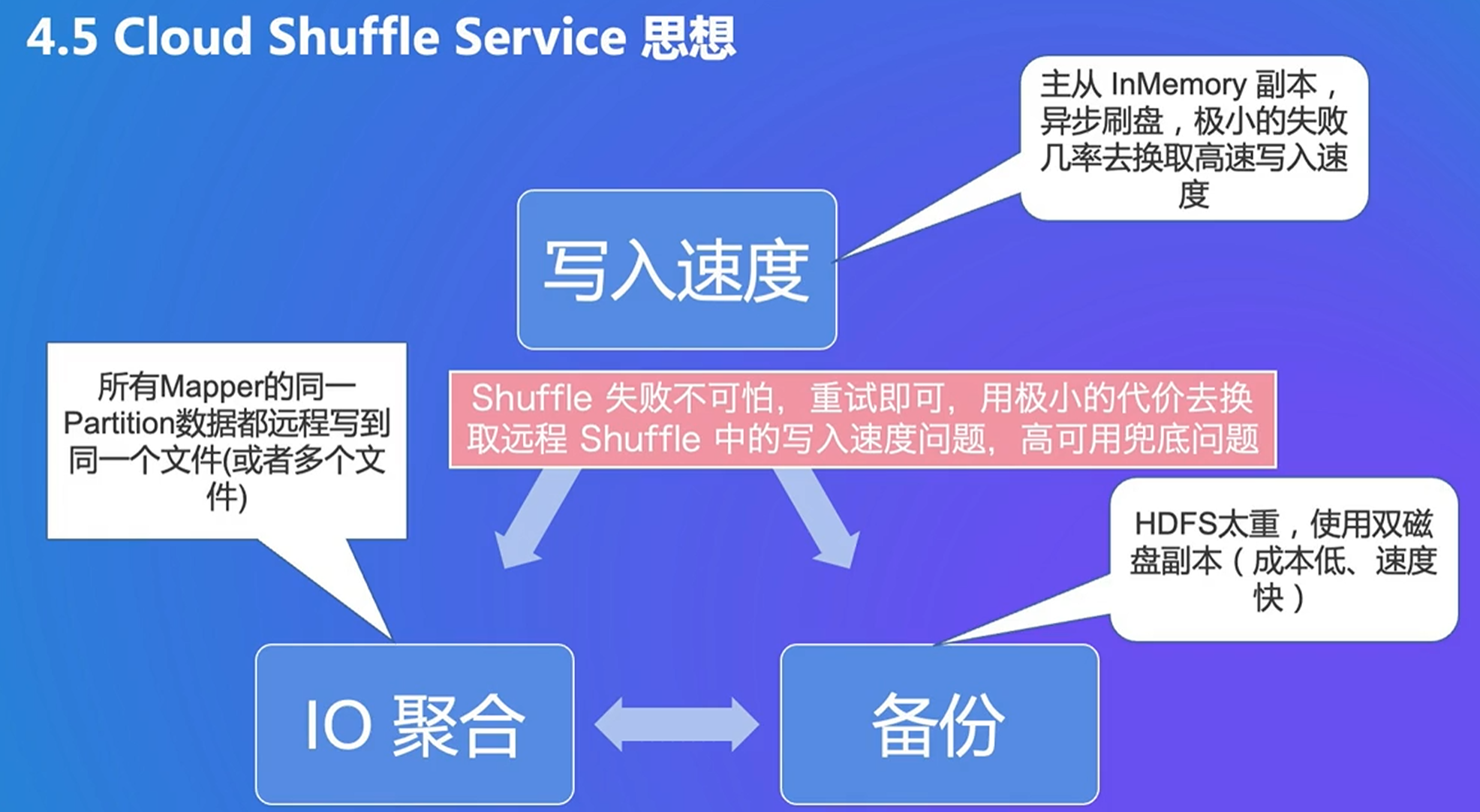
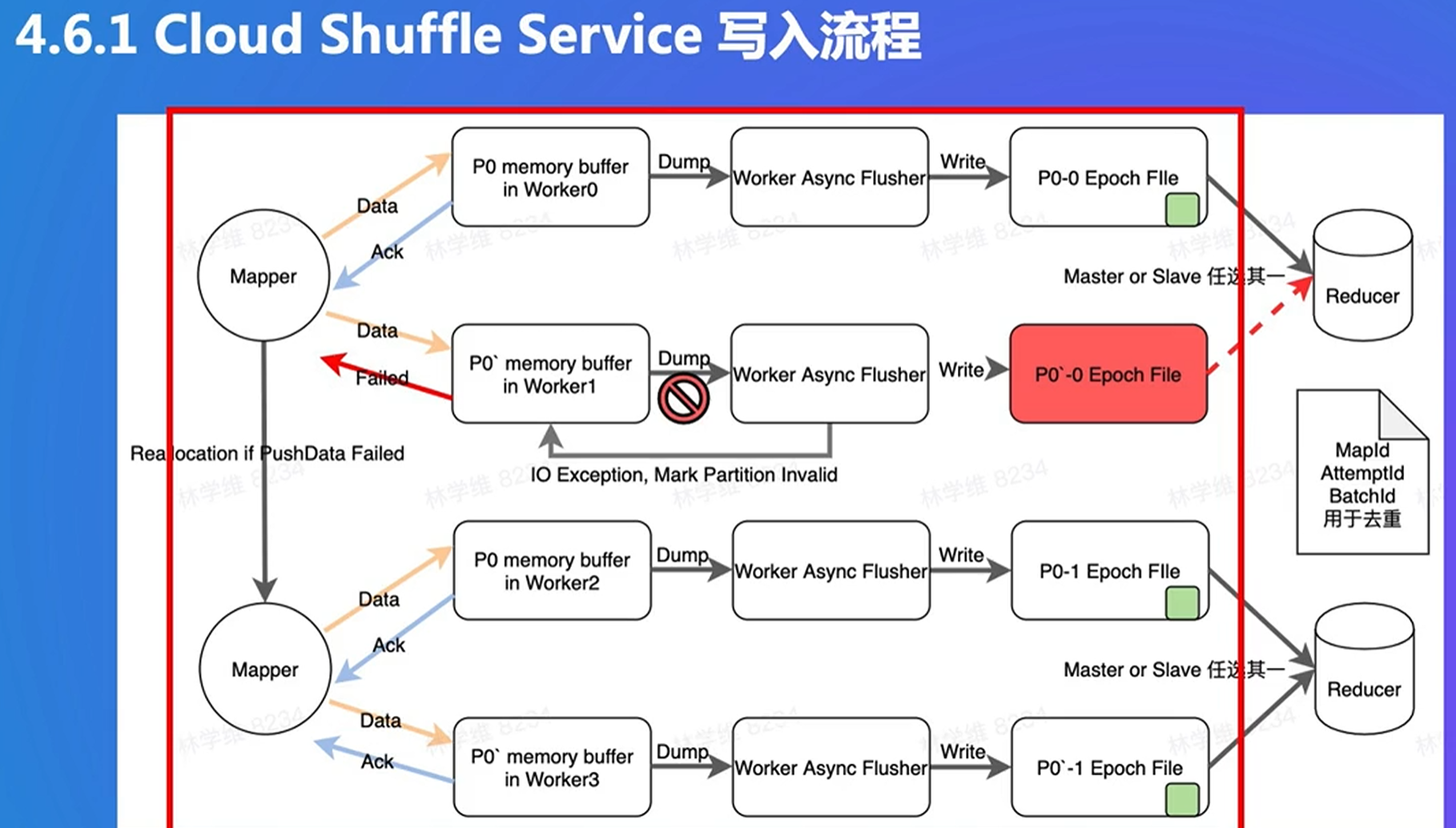
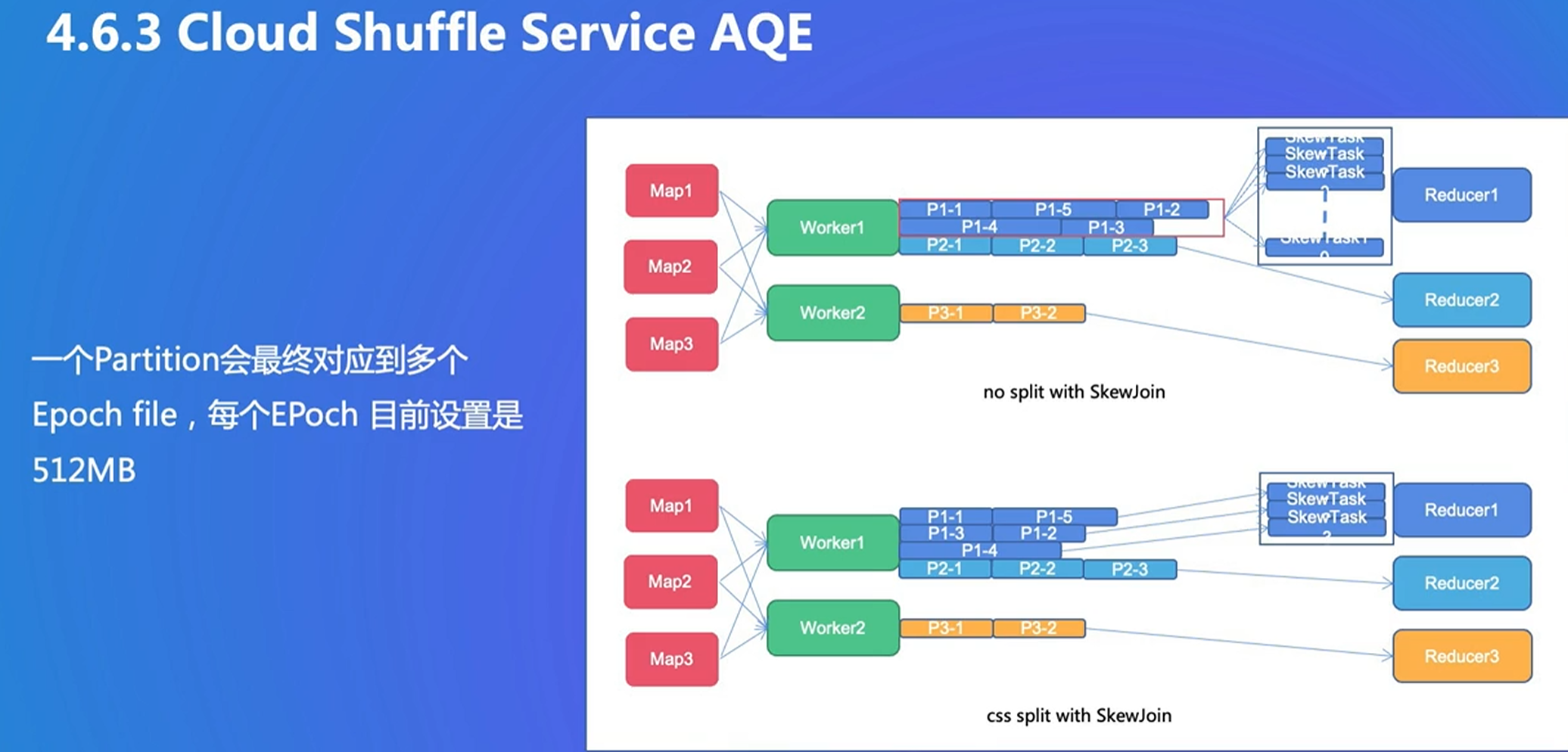
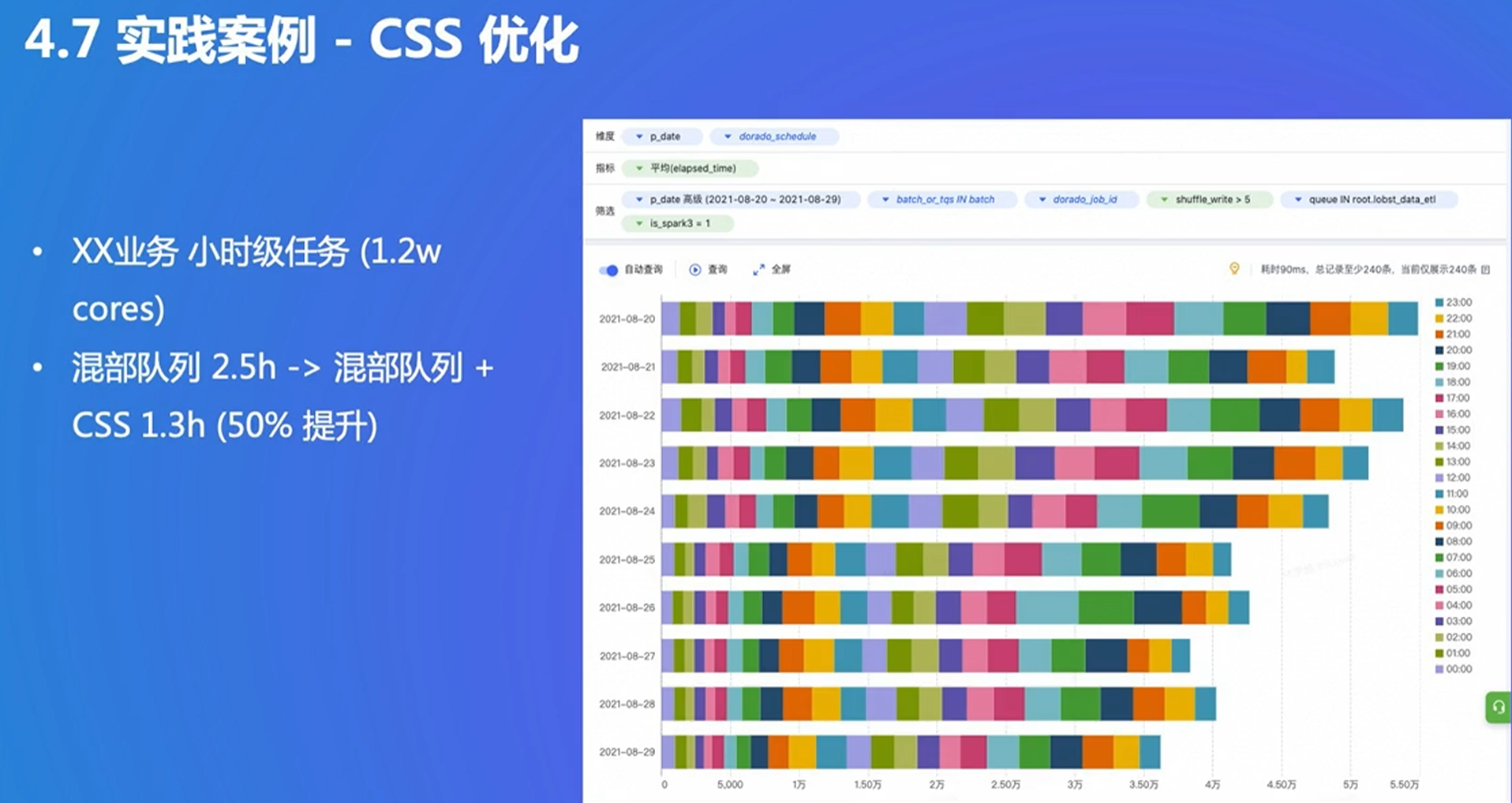
4. Push Shuffle
大量随机读的问题:用push聚合在一起,写在远程buffer
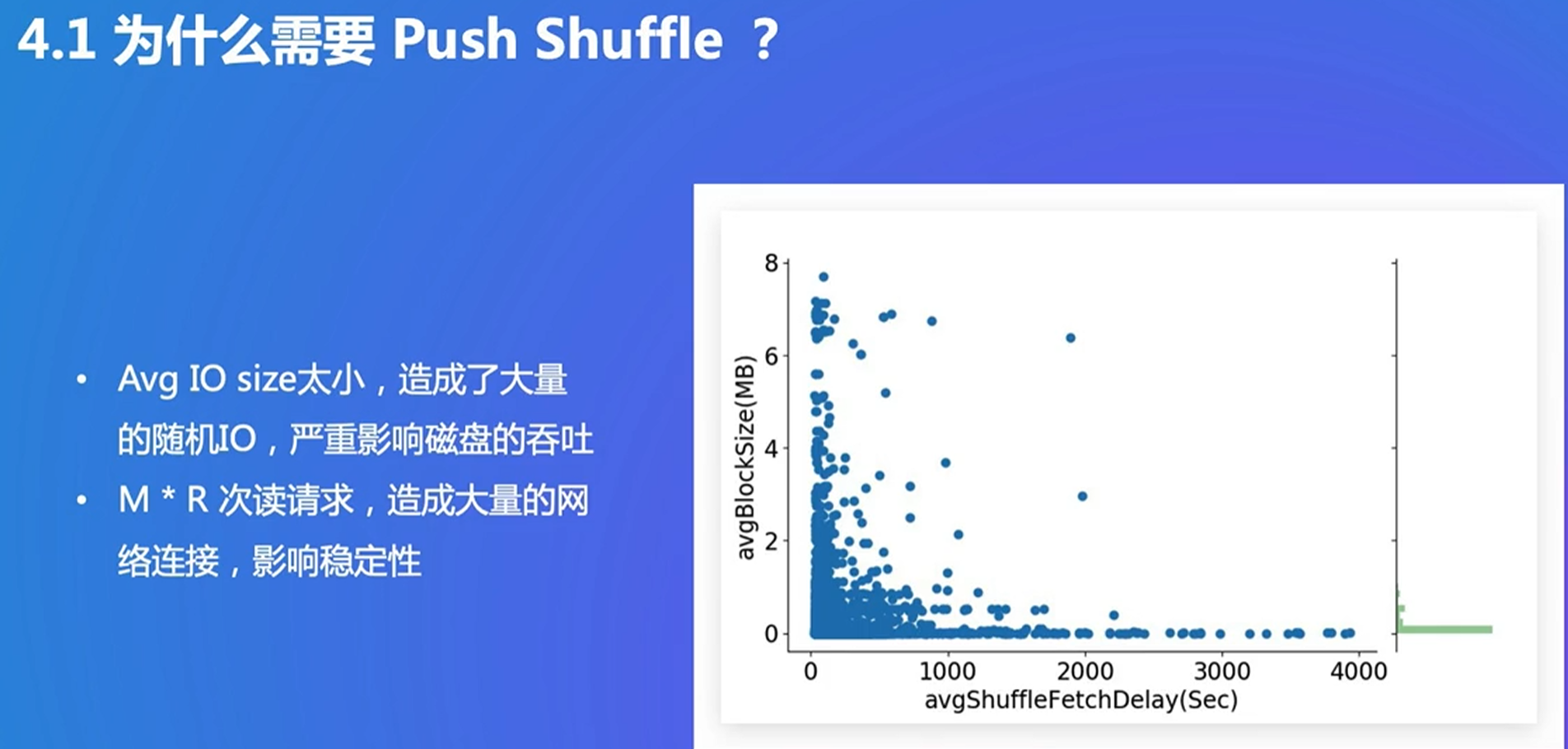




新的问题:数据丢失的成本变多了
自己进行数据备份


7. Presto架构原理与优化浅析
1. 大数据与 OLAP 的演进
不等价于,如何提取想要的数据
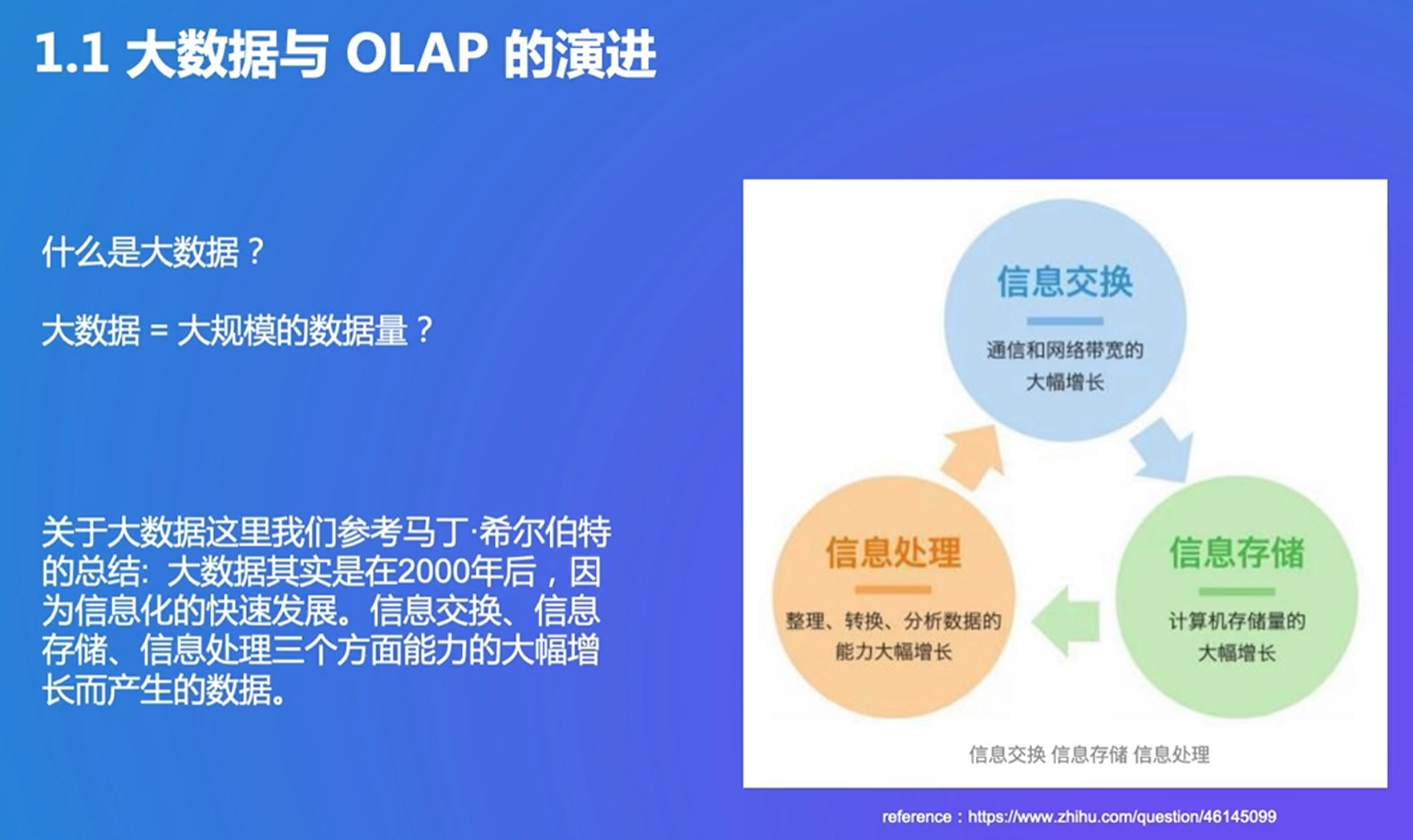

OLAP:多维分析

可以以时间为单位、分析某一类产品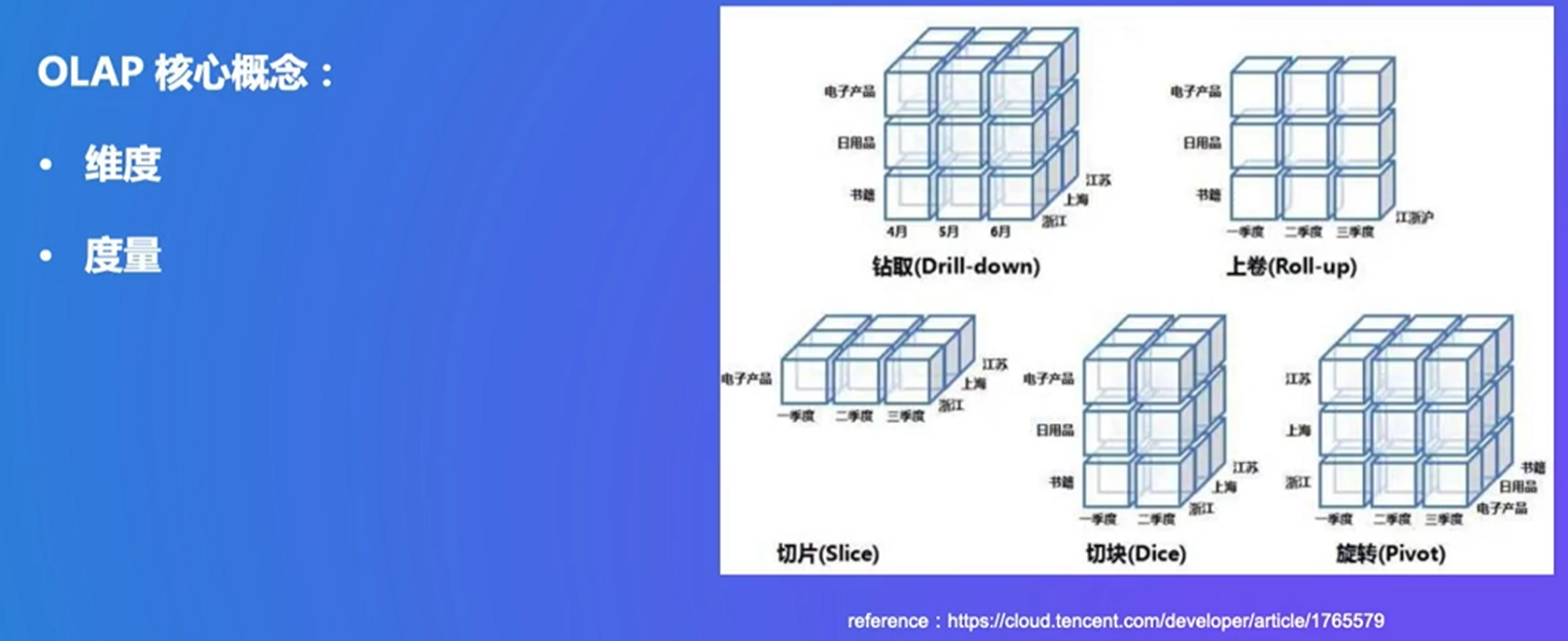




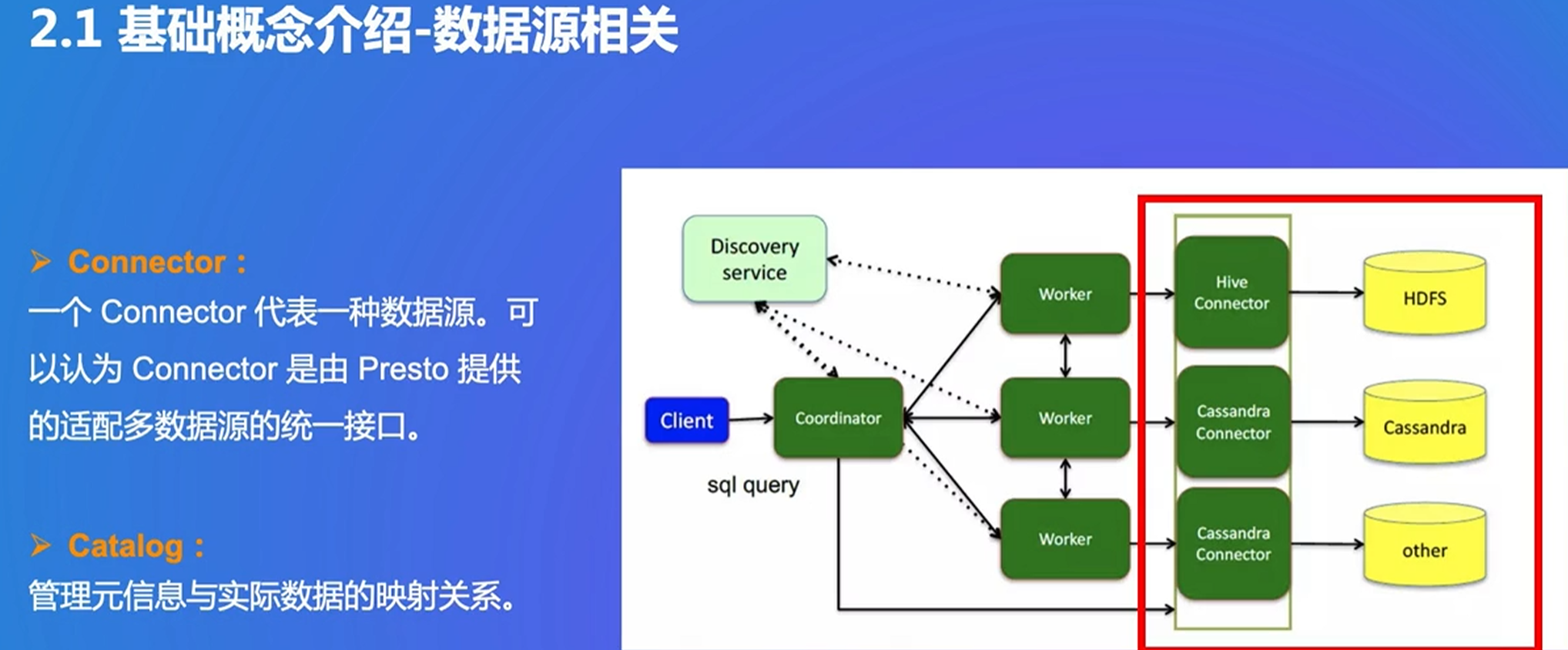
2. Presto 基本原理与概念
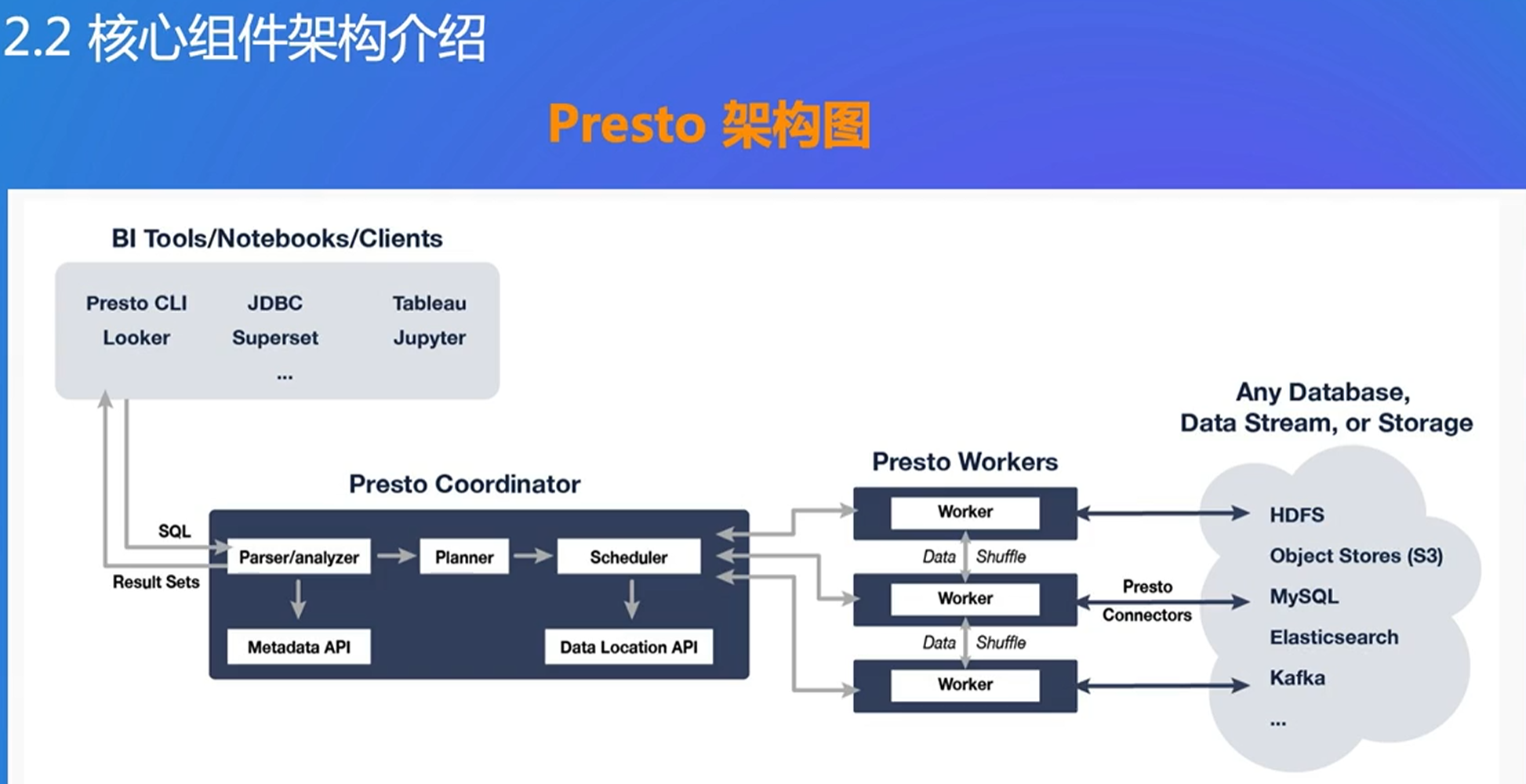
黄色:数据源
绿色:Presto的服务
蓝色:用户 根据需求最后会得到结果

多数据源引擎,每个connector是适配多数据源的接口,可以联邦查询
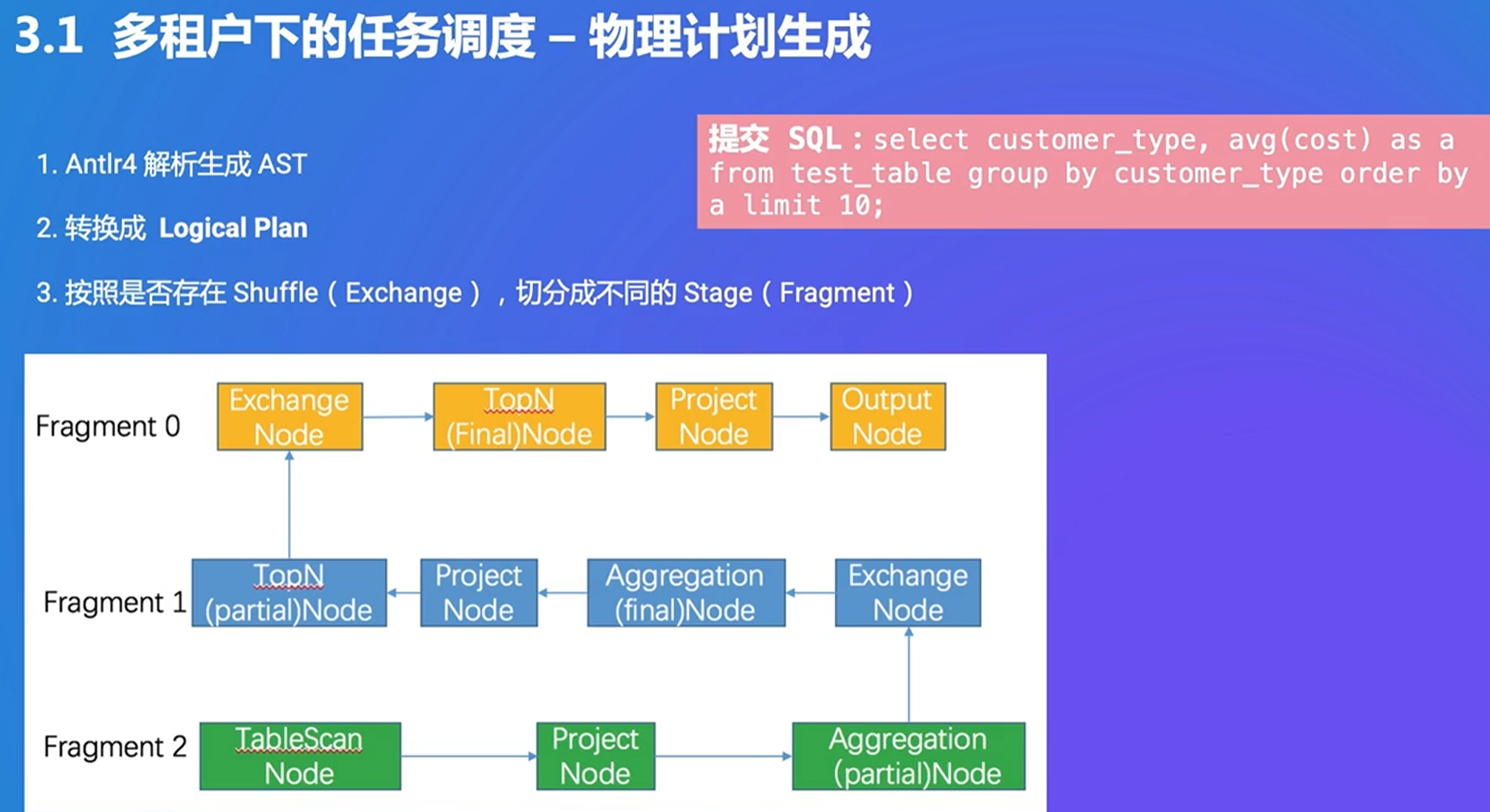
stage之间用shuffle来区分
pipeline根据算子拆分成不同的涵义

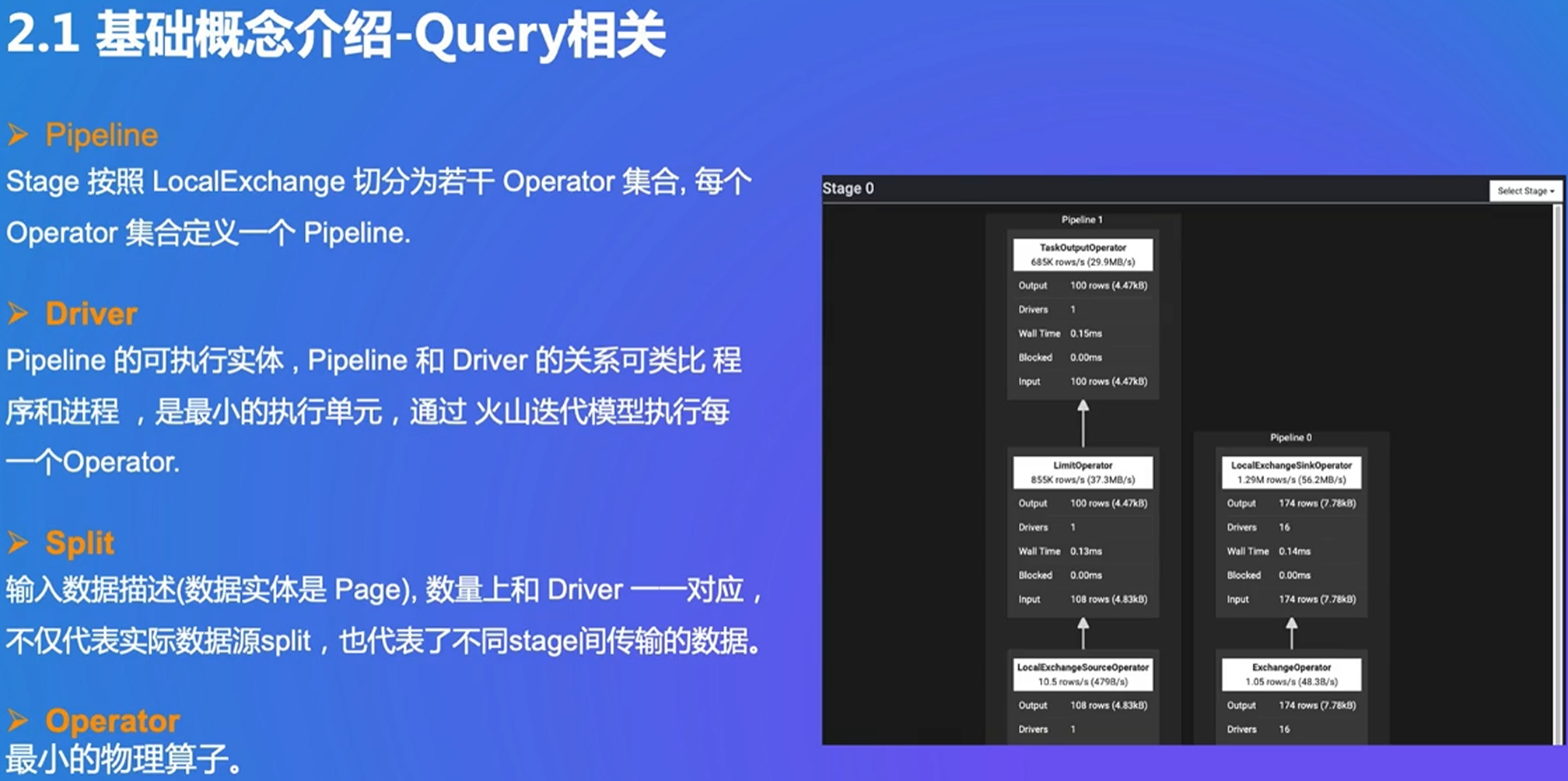
stage内部可以rehash,类似进程和线程的关系

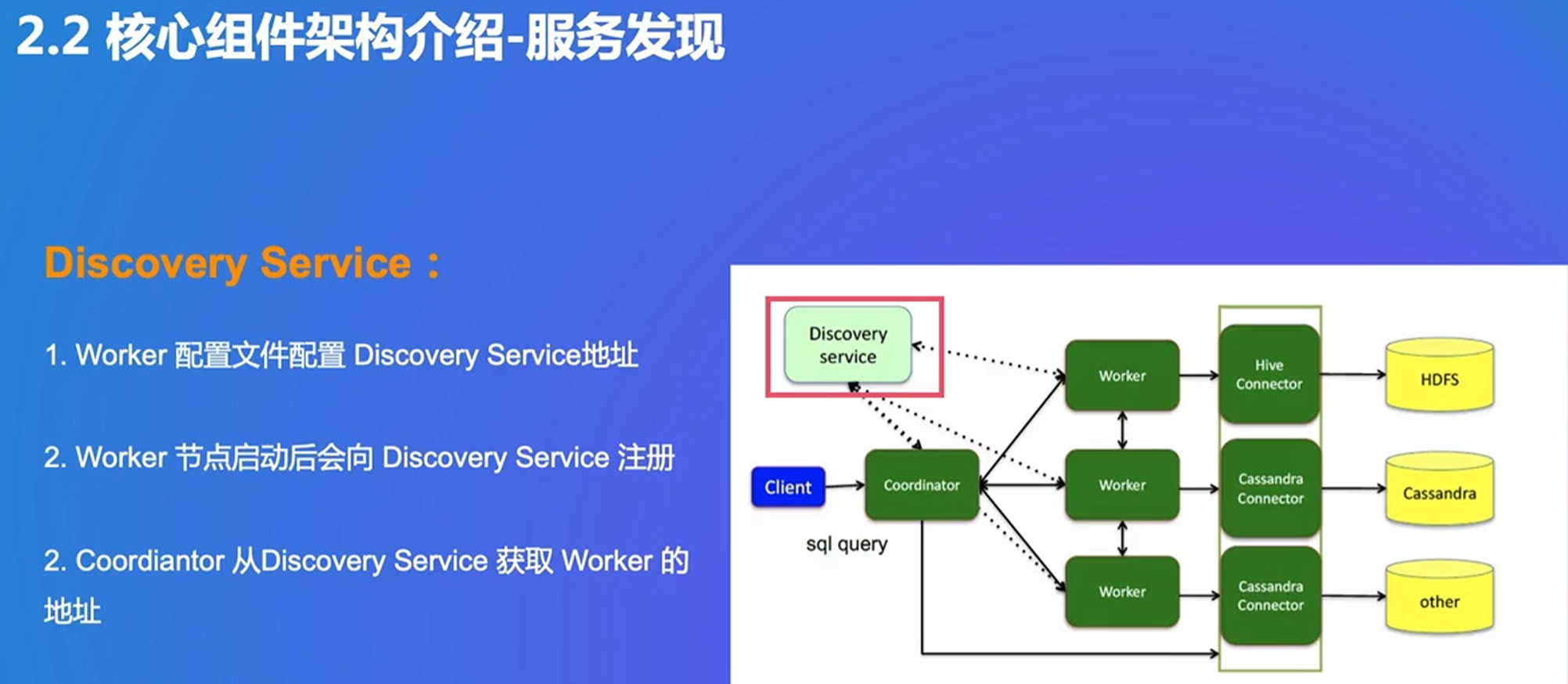
浅绿色负责桥接

SHUTDOWN:不是worker本身关闭了就关闭,属于想要关闭,本现在在跑的task尽量处理完,处理不完到达超时时间了也会结束。

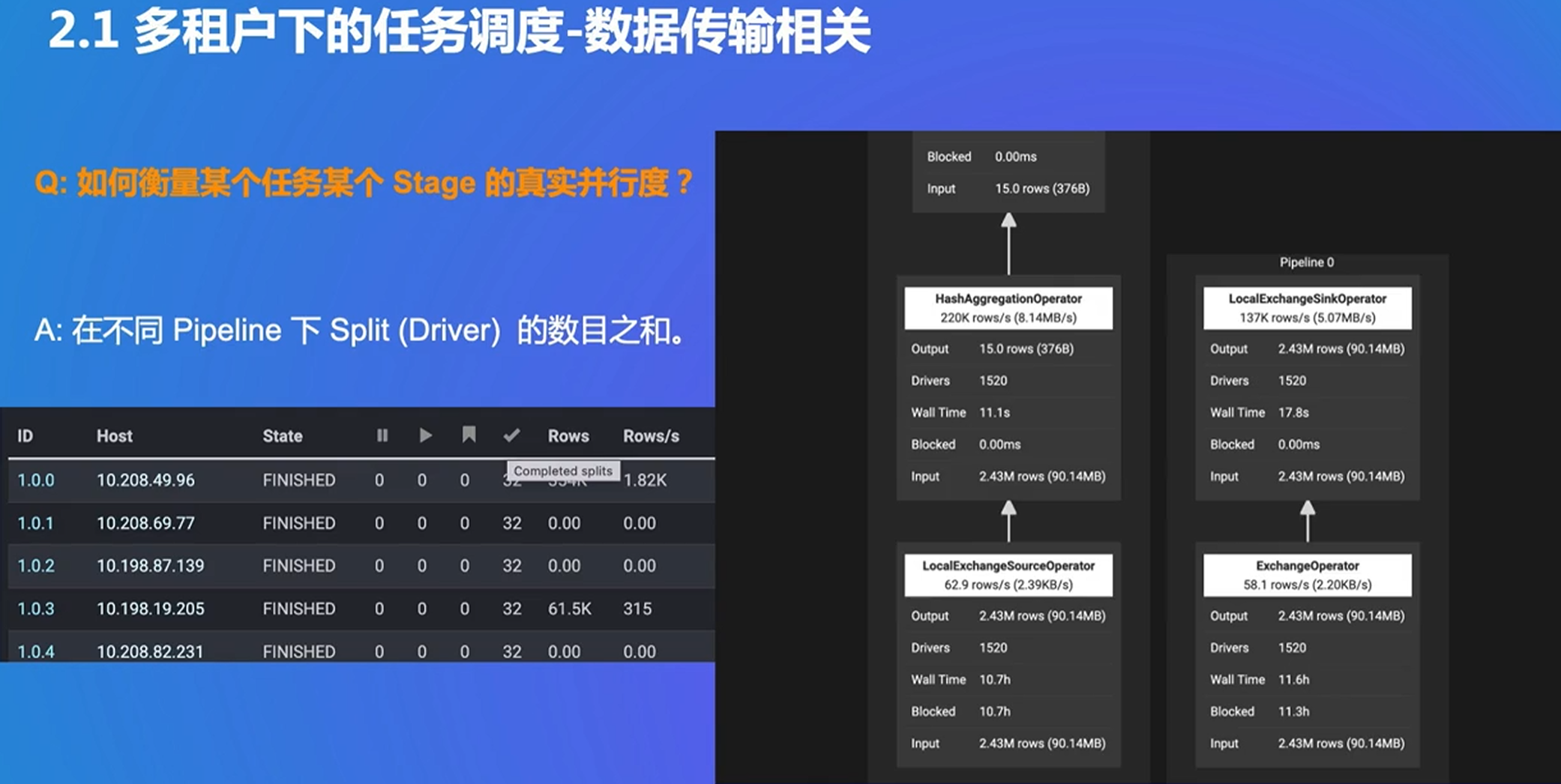
考虑到task下所有的pipeline,最后乘以worker数(因为一个worker调度很多task)

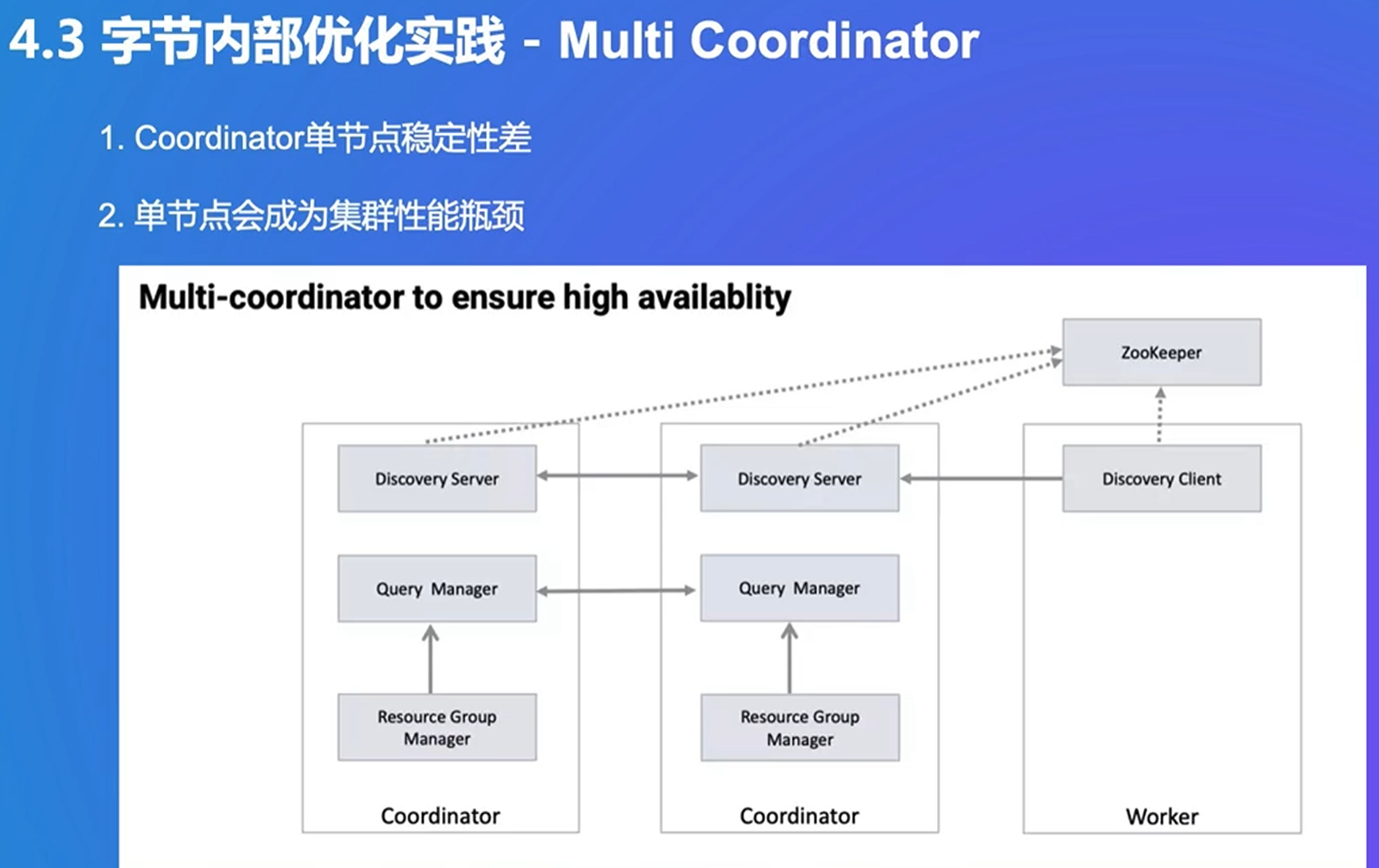
3. Presto 重要机制





默认同时调度,符合流式数据处理的特点



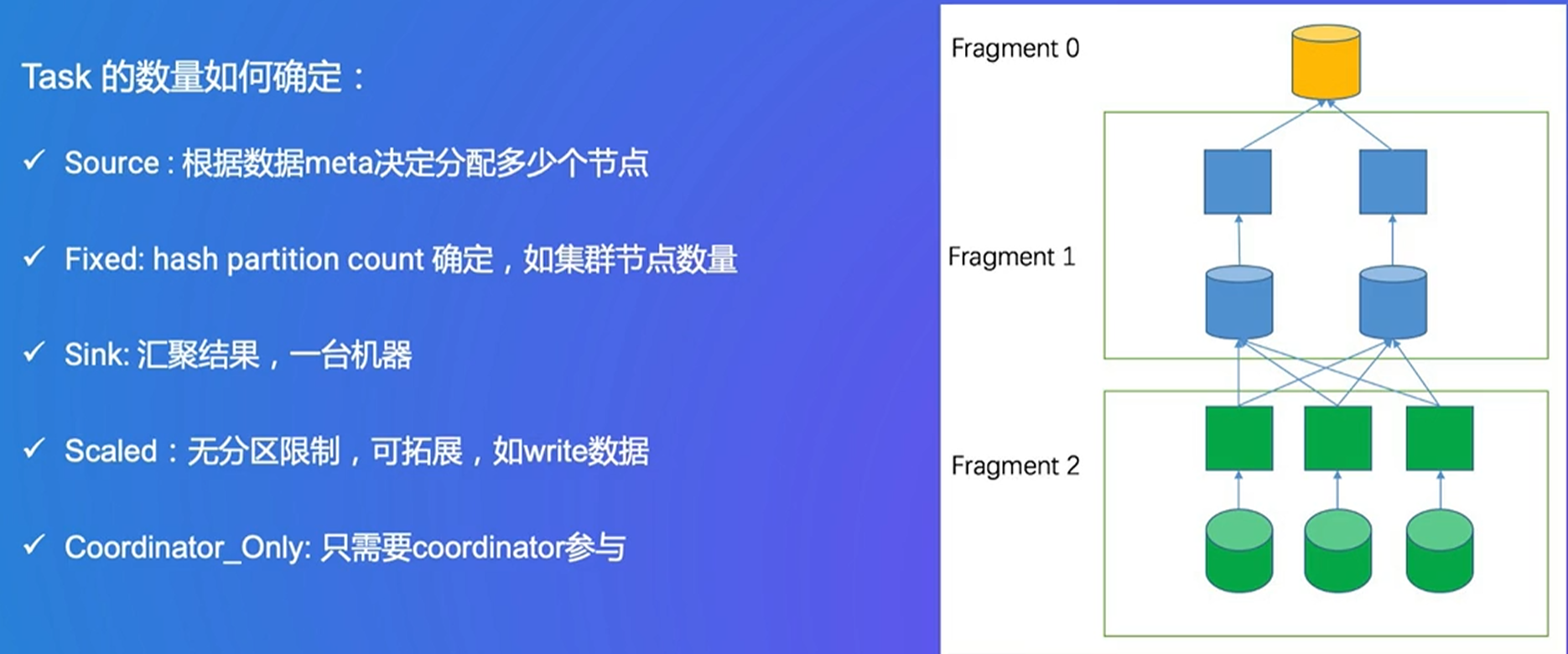







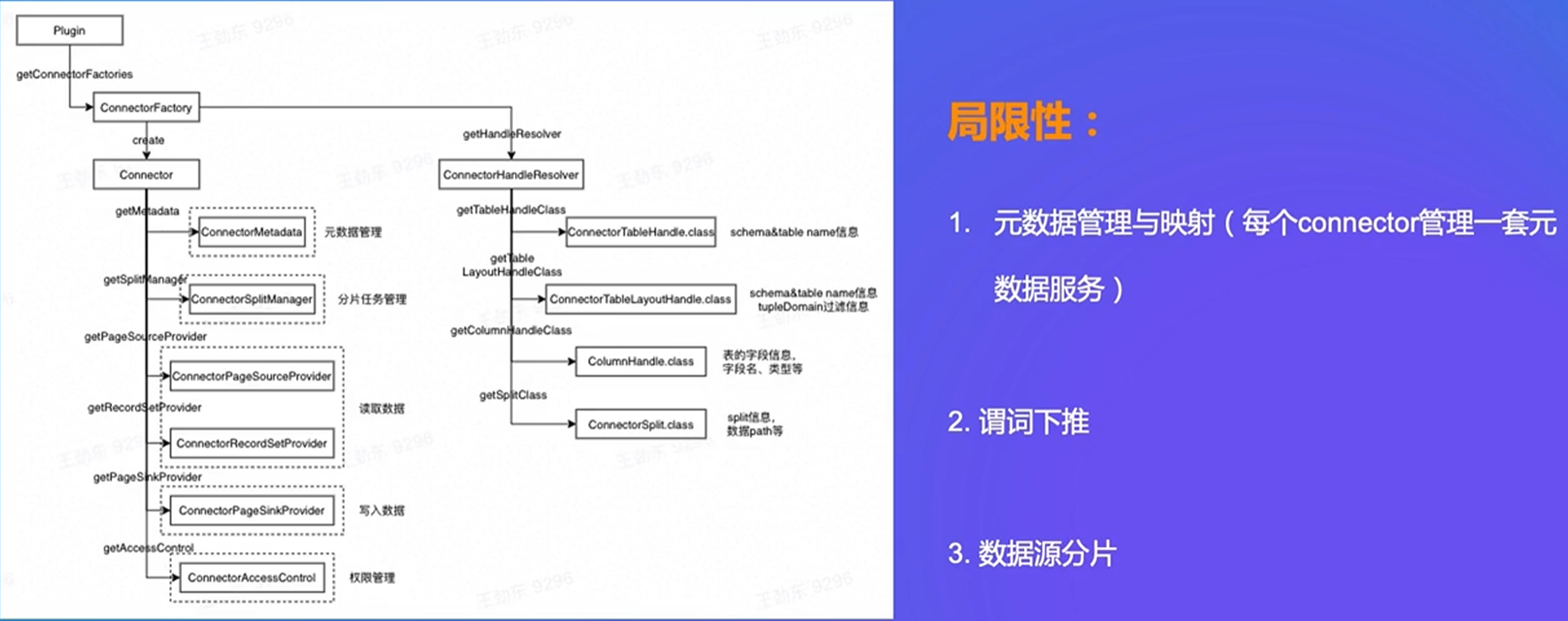

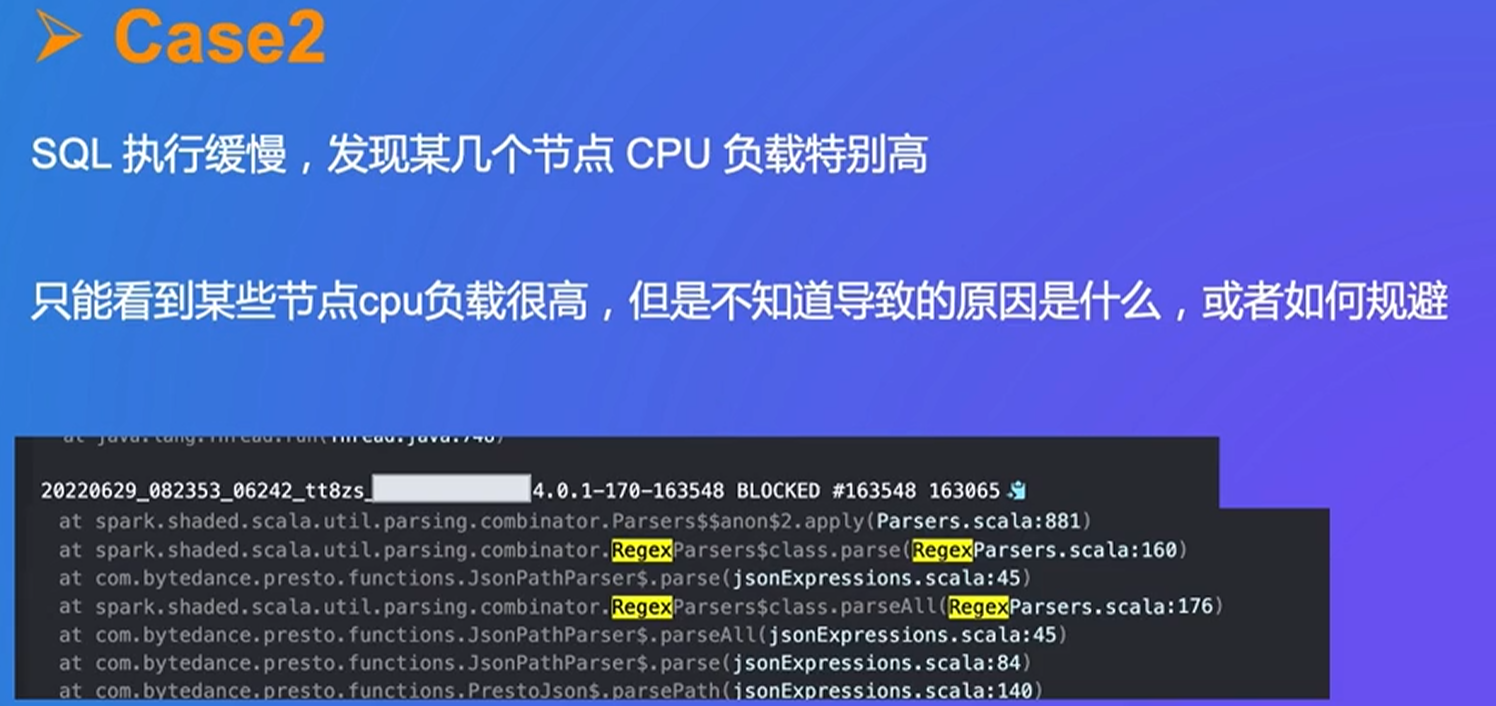
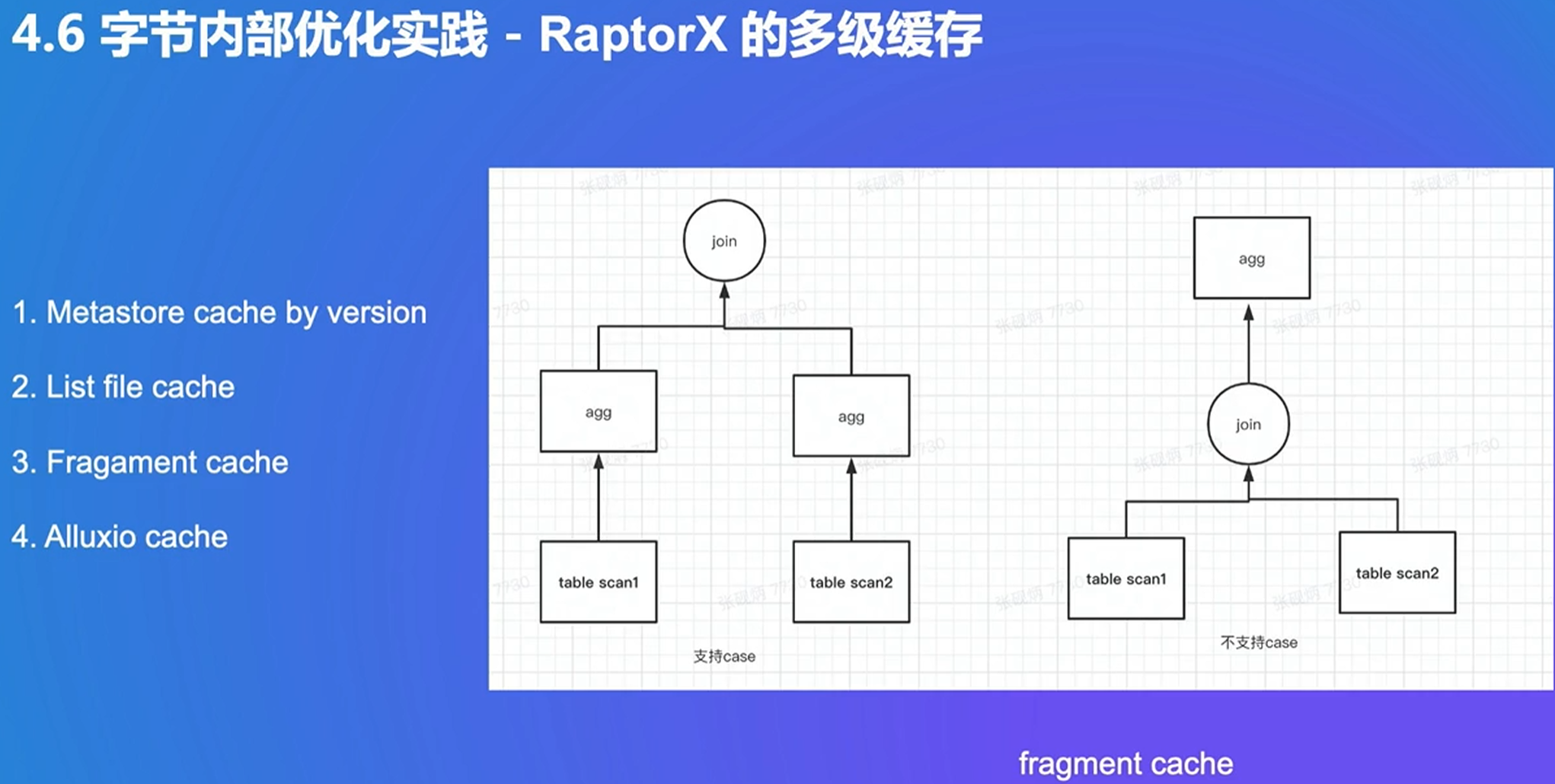
4. Presto 性能优化实战

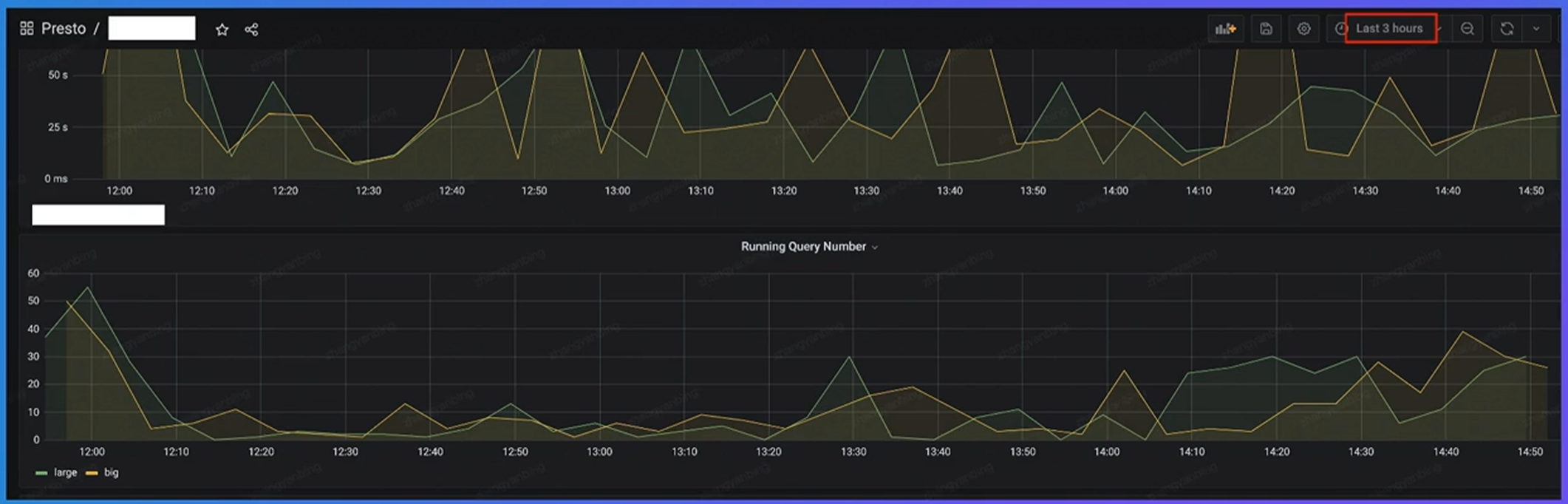
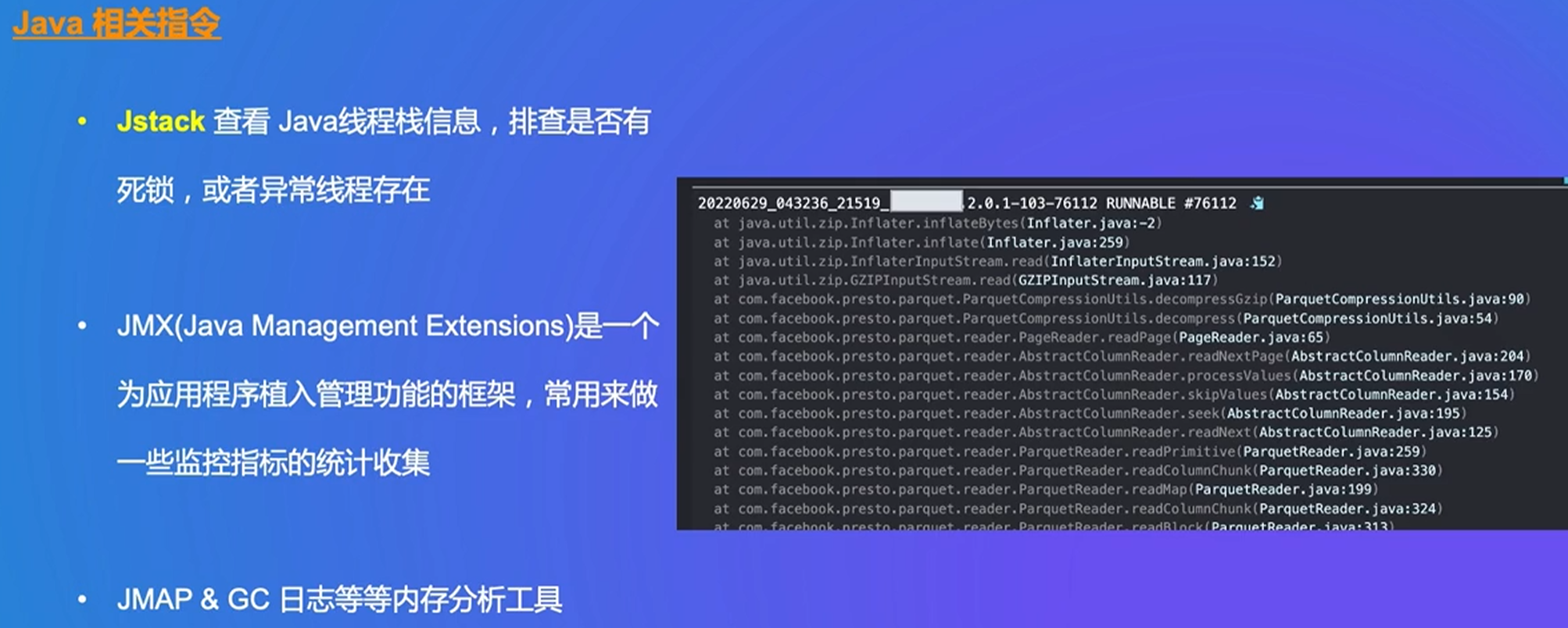
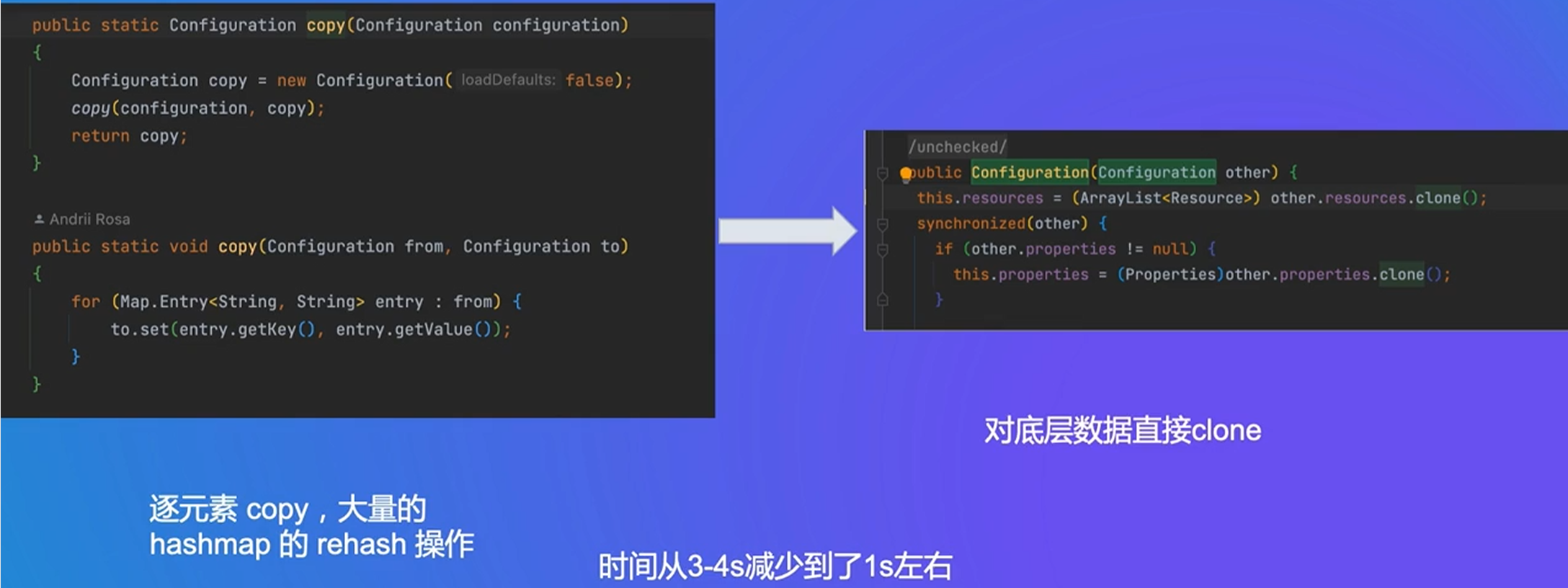
通过url可以直接查询task的状态

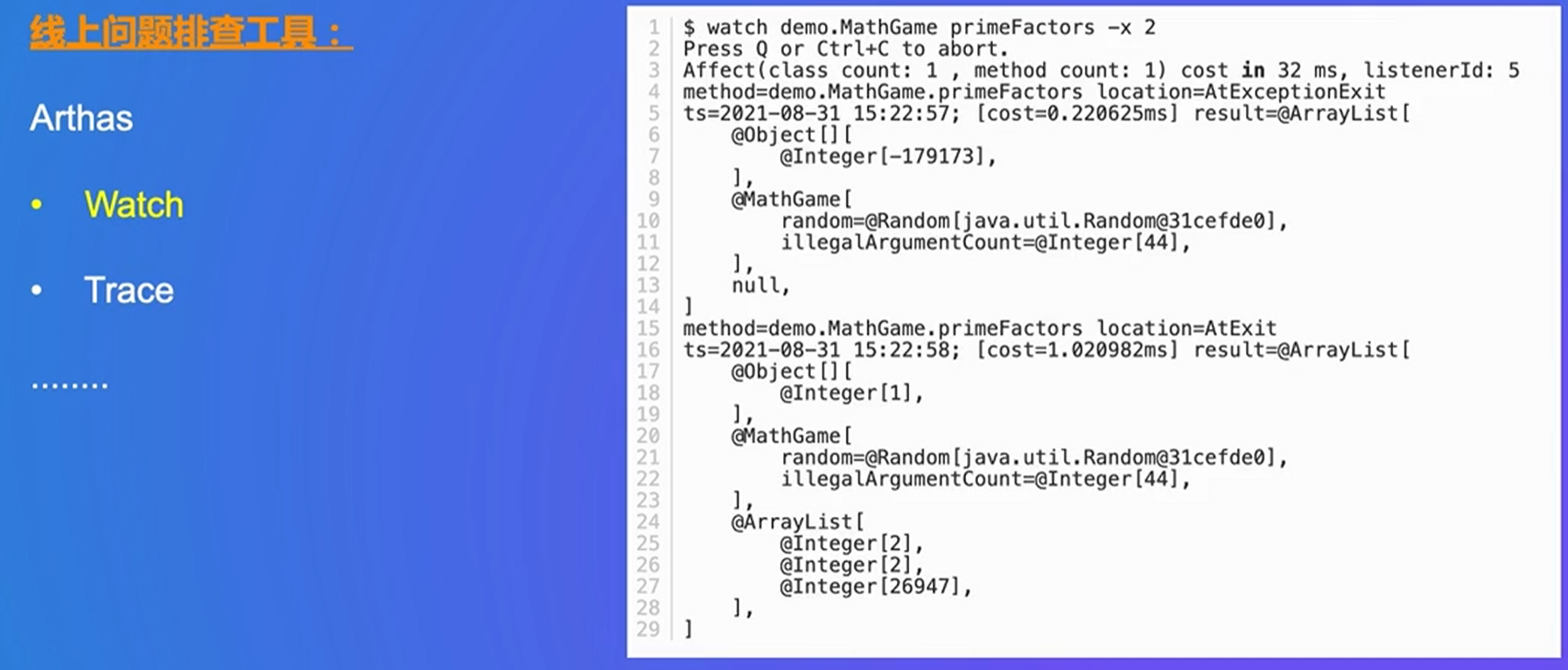




把配置文件copy,会产生很多rehash